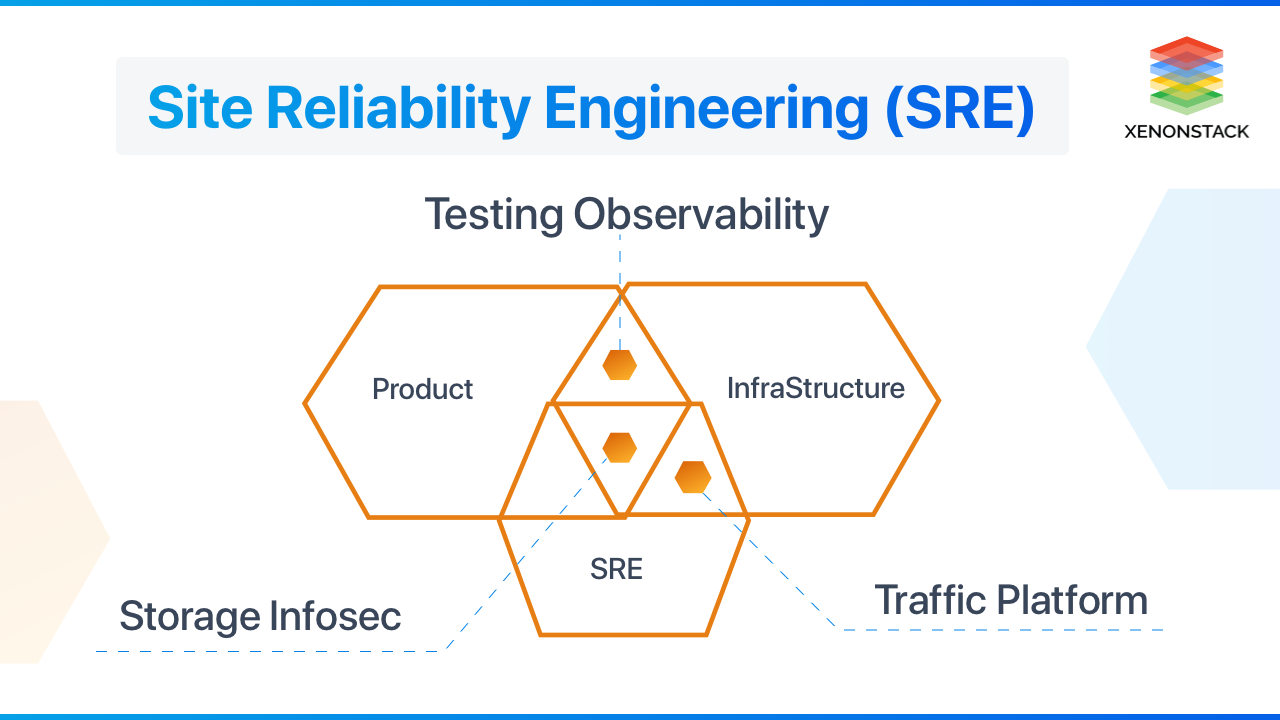
What is Site Reliability Engineering?
Site Reliability Engineering (SRE) is a practice that applies both software development skills and mindset to IT operations. SRE involves using software engineering techniques that include algorithms, data structures, performance, and programming languages to achieve highly reliable web applications.
A discipline that includes aspects of software engineering and implements them to IT operation obstacles. Click to explore about, Site Reliability Engineering | Approach to Achieve DevOps Objectives
Site Reliability Engineering uses software engineering techniques to ensure the production environment's stability and availability, simultaneously adding new features and operational improvements needed. The SRE Team comprises of software engineers known as sysadmin, which substitutes automation for human labor and focuses specifically on system reliability.
What are the key Site Reliability Engineering Skills?
The type of skills required will differ from organization to organization. It is widely based on the type of application a particular organization uses and how and where it is deployed and monitored. The other essential skills for SREs are to be more focused on application Monitoring and Diagnostics. Apart from the specific technical skills that depend on the organization's practices, below are some non-technical and some basic technical skills one should look for in Site Reliability Engineering.
Non-Technical Skills
- Problem-Solving
- Teamwork
- Work well under pressure and solve problems.
- Translating the technical into business language.
- Have excellent written and verbal communication.
Fundamental Technical Skills
- Know version control.
- Knowledge of Linux (most preferably).
- Automate things over the manual work.
- CI/CD Knowledge.
- Knows how to troubleshoot.
Opencast for automated video capturing, processing, managing, and distributing. Click to explore about, Best Practises and Solutions for SRE Team
How Site Reliability Engineering Works?
A Site Reliability Team provides availability, performance, effectiveness, emergency response, and service monitoring. In short, Site Reliability Engineering is accountable for all those things that make their services up and reliable for their user. So to fulfill all these, the SREs work according to the following principles, or we can say it is the basis for the foundation of Site Reliability Engineering:
- Embracing Risk
- Service Level Objectives
- Eliminating Toil
- Monitoring Distributed Systems
- The Automation
- Release Engineering
- Simplicity
Service-Level Objective (SLO)
Set a specific numerical target for system availability. This particular numerical value is termed as Service-Level Objective (SLO), i.e., it defines a target level for your service's reliability. More reliable service will cost more for operation; hence SLA should be set carefully.
Service-Level Agreement (SLA)
An SLA involves a response to a service that it's available typically. SLO meets a certain level over a certain period, and if it fails to provide what's in SLO, then some fine will be given as a refund. Define SLA’s availability SLO; be more careful about which queries count as genuine.
Service-Level Indicator (SLI)
It's an indicator of the level of services provided, and to know whether the system ran under SLO in the past or not, look at the SLI to get the service availability rate. If it goes below the defined SLO, then there is a problem, and it must be solved (someone needs to make the system more available in some way to solve the problem).
The process of creating automated workflows in the runbook with scripts, commands, tools, and API. Click to explore about our, Automation Runbook for Site Reliability Engineering
What are the key principles of Site Reliability Engineering (SRE)?
-
Recruit Programmers: Hire skilled coders for SRE roles, focusing on automation to handle system growth rather than linearly expanding the engineering team.
-
Treat SREs as Developers: SREs and developers come from the same pool, working interchangeably to improve system stability rather than just adding functionality.
-
Dev Team Involvement: Developers handle about 5% of operations work, staying informed about system changes and taking full-time support responsibility if their features cause instability.
-
Limit SRE Operational Load: SREs spend at least 50% of their time automating and improving system reliability, with a cap on the number of issues they can address during a shift.
-
On-Call Team Size: On-call teams should have a minimum of 8 engineers per site, managing no more than two incidents per shift to prevent burnout.
-
Postmortems for Improvement: Focus on process and technology in postmortems, aiming for continuous improvement to avoid repeating the same issues.
-
Service Level Objectives (SLOs): Each service should have defined SLOs and measurable metrics that guide actions and set limits on allowable unavailability.
-
Launch Criteria Based on SLO Finances: Base system changes on SLO budgets to ensure stability; avoid introducing changes when nearing the budget limit to maintain service quality and customer satisfaction.
Why Site Reliability Engineering Matters?
A sysadmin is responsible for the configuration, keeping the system up, and reliably complex computing systems. Do all deployments, monitor services, and respond if something goes wrong.
According to Google's Site Reliability Engineering Book, the traditional approach caused gaps and conflict between developers and sysadmins due to different skills. Developers suggest new features should be available to users as frequently as possible, whereas the sysadmins team members avoid breaking anything.
What are the important aspects of SRE?
Site reliability engineers collaborate with alternative engineers, product owners, and customers to return targets and measures. You recognize that action ought to be taken once you've set a system's period and accessibility. Below mentioned are some important aspects of it to ponder:
- This is often done through Observability, Service-Level Indicators (SLIs), and Service Level Objectives (SLOs).
- An engineer ought to have a holistic understanding of the systems because of the connections between the systems.
- Site reliability engineers have the task of guaranteeing the first discovery of issues to cut back the failure cost.
- Since it aims to resolve issues between groups, the expectation is that each of its groups and the development groups have a holistic read of libraries, front end, back end, storage, and alternative parts. And shared possession means anybody's team can't enviously own single parts.
How to adopt Site Reliability Engineering?
Google is the first to embrace Site Reliability Engineering's culture, but what works for Google may not work for all other organizations, which means the adaptation of Site Reliability Engineering in an organization depends on different factors such as Organization size, Technology used, culture, or other factors. To adopt Site Reliability Engineering, refer to the defined principles and practices that Google is practicing and match the established methods the organization follows.
Project Analysis
- Current Situation of Organization
- Challenges
- Capabilities
- Capability Gaps
Hiring Site Reliability Engineering team by Analysis
- It's up to the organizations, to hire the most efficient and only required members, based on the analysis.
Recommendations
- Which Site are Reliability Engineering principles most suitable for your situation?
- Site Reliability Engineering practices are feasible for the organization?
- Which can make the most significant difference, the soonest?
- How can someone best integrate Site Reliability Engineering into an organization’s culture?
Implementation
- How should one structure the Site Reliability Engineering teams?
- What skill gaps have you got, and what are the best ways to fill them?
- How can you bring the existing team up to speed with Site Reliability Engineering?
- What should you be looking for in new hires?
SRE team is responsible for resolving incidents, automating operational tasks, using the software to manage systems. Click to explore about, Managed SRE Challenges and Solutions
What are the Challenges of Site Reliability Engineering?
Site Reliability Engineering supports the business by automating tasks to eliminate inessential work and roles and reduce the overall cost by optimizing resources and improving mean time to repair. The key areas that Site Reliability Engineering focuses on are:Reliability
To maintain a high level of network and application available thus maintaining software system reliability.Monitoring
Implementing performance metrics and establishing benchmarks to monitor the systems.Alerting
Readily finding any problems and making sure that there is a closed-loop support process to resolve them.Infrastructure
To understand cloud infrastructure and physical infrastructure scalability and limitations.Application Engineering
Understanding all application necessities as well as testing and readiness needs.Debugging
Understanding the systems, log files, code, use case, and troubleshooting will debug as required.Security
Understanding common security problems and tracking and addressing vulnerabilities to make sure the systems are properly secured.Best Practices Documentation
Prescribing solutions, production support playbooks, and many more.Best Practice Training
Site Reliability Engineering best practices are done through production readiness reviews, blameless postmortem, technical talks, and tooling. There are alternative resource domains that overlap with the SRE's role, like DevOps, IT Service Management (ITSM), Agile Software Development Life Cycle (SDLC), and other organizational frameworks. SRE and DevOps/NetDevOps teams are interdependent. By providing monitoring solutions that address the needs of both, information is facilitated across teams so that collaborative troubleshooting results in problem resolution.A way to get insights into the whole infrastructure. It is essential for the operations team. Click to explore about, Observability Working Architecture and Benefits
What are the best practices of Site Reliability Engineering?
Site Reliability Engineering is concerned with speed, performance, security, capacity planning, software/hardware upgrades, and availability, which result in reliability, an aspect every organization is willing to achieve. SREs operate services with networked systems, operated for users, internal or external, and are eventually responsible for these services' health.
Successfully operating a service requires a wide range of activities such as developing monitoring capabilities, planning capacity, responding to incidents, ensuring the root causes of outages are addressed, and many more. Google has defined more than nine practices for Site Reliability Engineering. Given below is a brief categorization of these practices for better understanding.
Controlling Overload Operation
Hire coders as the primary duty of an SRE is to write code. About 5% of the ops work should go to the dev team, plus all overflow. The aim is to cap the SRE-operational load at 50% (usually 30%). The on-call team has a minimum of eight engineers for one location, handling a maximum of 2 events per shift.
SLA-Driven Operation Monitoring
- Have an SLA for your service; it may vary for different services.
- Measure and report the performance against SLA.
- Use error budgets and get launches on them.
Ways to Handle Incident/Blackout Smoothly?
- Do Postmortems for every event.
- Postmortems cannot be blamed, so focus on process and technology and not on people.
- Aim for a maximum of 2 events per on-call shift.
Management/Budget Policies
- Hire your SREs and your developers from the same staffing pool and treat them all as developers.
- To take care of SLA, SLI, and SLO very carefully and logically to define all the values and agreements.
Some other SRE Best Practices Include:
- Participating in and improving the whole lifecycle of services from inception and design through deployment, operation, and refinement.
- To support services before they go live, which can be done through activities like system design consulting, developing software platforms and frameworks, capacity planning, and launch reviews.
- Maintaining services once they’re live by measuring and monitoring availability, latency, and overall system health.
- Scaling systems sustainably can be done through mechanisms such as automation.
- Evolve systems by pushing for changes that will help to improve reliability and velocity.
- By doing sustainable incident response and blameless postmortems.
SRE vs DevOps
SRE shares many governing concepts with DevOps. Both domains depend on the culture of sharing, metrics, and automation. It helps a corporation achieve the appropriate level of reliability in its systems, services, and products.
Indeed. Both Site Reliability Engineering and DevOps are methodologies addressing organizations' desires for production operation management. However, the variations between the 2 doctrines are quite significant.
- Site Reliability Engineering is a lot assured in keeping up a stable production setting and pushing for speedy changes and computer code updates. Not like the DevOps team, it additionally thrives on a stable production setting. However, one of the team's goals is to boost performance and operational potency.
- DevOps Culture is all concerning the "What" must be done. Site Reliability Engineering talks concerning "How" this could be done. It's concerning increasing the theoretical half to economic advancement, with the correct work strategies, tools, etc. It's conjointly concerning sharing the responsibility between everybody and obtaining everybody in synchronizing with constant goal and vision.
Whereas DevOps raises issues and dispatches them to Dev to unravel, the approach seeks out issues and solves a number of them themselves.
Learn more about site reliability engineering vs devops and their differences below:
| Site Reliability Engineering (SRE) | DevOps |
| 1. Focus on creating an ultra-scalable and highly reliable software system | 1. Focus is on automated deployment process on production and staging environment. |
| 2. Site Reliability Engineering is one of the engineering specializations. | 2. DevOps is a role. |
| 3. It encourages quick movement by reducing the cost of failure. | 3. DevOps implements gradual change. |
| 4. Post Mortems | 4. Environment builds |
| 5. Monitoring, Alerting, Events | 5. Configures management |
| 6. Capacity planning | 6. Infrastructure as code |
| 7. RELIABILITY is the primary focus. | 7. DELIVERY SPEED is the primary focus. |
The Best Site Reliability Engineering Tools
Understanding the SRE approach is not written in stone, whether it's an organization implementing or providing site reliability engineering services. Organizations have to conceptualize working on SRE and adapt to the required tools accordingly.
Some SRE tools are mentioned below:
Site Reliability Engineering Benefits
Site Reliability Engineering aims to improve high-scale systems' reliability, which is done through automation and continuous integration and delivery. SRE's primary goal is to fill the gap between the developer teams and Sysadmin teams. When talking of SRE Benefits, we usually relate how it can benefit an enterprise.
Grab a Look below at what we think:
- It accomplishes customer expectations on the functionality and valuable life of Performance Monitoring Tools.
- Exposure to systems in staging and production, along with all technical teams.
- It lessens the foreseeable risks inherent to the performance of the tools and the health hazards.
- It increases the Reliability and Availability of the systems by reducing the failure rates and downtime.
- It prevents failures, avoids recurrences, and recovers quickly, and resets a failing system to reboot.
- It helps to achieve production goals quickly and more efficiently.
- It increases the marketing of products and guarantees.

Conclusion
Site Reliability Engineering needs special skills to succeed. There ought to be a sense of trust between the teams. Being responsible for SRE is more about taking ownership of production-related operations. It is a specific approach that focuses on IT operations. Want to adopt SRE culture in your project? Go ahead and train your team, follow the best practices, and trust the process. It is a myth that you will achieve 100% perfection. But you're going to make things better and get as close to perfection as you can.
- Discover more about Network Reliability Engineering (NRE)
- Explore How Generative AI Support DevOps and SRE Workflows.