What is Container Storage Interface(CSI)?
CSI stands for Container Storage Interface. It is an initiative to combine the storage interface of Container Orchestrator Systems(COS) such as Mesos, Kubernetes, Docker Swarm, etc. that combined with storage vendors like Ceph, Net App (Network Appliance Inc. is a hybrid cloud data services and data management Company.), etc. This means Implementing a single CSI for storage vendors, which definitely with all COS.Trigger actions based on the analyzed data, and store the data at Cloud-scale. Click to explore about, Real Time Data Analytics Infrastructure on Mesos
Kubernetes 1.9 introduces an alpha implementation of the Container Storage Interface, which makes installing a new volume plugins easy. Before Kubernetes 1.9, we need to add to the core Kubernetes codebase for third-party storage providers to develop solutions, but after Kubernetes 1.9 third-party storage providers to develop solutions without the need of adding core Kubernetes codebase. At present, the CSI 0.2 version introduced in March 2018.
Basic Terminologies related to Container Storage Interface (CSI)
- COS - Container Orchestrator Systems is all about managing the life cycle of Containers, especially in large dynamic environments. Software teams use Container Orchestrator to control and automate many tasks.
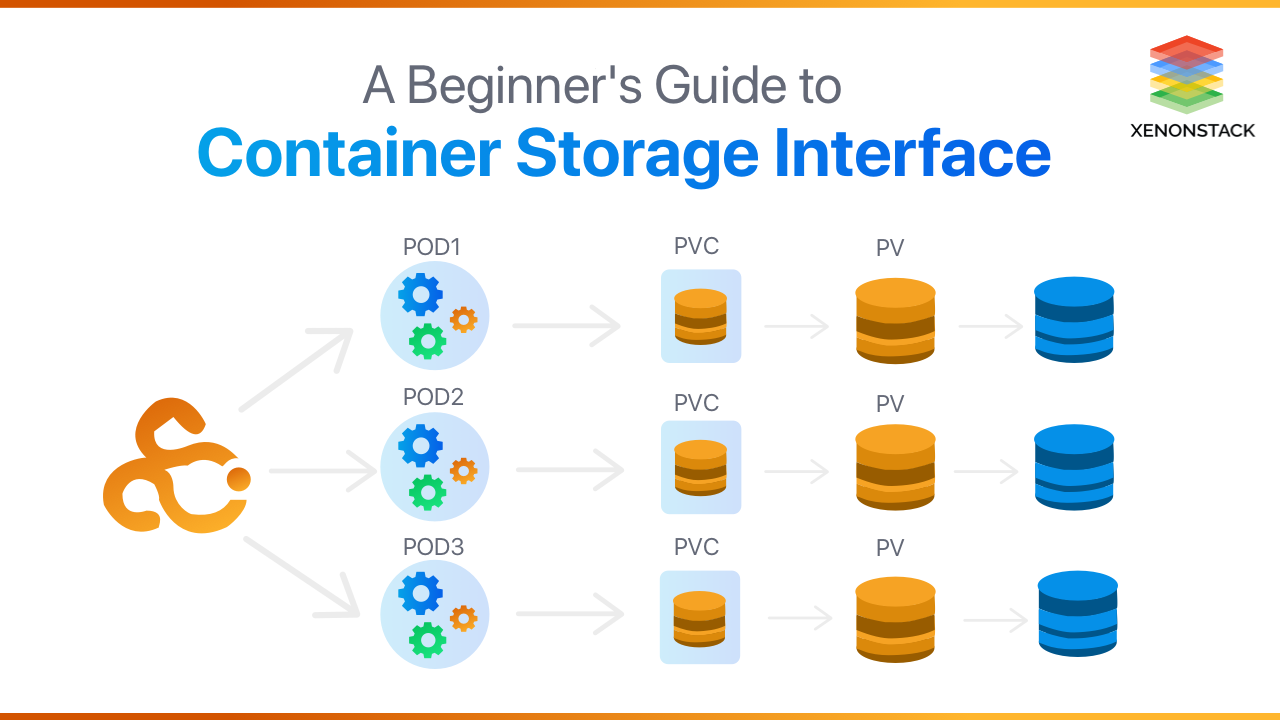
- Volume - A unit of space that will be made available inside of managed containers via the CSI.
- Node - A host where a workload will be running.
- Workload - The atomic unit of “work” anticipated by a COS.
- Plugin - Plugin points to a service that exposes gRPC endpoints.
- gRPC - It is an open-source Remote Procedure Call System initially developed at Google.
- SP - Storage Provider, the vender of CSI plugin implementation.
Container Storage Interface Goals
- Interoperability - The storage vendor can build once a plugin, and that plugin can be used by all the CO that support CSI.
- Vendor-neutral - Any CO and storage provider should not terminate it.
- Focus on specification
- Control plane only
A method of observing, reviewing, and managing the workflow in a cloud-based infrastructure. Click to explore about, Cloud Management and Monitoring Tools
Before Container Storage Interface (CSI)
Before CSI was introduced, different COS have their interface that the storage vendor has to implement so that the COS can talk to that SP during the life cycle of volume. The First release of the CSI version is 0.1 was introduced in December 2017. In the case of Kubernetes, volume plugins were serving the storage need for container workload. The first problem was in Kubernetes itself, you need to write a driver as a source vendor and put it inside the Kubernetes code, and what that meant is that as a storage vendor you could not one fix any issues, which you have to wait for Kubernetes release you are bound for release process of Kubernetes. What happens is that each one of this COS would then design their method said: “This is our API.” So how as a storage product as a storage system, you have to write drivers for three different systems ( Mesos, Kubernetes, Docker Swarm). Developers who developed plugin forced to make plugin source code available.
Object Storage - Object storage also called object-based storage. Which describe an approach to addressing and manipulating discrete unit of storage called objects like files objects contain data, but unlike files, objects are not organized in a hierarchy that means every object exists at the same level in a flat address space called the storage pool and one object can not be placed inside another object. An object is designed for unstructured data such as media, documents, logs, backup, etc. The most popular cloud object storage is AWS S3. Useful for automating and streamlining data storage. Use cases -
- Storage for unstructured data like music, image, etc.
- Storage for backup files, log files.
- Hybrid cloud storage.
- Disaster Recovery.
Benefits of object storage
- Scalability: Adding data forever, there is no limit. Security and compliance
- Flexible management
- Efficiency
Cloud Governance is a set of rules. It applies specific policies or principles to the use of cloud computing services. Click to explore about, Cloud Governance Challenges
Drawbacks - They are designed to read and write entire files, not for a small piece of files. It can not guarantee that each request will always get the latest version of the file that means if any application updates, its not necessary that all the locations where application installed get notification regarding the update.
Block Storage - This kind of storage system is usually located close to the server in the same data center, and it organizes data in separate volumes, accessed by one or very few servers simultaneously. The volume has the layout of local hard-disks, presented in the form of sectors and tracks. Most common access protocols are FC and iSCSI, and all of the communication happens on a dedicated Storage area network based on lossless Ethernet or FC equipment. This type of storage is perfect for databases and virtual machines, and more in general for all those workloads that require low latency and high IOPS. Unfortunately, Block storage systems are also characterized by a very high cost per gigabyte, and most of the implementations in the market still rely on scale-up dual-controller designs, with a total capacity that can hardly reach the petabyte level, while maintaining a right performance consistency. Use cases -
- Structured database storage.
- Application using server-side processing.
- CLI based interface
- Heavyweight
- Lack of idempotency on APIs
- In-tree interface
- Identity Services
- Controller Services
- Node Services
{
rpc GetPluginInfo ( … ) …
rpc GetPluginCapabilities ( … ) …
rpc Probe ( … ) …
}
- GetPluginInfo() - This method returns the name and version of the plugin.
- GetPluginCapabilities() - It returns the capabilities of the plugin. If this method returns the capability of the plugin, then CO calls the Controller method.
- Probe() - This is called by CO to check plugin is running or not.
{
rpc CreateVolume ( … ) …
rpc DeleteVolume ( …) …
rpc ControllerPublishVolume ( … ) …
rpc ControllerUnpublishVolume ( … ) …
rpc ValidateVolumeCapabilities ( … ) …
rpc ListVolumes ( … ) …
rpc GetCapacity ( … ) …
rpc ControllerGetCapabilities ( … ) …
}
- CreateVolume() - This method takes an argument in terms of createvolumerequest and returns createvolumeresponse.
- DeleteVolume() - This method deletes a volume that was previously created.
- ControllerPublishVolume() - This method is used to make a volume available on some required node.
- ControllerUnpublishVolume() - This method is used to make a volume unavailable on a specific node.
- ValidateVolumeCapabilities() - This method is used to return the capabilities of the volume.
- ListVolumes() - This method is used to return a list of all the available volumes.
- GetCapacity() - This method returns the capacity of the total available storage pool. And this method is used when we have limited storage capacity.
- ControllerGetCapabilities() - This method returns the capabilities of the Controller plugin. Node Services: Node Services are responsible for controlling volume action in the node.
{
rpc NodeStageVolume ( … ) …
rpc NodeUnstageVolume ( … ) …
rpc NodePublishVolume ( … ) …
rpc NodeUnpublishVolume ( … ) …
rpc NodeGetId ( … ) …
rpc NodeGetCapabilities ( … ) …
}
- NodeUnstageVolume() - This method is used to unmount the volume from the staging path.
- NodePublishVolume() - This method is used to mount the volume from staging to the target path.
- NodeUnpublishVolume() - This method is used to unmount the volume from the target path.
- NodeGetId() - This method returns a unique ID of the node on which this plugin is running.
- NodeGetCapabilities() - This method returns the capabilities of the node.

Volume Life Cycle Container Orchestrator
Initially, the volume is not created CO (Container Orchestrator) will dynamically provision the amount by using CreateVolume and now the amount is in create state and then before the size can be used by a container on a node the CO will call ControllerPublishVolume to make an amount available on some required node. Once the ControllerPublish is successful, the CO calls the NodeStageVolume, which the operation for each volume on a node and then calls NodePublishVolume for each part.A Holistic Strategy
To Learn more about Provisioning and Deployment of Containers, Configuration of an application and Allocation of resources between Containers, we advise taking the subsequent steps -- Read the Guide, Kubernetes Architecture and its Components
- Read more about Best Overview of Building Serverless Applications on AWS
- Contact Us for Kubernetes Solutions


