
Overview of Persistent Storage
Persistent Storage is a critical part in order to run stateful containers. Kubernetes is an open source system for automating deployment and management of containerized applications. There are a lot of options available for storage. In this blog, we are going to discuss most widely used storage which can use on on-premises or in a cloud-like GlusterFS, CephFS, Ceph RBD, OpenEBS, NFS, GCE Persistent Storage, AWS EBS, NFS & Azure Disk.an open source distributed object storage server written in Go, designed for Private Cloud infrastructure providing S3 storage functionality. Click to explore about, Minio Distributed Object Storage Architecture and Performance
Why Persistent Storage Solutions are important?
To follow this guide you need -- Kubernetes
- Kubectl
- DockerFile
- Container Registry
- Storage technologies that will be used -
- OpenEBS
- CephFS
- GlusterFS
- AWS EBS
- Azure Disk
- GCE persistent storage
- CephRBD
Kubernetes
Kubernetes is one of the best open-source orchestration platforms for deployment, autoscaling and management of containerized applications.Kubectl
Kubectl is a command line utility used to manage kubernetes clusters either remotely or locally. To configure kubectl use this link.Container Registry
Container Registry is the repository where we store and distribute docker images. There are several repositories available online we have DockerHub, Google Cloud,Microsoft Azure, and AWS Elastic Container Registry (ECR). Container storage is ephemeral, meaning all the data in the container is removed when it crashes or restarted. Persistent storage is necessary for stateful containers in order to run applications like MySQL, Apache, PostgreSQL etc. so that we don’t lose our data when a container stops.Running Containers at any real-world scale requires container orchestration, and scheduling platform like Docker Swarm, Apache Mesos, and AWS ECS. Click to explore about, Laravel Docker Application Development
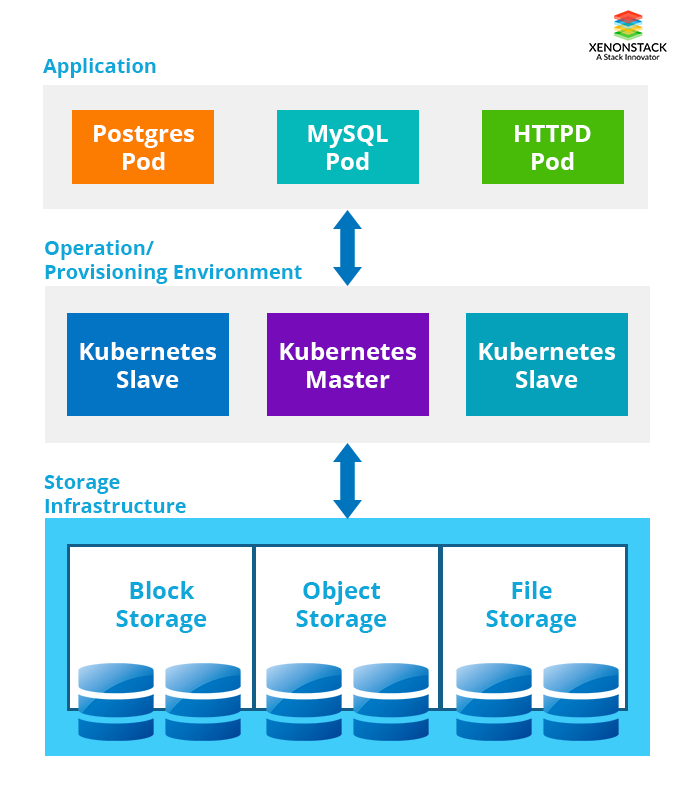
What are the 3 types of Storage?
- Block Storage: It is most commonly used storage and is very flexible. Block storage stores chunks of data in blocks. A block is only identified by its address. It is mostly used for databases because of its performance.
- File Storage: It stores data as files, each file is referenced by a filename and has attributes associated with it. NFS is the most commonly used file systems. We can use file storage where we want to share data with multiple containers.
- Object Storage: Object storage is different from file storage and block storage. In object storage data is stored as an object and is referenced by object ID. It is massively scalable and provides more flexibility than block storage but performance is slower than block storage. Most commonly used object storage are Amazon S3, Swift and Ceph Object Storage.
What are the 7 Emerging Storage Technologies?
The below highlighted are the 7 Emerging Storage Technologies:
OpenEBS Container Storage
OpenEBS is a pure container based storage platform available for Kubernetes. Using OpenEBS, we can easily use persistent storage for stateful containers and the process of provisioning of a disk is automated. It is a scalable storage solution which can run anywhere, from cloud to on-premises hardware.Ceph Storage Cluster
Ceph is an advanced and scalable Software-defined storage which fits best with the needs of today’s requirement providing Object Storage, Block Storage and File System on a single platform. Ceph can also be used with Kubernetes. We can either use CephFS or CephRBD for persistent storage for kubernetes pods.- Ceph RBD is the block storage which we assign to pod. CephRBD can’t be shared with two pods at a time in read-write mode.
- CephFS is a POSIX-compliant file system service which stores data on top Ceph cluster. We can share CephFS with multiple pods at the same time. CephFS is now announced as stable in the latest Ceph release.
GlusterFS Storage Cluster
GlusterFS is a scalable network file system suitable for cloud storage. It is also a software-defined storage which runs on commodity hardware just like Ceph but it only provides File systems, and it is similar to CephFS. Glusterfs provides more speed than Ceph as it uses larger block size as compared to ceph i.e Glusterfs uses a block size of 128kb whereas ceph uses a block size of 64Kb.AWS EBS Block Storage
Amazon EBS provides persistent block storage volumes which are attached to EC2 instances. AWS provides various options for EBS, so we can choose the storage according to requirement depending on parameters like number of IOPS, storage type(SSD/HDD) etc. We mount AWS EBS with kubernetes pods for persistent block storage using AWSElasticBlockStore. EBS disks are automatically replicated over multiple AZ’s for durability and high availability.GCEPersistentDisk Storage
GCEPersistentDisk is a durable and high-performance block storage used with Google Cloud Platform. We can use it either with Google Compute Engine or Google Container Engine. We can choose from HDD or SSD and can increase the size of the volume disk as the need increases. GCEPersistentDisks are automatically replicated across multiple data centres for durability and high availability. We mount GCEPersistentDisk with kubernetes pods for persistent block storage using GCEPersistentDisk.Azure Disk Storage
An Azure Disk is also a durable and high-performance block storage like AWS EBS and GCEPersistentDisk. Providing the option to choose from SSD or HDD for your environment and features like Point-in-time backup, easy migration etc. An AzureDiskVolume is used to mount an Azure Data Disk into a Pod. Azure Disks are replicated within multiple data centres for high availability and durability.Network File System Storage
NFS is the one of the oldest used file system providing the facility to share single file system on the network with multiple machines. There are several NAS devices available for high performance or can we make our system to be used as NAS. We use NFS for persistent storage for pods and data can be shared with multiple instances.RAID storage uses different disks to provide fault tolerance, to improve overall performance, and to increase storage size in a system. Click to explore about, Types of RAID Storage for Databases
Continuous Deployment of Storage Solutions
Now we are going to walk through with the deployments of storage solutions described above. We are going to start with Ceph.Ceph Deployment
For Ceph we need to have an existing ceph cluster. Either we have to deploy Ceph cluster on Bare Metal or can use Docker Containers. Then install ceph client on a kubernetes host. For CephRBD we have to create a separate pool and user for the created pool.- Creating new/separate pool
- Creating a user with full access to the Kube pool
- Get the authentication key from the ceph cluster for the user client.kubep
- Creating a new secret in default namespace in kubernetes
# kubectl create secret generic ceph-secret-kube --type="kubernetes.io/rbd" --from-literal=key='AQBvPvNZwfPoIBAAN9EjWaou6S4iLVg/meA0YA==’ --namespace=default
- kube-controller-manager must have the privileage to provision storage and it needs admin key from Ceph to do that. For that, we have to get admin key
- Creating a new secret for admin in default namespace in kubernetes
# kubectl create secret generic ceph-secret --type="kubernetes.io/rbd" --from-literal=key='AQAbM/NZAA0KHhAAdpCHwG62kE0zKGHnGybzgg==' --namespace=ceph-storage
- After adding secrets we have to define new Storage Class by the copy the following content in the file named ceph-rbd-storage.yml
apiVersion: storage.k8s.io / v1
kind: StorageClass
metadata:
name: rbd
provisioner: kubernetes.io / rbd
parameters:
monitors: 192.168 .122 .110: 6789
adminID: admin
adminSecretName: ceph - secret
pool: kube
userId: kubep
userSecretName: ceph - secret - kube
fsType: ext4
imageFormat: "2"
imageFeatures: "layering"
- Creating a volume using rbd StorageClass in the file named it ceph-vc.yml -
apiVersion: v1
kind: PersistentVolume
metadata:
name: apache - pv
namespace: ceph - storage
spec:
capacity:
storage: 100 Mi
accessModes:
-ReadWriteMany
rbd:
monitors:
-192.168 .122 .110: 6789
pool: kube
image: myvol
user: admin
secretRef:
name: ceph - secret
fsType: ext4
readOnly: false
- Creating a volume claim using rbd StorageClass in the file named it ceph-pvc.yml -
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: apache-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
Storage: 500Mi
- Now we are going to launch Apache pod using the claimed volume. Create a new file with the following content -
apiVersion: v1
kind: ReplicationController
metadata:
name: apache
spec:
replicas: 1
selector:
app: apache
template:
metadata:
name: apache
labels:
app: apache
spec:
containers:
-name: apache
image: bitnami / apache
ports:
-containerPort: 80
volumeMounts:
-mountPath: /var/www / html
name: apache - vol
volumes:
-name: apache - vol
persistentVolumeClaim:
claimName: apache - pvc
- For CephFS we are going to create a Ceph pool -
- Creating a new secret in default namespace in kubernetes for ceph admin user. Using
# kubectl create secret generic ceph-secret --type="kubernetes.io/rbd" --from-literal=key='AQDkTeBZLDwlORAA6clp1vUBTGbaxaax/Mwpew==' --namespace=default
- After adding secrets we have to copy the following content in the file named ceph-fs-storage.yml
apiVersion: v1
kind: ReplicationController
metadata:
name: apache
spec:
replicas: 1
selector:
app: apache
template:
metadata:
name: apache
labels:
app: apache
spec:
containers:
-name: apache
image: apache
ports:
-containerPort: 80
volumeMounts:
-mountPath: /var/www / html
name: mypvc
volumes:
-name: mypvc
cephfs:
monitors:
-192.168 .100 .26: 6789
user: admin
secretRef:
name: ceph - secret
GlusterFS Deployment
We can deploy Glusterfs cluster either on Bare Metal servers or on containers using Heketi. After the deployment, we will create a GlusterFS volume.- Creating the following directory on the server’s where we want to keep the data.
- Then we will create a volume using -
- Now we have to create gluster endpoints for kubernetes. By adding the content to file named gluster-endpoint.yaml
kind: Endpoints
apiVersion: v1
metadata:
name: glusterfs - cluster
subsets:
-addresses:
-ip: 10.240 .106 .152
ports:
-port: 1 - addresses:
-ip: 10.240 .79 .157
ports:
-port: 1
- Create the gluster service in kubernetes by following adding the following content in glusterfs-service.yaml
kind: Service
apiVersion: v1
metadata:
name: glusterfs-cluster
spec:
ports:
- port: 1
- Then we are going to launch Apache pod using gluster as backend storage and add the following content to file apache-pod.yaml -
apiVersion: v1
kind: Pod
metadata:
name: glusterfs
spec:
containers:
- name: glusterfs
image: apache
volumeMounts:
- mountPath: "/var/www/html"
name: glusterfsvol
volumes:
- name: glusterfsvol
glusterfs:
endpoints: glusterfs-cluster
path: kube_vol
readOnly: true
NFS Deployment
For NFS server to be consumed by the Kubernetes pod. First, we are going to create persistent volume by adding the following the content in nfs-pv.yaml.
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /data/nfs
server: nfs.server1
readOnly: false
- Creating persistent volume claim by adding the following content in nfs-pvc.yaml -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs - pvc
spec:
accessModes:
-ReadWriteMany
resources:
requests:
storage: 10 Gi
- Now we are going to launch web-server pod with NFS persistent volume by adding the following content in apache-server.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: apache
spec:
replicas: 1
selector:
app: apache
template:
metadata:
name: apache
labels:
app: apache
spec:
containers:
-name: apache
image: apache
ports:
-containerPort: 80
volumeMounts:
-mountPath: /var/www / html
name: nfs - vol
volumes:
-name: nfs - vol
persistentVolumeClaim:
claimName: nfs - pvc
AWS EBS Deployment
For using Amazon EBS in Kubernetes pod first we have to make sure that -- The nodes on which kubernetes pods are running are Amazon EC2 instances.
- EC2 instances need to be in the same region and AZ as of EBS.
- First, we have to create storage class in kubernetes for EBS disk by adding the following content in awsebs-storage.yaml
kind: StorageClass
apiVersion: storage.k8s.io / v1
metadata:
name: slow
provisioner: kubernetes.io / aws - ebs
parameters:
type: io1
zones: us - east - 1 d, us - east - 1 c
iopsPerGB: "10"
- Then we are going to create PVC by adding the following content in aws-ebs.yaml -
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: aws - ebs
annotations:
volume.beta.kubernetes.io / storage - class: standard
spec:
accessModes:
-ReadWriteOnce
resources:
requests:
storage: 10 Gi
storageClassName: io1
- Now we are going to launch apache-webserver pod with AWS EBS as persistent storage by adding the following content apache-web-ebs.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: apache
spec:
replicas: 1
selector:
app: apache
template:
metadata:
name: apache
labels:
app: apache
spec:
containers:
-name: apache
image: apache
ports:
-containerPort: 80
volumeMounts:
-mountPath: /var/www / html
name: aws - ebs - storage
volumes:
-name: aws - ebs - storage
persistentVolumeClaim:
claimName: aws - ebs
Azure Disk Deployment
- For using the Azure disk as persistent storage for kubernetes pods. We have to create storage class by adding the following content in the file named sc-azure.yaml
kind: StorageClass
apiVersion: storage.k8s.io / v1beta1
metadata:
name: slow
provisioner: kubernetes.io / azure - disk
parameters:
skuName: Standard_LRS
location: eastus
- After creating storage class we are going to create Persistent Volume claim by adding the following content in azure-pvc.yaml.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: azure - disk - storage
annotations:
volume.beta.kubernetes.io / storage - class: slow
spec:
accessModes:
-ReadWriteOnce
resources:
requests:
storage: 10 Gi
- Now we are going to launch Apache-webserver pod with AZURE DISK as persistent storage by adding the following content apache-web-azure.yaml.
apiVersion: v1
kind: ReplicationController
metadata:
name: apache
spec:
replicas: 1
selector:
app: apache
template:
metadata:
name: apache
labels:
app: apache
spec:
containers:
-name: apache
image: apache
ports:
-containerPort: 80
volumeMounts:
-mountPath: /var/www / html
name: azure - disk
volumes:
-name: azure - disk
persistentVolumeClaim:
claimName: azure - disk - storage
GCEPersistantDisk Deployment
For using GCEPersistantDisk in kubernetes pod first, we have to make sure that- The nodes on which kubernetes pods are running are GCE instances.
- EC2 instances need to be in the same GCE project and zone as the PD.
- First, we have to create storage class in kubernetes for the GCEPersistantDisk disk by adding the following content in gcepd-storage.yaml.
kind: StorageClass
apiVersion: storage.k8s.io / v1beta1
metadata:
name: fast
provisioner: kubernetes.io / gce - pd
parameters:
type: pd - ssd
- We are going to create a PVC by adding the following content in gcepd-pvc.yaml.
apiVersion: extensions / v1beta1
kind: Deployment
metadata:
name: apache
spec:
template:
metadata:
name: apache
labels:
app: apache
spec:
containers:
-name: apache
image: bitnami / apache
ports:
-containerPort: 80
volumeMounts:
-mountPath: /opt/bitnami / apache / htdocs
name: apache - vol
volumes:
-name: apache - vol
gcePersistentDisk:
pdName: gce - disk
fsType: ext4
- After creating persistent disk we are going to use to store web-data for the web server pod by adding the following content in the file named.
OpenEBS Deployment
- For OpenEBS cluster setup click on this link for setup guide. First, we are going to start the OpenEBS Services using Operator by -
# kubectl create -f https://github.com/openebs/openebs/blob/master/k8s/openebs-operator.yaml- Then we are going to create some default storage classes by -
# kubectl create -f https://raw.githubusercontent.com/openebs/openebs/master/k8s/openebs-storageclasses.yaml
- Now we are going to launch jupyter with OpenEBS persistent volume by adding the following content in the file named demo-openebs-jupyter.yaml -
apiVersion: apps
kind: Deployment
metadata:
name: jupyter - server
namespace: default
spec:
replicas: 1
template:
metadata:
labels:
name: jupyter - server
spec:
containers:
-name: jupyter - server
imagePullPolicy: Always
image: satyamz / docker - jupyter: v0 .4
ports:
-containerPort: 8888
env:
-name: GIT_REPO
value: https: //github.com/vharsh/plot-demo.git
volumeMounts:
-name: data - vol
mountPath: /mnt/data
volumes:
-name: data - vol
persistentVolumeClaim:
claimName: jupyter - data - vol - claim
-- -
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: jupyter - data - vol - claim
spec:
storageClassName: openebs - jupyter
accessModes:
-ReadWriteOnce
resources:
requests:
storage: 5 G
-- -
apiVersion: v1
kind: Service
metadata:
name: jupyter - service
spec:
ports:
-name: ui
port: 8888
nodePort: 32424
protocol: TCP
selector:
name: jupyter - server
sessionAffinity: None
type: NodePort
Features Comparison for Storage Solutions
|
Storage Technologies |
Read Write Once |
Read Only Many |
Read Write Many |
Deployed On |
Internal Provisioner |
Format |
Provider |
Scalability Capacity Per Disk |
Network Intensive |
|---|---|---|---|---|---|---|---|---|---|
|
CephFS |
Yes |
Yes |
Yes |
On-Premises/Cloud |
No |
File |
Ceph Cluster |
Upto Petabytes |
Yes |
|
CephRBD |
Yes |
Yes |
No |
On-Premises/Cloud |
Yes |
Block |
Ceph Cluster |
Upto Petabytes |
Yes |
|
GlusterFS |
Yes |
Yes |
Yes |
On-Premises/Cloud |
Yes |
File |
GlusterFS Cluster |
Upto Petabytes |
Yes |
|
AWS EBS |
Yes |
No |
No |
AWS |
Yes |
Block |
AWS |
16TB |
No |
|
Azure Disk |
Yes |
No |
No |
Azure |
Yes |
Block |
Azure |
4TB |
No |
|
GCE Persistent Storage |
Yes |
No |
No |
Google Cloud |
Yes |
Block |
Google Cloud |
64TB/4TB (Local SSD) |
No |
|
OpenEBS |
Yes |
Yes |
No |
On-Premises/Cloud |
Yes |
Block |
OpenEBS Cluster |
Depends on the Underlying Disk |
Yes |
|
NFS |
Yes |
Yes |
Yes |
On-Premises/Cloud |
No |
File |
NFS Server |
Depends on the Shared Disk |
Yes |
Concluding Persistent Storage Solutions
Every storage described above provides different features, speed and flexibility. You have to choose accordingly to your requirement. Persistent storage is necessary for stateful servers like MySQL, PostgreSQL, WordPress sites etc. There are a lot of options available for persistent storage. This is where we can help you to make the right decision. Reach out to us, tell us your requirement so that we can discuss and help you out.How Can XenonStack Help You?
Our DevOps Consulting Services provides DevOps Assessment and Audit of your existing Infrastructure, Development Environment and Integration. Our DevOps Professional Services includes -Cloud Infrastructure Solutions
Get Cloud Consulting Services, Cloud Infrastructure Services, Cloud Migration Solutions, Application Migration to Cloud and Cloud Management Services all under one roof. XenonStack offers Cloud Infrastructure Solutions on leading Cloud Service Providers including Microsoft Azure, Google Cloud, AWS and on Container Environment - Docker & KubernetesEnterprise Kubernetes Services
Make your Cloud Native Transformation with Kubernetes. Unify your Container Management Solutions into a Kubernetes Solution with support for Multi-Cloud Environments including AWS,Google Compute Engine, Google Kubernetes Engine, Microsoft Azure and more.Enterprise Continuous Monitoring Solutions
Our DevOps Solutions enables the visibility of Continuous Delivery Pipeline with Continuous Monitoring and Alerting for infrastructure, processes, applications and Hosts. Our Product, for Log Analytics.
- Explore more about Cloud Managed Services
- Read here about Local Storage vs Session Storage vs Cookie


