Introduction to Big Data Pipeline
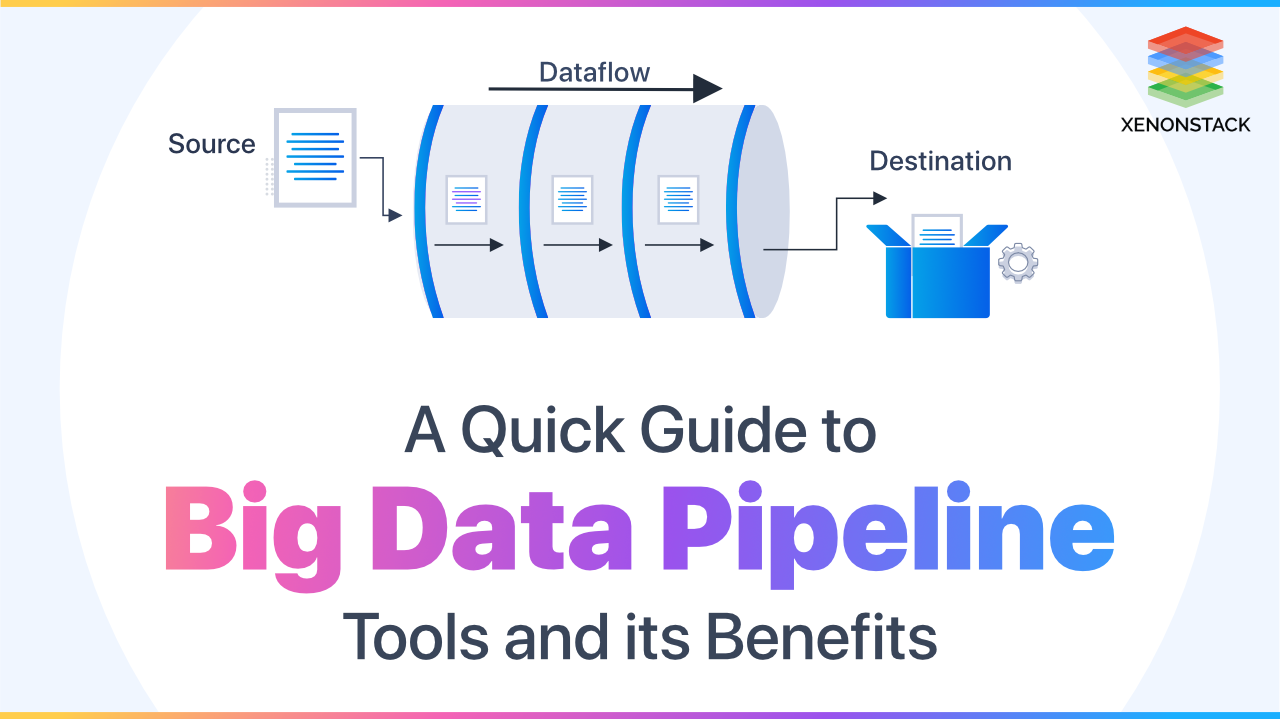
What is Data Pipeline?
A data pipeline moves data from the source to a destination such as a data warehouse, data lake, and data lakehouse. Along the pipeline, data is transformed and optimized, thus making it easier to be analyzed and develop business insights.
What is Big Data?
You might have heard about the term “Big Data.” Big data is not big without data variations, data volume, and velocity of data. The data can be of any format, of any size and any type. If it satisfies, then there would be no hesitation to call that data as Big Data. Big Data is now the need of almost every organization as data is generated in large volumes and these large volumes contain data of every known or unknown type/format. Big Data creates problems like handling data, manipulating data and Analytics for generating reports, business, etc. There comes a solution too as Every problem is a solution. This solution is the development of Data Pipeline.
What is Big Data Pipeline?
Big Data helps to produce solutions like Warehouse, Analytics, and Pipelines. Data Pipeline is a methodology that separates compute from storage. In other words, Pipeline is commonplace for everything related to data whether to ingest data, store data or to analyze that data.
Let us assume a case that you have many works such as Data Analytics, Machine learning, etc. Are in line up and store for that data is shared. In this case, we can Ingest data from many resources and store it in their raw format at Data Storage layer. Now, It will be easy to perform any work from this data. We can also transform that data into data warehouses.
Big Data Architecture helps design the Data Pipeline with the various Batch Processing System requirements or Stream Processing System requirements.Click to explore about, Cloud Governance: The Big Challenges and Best Practices
What is the difference between Big Data Pipeline and ETL?
Sometimes, people get confused by two terms as some use cases use both As keywords interchangeably. But Both are, in fact, different as ETL (Extraction, Transformation and Load) is a subset of Data Pipeline Processing.- ETL is usually performed on Batches (here batch processing)
- Data Pipeline contains both Batch and Real-Time Processing as Batch Engine and Real Time data processing Layer
Big Data to have securities issues and attacks happening every single minute, these attacks can be on different components of Big Data, like on stored data or the data source.Click to explore about, Big Data Security Management: Tools and its Best PracticesFollowing steps are followed for Building Big Data pipeline -
- Data sources are defined and connected via connectors
- Data is ingested in its Raw form
- Data is then processed or Transformed
- Data resides to Warehouses
- Data can be used for Machine Learning, Reporting, Analytics and so on
- If data is critical than it is recommended not to use cloud storage. One has to invest in building up fresh storage of their own.
- Completely mark the line between job scheduling for Real-time and Batch data processing.
- Openly exposing SSL keys is not recommended, try to keep them as Secure as possible as these might expose data to attackers.
- Build Pipeline for suitable workload as these can be scale in and out. So implementing future tasks in the present workload is not at all efficient use case.
Big Data Solutions and Services to transform your business information into value, thereby obtaining competing advantages. Click to explore about, Top 6 Big Data Challenges and Solutions
What are the benefits of Big Data Pipeline?
- Big data pipelines help in Better Event framework Designing
- Data persistence maintained
- Ease of Scalability at the coding end
- Workflow management as the pipeline is Automated and has scalability factors
- Provides Serialization framework
There are some disadvantages of data pipelines also, but these are not that much to worry on. They have some alternatives ways to manage.
- Economic resources may affect the performance as Data Pipelines are best suited for large data sets only.
- Maintenance of job processing units or we can say Cloud Management.
- No more privacy on the cloud for critical data.
What is Big Data Pipeline Automation?
Data Pipeline Automation, helps to automate the various processes such as data extraction, transformation and integration before sending into data warehouse.
What are the best data pipeline tools?
- Apache Spark
- Hevo Data
- Keboola
- Astera Centerprise
- Etleap
Graph Databases uses graph architecture for semantic inquiry with nodes, edges, and properties to represent and store data.Click to explore about, Role of Graph Databases in Big Data Analytics
Why do we need Big Data Pipeline?
Data Pipelines reduces risk of same place capturing and analyzing impairing of data as data is achieved at a different location and examine at a different location.- It maintains dimensional of the system for various visualization points of view.
- Data Pipelines helps in Automated Processing as Job scheduling can be managed and Real Time data tracing is also manageable.
- Data Pipeline defines proper task flow from location to location, work to work and job to job.
- These have Fault Tolerance, inter-task dependencies feature, and failure notification system.
What are the requirements for Big Data Pipeline?
When we talk about running anything in a computer system, there are always some requirements for the same. Big Data Pipelines also has some requirements, such as:- Messaging Component(s) like Apache Kafka, Pulsar, etc. must be defined
- Store (no limits storage) for storing data files of large sizes in Raw format
- Unlimited Bandwidth for transmission
- Additional Processing Units or Cloud (Fully Managed or Managed)
What are the use cases of Big Data Pipelines?
Most of the time, every use case describes how it is essential and how they are implementing it. But why is it necessary too? There are some why points for some of the use cases for Public organizations.
- Consider Forecasting system where data is the core for the financing and Marketing team. Now, Why do they use Pipeline? They can use it for Data aggregation purposes for managing product usage and reporting back to customers.
- Imagine a company using Ad marketing, BI tools, Automation strategies, and CRM. Here, Data is necessary to manage and collect for occasional purposes now if a company relies on these tasks individually and wants to upgrade its workflow.
They have to merge all work under one place, and here Data pipeline can solve their problem and help them build a strategic way to work. - Imagine a company that works on crowdsourcing. It is obvious that they are using many different data sources for crowdsourcing and performing some analytics on that data. So, to obtain better output from crowdsourcing in near real-time and for analytics and ML, that company should build a data pipeline to collect data from many sources and use it for their purposes.

A Data Driven Approach
Data Pipeline is needed in every use case that one can think of in contrast to big data. From reporting to real-time tracing to ML to anything, data pipelines can be developed and managed for these problems.For making strategic decisions based on data analysis and interpretation we advise taking the following steps -- Know more About Solution for Building Big Data Pipeline on AWS
- Learn how to create Big Data Platform


