Introduction to AWS Data Pipeline
AWS Data Pipeline is a web service by AWS for automation, movement, and transformation of enterprise Data. For example, AWS Data Pipeline can move your web server's log data to Amazon Simple Storage Service (Amazon S3) and generate a traffic report. Below are the elements of AWS Data Pipeline that make this data movement and transformation possible
This blog will explain AWS Data Pipeline services, features, and tools. But first, the basics.
What is Data Pipelines?
Data pipelines refer to the general term of data movement from one location to another. The location where the flow of data starts is known as a data source, and the destination is called the data sink.
A data pipeline is essential because there are numerous data sources and sinks in the modern age. The data sources can be data stored in any of the AWS Big Data locations such as databases, data files, or data warehouses. Such data pipelines as called batch data pipelines as the data are already defined, and we transfer the data in typical batches. Whereas there are some data sources, such as log files or streaming data from games or real-time applications, such data is not well defined and may vary in structure. Such pipelines are called streaming data pipelines. Streaming data requires a particular solution, as we must consider delayed data records due to network latency or inconsistent data velocity.We may also like to perform some transformations on the data while it's going from the data source to a data sink; such kinds of data pipelines have been given special names
- ETL - Extract Transform Load
- ELT - Extract Load Transform
How does AWS Data Pipeline Work?
AWS Data Pipeline helps you sequence, schedule, run, and manage recurring data processing workloads reliably and cost-effectively. This service makes it easy for you to design extract-transform-load (ETL) activities using structured and unstructured data, both on-premises and in the cloud, based on your business logic.
As discussed in the beginning let us deep dive into the main components of the AWS Data pipeline.
Pipeline Definition
The pipeline can be created in 3 ways -
- Graphically, using the AWS console or AWS pipeline Architect UI.
- Textually, writing a JSON file format.
- Programmatically, using the AWS data pipeline SDK.
A Pipeline can contain the following components -
- Data Nodes - The section of input data for a task or the location where output data is to be collected.
- Activities - A description of work to perform on a program using a computational means and typically input and output data nodes.
- Preconditions - A conditional statement that must be true before action can run.
- Scheduling Pipelines - Marks the timing of a planned event, such as when an action runs.
- Resources - The computational resource that performs the work that a pipeline defines.
- Actions - An action that is triggered when specified conditions are met, such as the failure of an activity.
Pipeline
It runs and schedules a task to perform specified work. After the pipeline definition is uploaded, it is activated. You can perform various operations on this pipeline like modification, deactivation, and reactivation. An active or scheduled pipeline has these three items associated with it.
- Pipeline components: Pipeline components represent the business logic of the pipeline and are represented by the different sections of a pipeline definition.
- Attempts: AWS Data Pipeline retries a failed operation to provide robust data management. AWS Data Pipeline continues until it reaches the maximum number of retry attempts. Attempt tracks the various attempts, results, and failure reasons if applicable.
- Instances: When AWS Data Pipeline runs a pipeline, the pipeline components are complied to create actionable instances. Each of these instances contains information about a task. Consider this as the to-do list of the pipeline. Then this list is handed over to task runners for completion.
Task Runner
Is responsible for the actual running of the task in the pipeline definition file. Task runner regularly polls the pipeline for any new tasks and executes them according to the resources defined, task runner is also capable of retrying the tasks in the case the tasks fail during execution.
Other AWS Data Pipeline Services
AWS Storage Services
- Amazon DynamoDB - Fully managed NoSQL database with fast performance.
- Amazon RDS - It is a fully managed relational database that can accommodate large datasets. Has numerous options for the database you want, e.g., AWS aurora, Postgres, MsSQL, MariaDB.
- Amazon Redshift - Fully managed petabyte-scale Data Warehouse.
- Amazon S3 - Low-cost highly-scalable object storage.
AWS Compute Services
- Amazon EC2 - Service for scalable servers in AWS data center, can be used to build various types of software services.
- Amazon EMR - Service for distributed storage and compute over big data, using frameworks such as Hadoop and Apache Spark
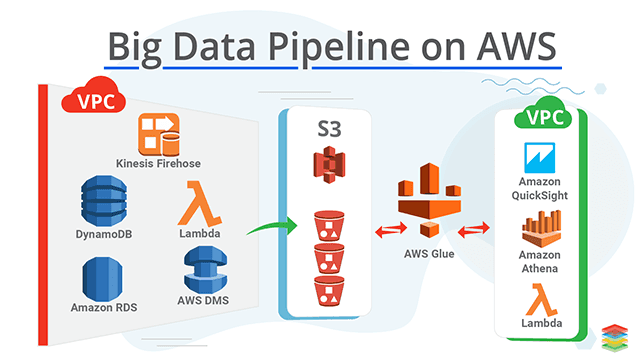
Batch Data Pipeline Solution - AWS Glue
What is AWS Glue?
AWS Glue is a serverless ETL job service. While using this, we don't have to worry about setting up and managing the underlying infrastructure for running the ETL job.How AWS GLUE Works?
AWS glue has three main components -- Data Catalog
- ETL Engine
- Scheduler
Data Catalog
Glue data catalog contains the reference to the data stores that are used as data sources and data sinks in our extract, transform, load (ETL) that we run via AWS Glue. When we defined a catalog, we need to run a crawler which in turn runs a classifier and infers the schema of the data source and data sink. Glue provides with built-in classifiers for data formats such as databases, CSV, XML, json, etc. We can even add our custom classifiers according to our requirements. Crawlers store data in a metadata store which is an AWS RDS table so that it can be used again and again.ETL Engine
The ETL engine is the heart of AWS Glue. It performs the most critical task of generating and running the ETL job. In the ETL job generation part, the ETL engine provides us with a comfortable GUI using which we can select any of the data stores in the data catalog and define the source and sink of the ETL job. Now as we have selected the source and sink, we now choose the transformation we need to apply to the data. Glue provides us with some built-in transformation as well. After we are all set, the ETL engine generates the corresponding pypspark / scala code.
We can edit the ETL job code and customize it as well. Now moving onto the ETL job running part the ETL engine is responsible for running the above-generated code for us. ETL engines manage all the infrastructure ( launching the infrastructure, underlying execution engine for the code, on-demand job run, cleaning up after the job run). The default execution engine is Apache Spark.
Glue Scheduler
Glue scheduler is more or less like a CRON on steroids. We can periodically schedule jobs or run jobs on-demand based on some external triggers, or the job can be triggered via AWS Lambda functions. A typical AWS Glue workflow looks something like this -Step 1 - The first step for getting started with Glue is setting up a data catalog. After the data catalog has been set up, we need to run crawlers on the data catalog to scrap the metadata from the data catalog. The metadata is stored in a table that will be used for running the AWS glue job.
Step 2 - After the data catalog has been set up, its time to run the ETL job. Glue provides us with an interactive web GUI (graphical user interface ) using which we can create the ETL job. We have to select the source, destination and transformation we want to apply to the data. AWS Glue provides us with some great built-in transformation. Glue automatically generates the code for ETL job according to our selected source, sink, and transformation in pyspark or scala based on our choice. We are also free to edit the script if we want to and add our custom transformations.
Step 3 - This is the last step. Since now we have all the arsenal ready to run the ETL job it is time to start the job. AWS Glue provides us with a job scheduler, using which we can define when to run the ETL job, define the triggers upon which the job will be triggered. Glue scheduler is a very flexible and mature scheduler service. Glue under the hood runs the jobs on AWS EMR (Elastic Map Reduce ) and chooses resources from a pool of hot resources so that there is no downtime while running the jobs. AWS Glue will only charge for the measure used when the ETL jobs are running.
Like to read about Data Pipelines and Workflow with Apache Airflow on Kubernetes
Streaming Data pipeline - AWS Kinesis Data Firehose
What is AWS Kinesis Data Firehose?
It is a service that serves as a tool for the ingestion of streaming data from various data sources to the data sinks in a secure way. It can handle an ample amount of data stream workloads and scale accordingly.How Firehose Works?
When we get started with Kinesis Data Firehose, we first have to register a delivery stream, and It is the source of streaming data that we will save. Firehouse also provides the functionality to convert the streaming data chunks into other data formats so that it is easy to query or store in the data lake or data warehouse. Next, we define a lambda function in case we want to perform such a data transformation. Firehose comes with pre-configured AWS Lambda blueprints and templates that make it even easy to implement it. Last and the final step is selecting the data source and the data format we want to store the data. It automatically scales up and scales down depending upon the velocity of the data streams.Why Adopting AWS Kinesis Data Firehose Matters?
Kinesis Data Firehose is primarily made for a data pipeline where we want to store the streaming records to a data lake, in case you want to do processing or any analysis on the streaming data in real-time AWS Kinesis data analytics service is the best suited. Here is the list of supported data sources and sinks -
Data sources - Streaming data from AWS Kinesis Agent, Firehose PUT API's, AWS IOT, CloudWatch Logs, CloudWatch Events.
Data sinks- Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Elasticsearch Service (Amazon ES), and Splunk. AWS Kinesis Data Analytics.
AWS Redshift Spectrum - Data Warehouse Service
What is AWS Redshift Spectrum?
Redshift Spectrum is an extension of AWS Redshift the data warehouse service. Redshift as a warehouse is a combination of computing and storage.
How does Redshift Spectrum Work?
- Select the S3 bucket you want to add as an extension to the Data Warehouse.
- Go to the query editor via the AWS console and write the query in standard ANSI SQL.
- Once the question is written, run it and see the results.
It is straightforward for everyone to run a query over the data warehouse, not requiring an expert in big data and any new infrastructure provisioning.
Why AWS Redshift Spectrum Matters?
So for example, if we have a large Redshift cluster that runs 100's of nodes. But there will be some data that is less frequently queried or is inactive. So as a cost optimization solution we have the Redshift spectrum. It extends the data warehouse to S3 which is inexpensive storage as compared to Redshift, so what we can do now is we can store the less frequently queried data in S3, and whensoever we need to query this data we can make use of the Redshift spectrum. This is useful and cost-effective. It uses the computer from the current Redshift cluster only.
AWS Athena - Query Engine
What is AWS Athena?
- AWS Athena, on the other hand, is a query engine that runs over the data stored in S3.
- In case you don't have a Redshift data warehouse and you want to query the data stored in S3, so Athena is the tool that you are looking for.
- Athena charges you per query basis only. Athena runs the presto framework, by Facebook. Athena can even be integrated with your BI tools such as Tableau.
- Athena saves the need to set up a whole ETL process yourself and to keep the entire computer cluster running for on spot queries to the data.
How AWS Athena Works?
Things to keep in mind while using Athena It helps to Efficiently store the data in S3, for example storing the data in parquet format reduces the data size significantly as well as it is efficient to query also. Generally what happens is we store all the ingested data from different sources at a common staging area and then use the ETL pipeline to transfer and format the data to another location, where we run queries on our data .this the typical use case of Athena in such kind of architecture.
Why Adopting AWS Athena Matters?
Partitioning of data on the basis of business logic also reduces the query time and hence saves cost.
Athena vs. Redshift Spectrum?
Both of them use S3 as the base storage and query over the same data. But yet these both are different in terms of the use case.
What is AWS Kinesis Data Analytics?
It is a service for performing data analytics and processing streaming data.How Kinesis Data Analytics Works?
- Make a data analytics application and select the desired run time from the interactive AWS console.
- Configure the data source that you want the application registered in step1 to process.
- Provide the processing steps that we want to perform on the streaming data.
- Configure the data destination via the AWS console only.
Why Adopting AWS Kinesis Data Analytics Matters?
It is the most suited service where we want to perform streaming analytics and processing with near real-time data at very low latency. It uses Flink as its run time which is the best streaming solution now. Here is the list of supported data sources and sinks -- Data sources - Streaming data from AWS Kinesis Agent, Firehose PUT API's, AWS IOT, CloudWatch Logs, CloudWatch Events.
- Data sinks - Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service and Amazon Kinesis Data Streams as destinations.
- Custom Data pipelines on AWS.
What are custom Data Pipelines on AWS?
It is entirely possible that your data pipeline might be involved and the above solution may not live up to your expectation, so we can even build our data pipeline using AWS services such as AWS Kinesis (for streaming data), AWS Redshift, AWS S3, AWS RDS and for computation purpose we can use AWS EMR (Elastic Map Reduce). In AWS EMR we have a choice of frameworks as well we can use Apache Hadoop or Apache Spark. How to adopt AWS for Big Data Pipelines? AWS has excellent support for migrating the current data and the existing data pipelines to AWS cloud tools such as -- AWS Snowflake
- AWS DMS (database migration service)
- AWS Migration Hub
- AWS DataSync
- AWS SFTP service
- AWS Server Migration
AWS Kinesis Data Analytics Tools
- AWS CLI
- AWS web console.
- AWS SDK in various languages.
- Integration with 3rd party software such as BI tools.
Data Pipeline removes the delay between the instructions that have been executed. Source- Setting up DevOps Pipeline on Amazon Web Services (AWS)
What are the Best practices of AWS Big Data Pipelines?
- Define clear IAM roles to protect your data and resources among various users
- The volume of data expected.
- The velocity of data, the rate at which it is coming.
- Variety of data that the pipeline will be supporting.
- The validity of data in the pipeline.
- Create separate VPC to keep the data, resources, and pipeline protected.
- Monitor the pipeline using AWS CloudWatch.
- Select the tool by Big data 4 V's defined above to optimize the cost accordingly
Holistic Strategy for Building Big Data Pipeline
AWS Data Pipeline is perfect for implementing ETL workflows if an organization's infrastructure is on AWS only. But suppose the ecosystem of an enterprise is beyond AWS. In that case, it may be better to use data pipeline services and solutions to help organizations get the right assistance to create flexible and robust data pipelines. These are the next steps.
- Take the Xenonstack's Big Data Readiness Assessment
- Explore our Big Data Services and Solutions


