
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Big Data
What exactly is Big Data? It is nothing but large and complex data sets, which can be both structured and unstructured. Its concept encompasses the infrastructures, technologies, and Tools created to manage this large amount of information. To fulfill the need to achieve high performance, its Analytics tools play a vital role. Further, various tools and frameworks are responsible for retrieving meaningful information from a huge data set.List of Tools Frameworks
The most important, as well as popular Big Data Analytics Open Source Tools which are used in 2020 are as follows:- Data Storage Tools
- Data Visualization Tools
- Processing Tools
- Data Preprocessing Tools
- Data Wrangling Tools
- Data Governance Tools
- Security Management Tools
- Real-Time Data Streaming Tools
What are the best analytics Frameworks?
- Apache Hadoop
- Apache Spark
- Sqoop
- Apache Druid
- Flink
- Apache Calcite
Apache Hadoop 3.0
It is a framework that allows storing Big Data in distributed mode and allows for the distributed processing on that large dataset. Moreover, it designs so that it scales from a single server to thousands of servers. Not only this, Hadoop itself is designed to detect the failures at the application layer and handle that failures. Hadoop 3.0 is a major release after Hadoop 2 with new features like HDFS erasure coding, improved performance and scalability, multiple NameNodes, and many more.

Apache Spark
This is a cluster computing platform intended to be fast and general-purpose. In other words, it is an open-source, extensive-range data processing engine. With Apache Spark, one can perform the following tasks:- Batch processing
- Stream processing

Explore Apache Spark for the below information:
- Introduction to Apache Spark
- Apache Spark Features
- Overview of Apache Spark Architecture
- Apache Spark Use Cases
- Deployment Mode in Spark
- Why is Spark better than Hadoop?
- Why use Scala for implementing Apache?
A compelling open-source processing engine developed around agility, ease of use, and advanced analytics. Click to explore about our, Apache Spark Architecture
Apache Druid
It is a real-time analytics database that is designed for rapid analytics on large datasets. This database is often used for powering use cases where real-time ingestion, high uptime, and fast query performance are needed. Druid can be used to analyze billions of rows not only in batch but also in real-time. Also, it offers many integrations with different technologies like Apache Kafka Security, Cloud Storage, S3, Hive, HDFS, DataSketches, Redis, etc. Along with this, it also follows the immutable past and append-only future. As past events happen once and never change, these are immutable, whereas the only append takes place for new events. Apache Druid provides users with a fast and deep exploration of large-scale transaction data.

- What is Apache Druid?
- Characteristics of Apache Druid
- Apache Druid Use Cases
- Key Features of Apache Druid
- General Architecture of Apache Druid
- Data Ingestion in Druid
- Zookeeper for Apache Druid
- Monitoring Druid
Apache Flink
Apache Flink-Big data tool is a community-driven open-source framework for shared Analytics. Apache Flink engine exploits in-memory processing and data streaming, and iteration operators to improve performance.
- What is Apache Flink?
- Benefits of Apache Flink
- Why does Apache Flink matter in its Ecosystem?
- Apache Flink in Production
- Apache Flink Best Practices
- Best Tools for Enabling Apache Flink
Apache Calcite
It is an open-source dynamic data management framework licensed by Apache software foundation and written in Java programming language. Apache Calcite consists of many things that comprise a general database management system. Still, it does not have key features like storing the data and processing it, which is done by some specialized engines. 
Explore Apache Calcite to know more about the following:
- What is Apache Calcite?
- Apache Calcite Benefits
- How Apache Calcite Works?
- Apache Calcite Architecture
- Challenges Faced by Query Optimizer
- Learn More About Database Management System
Data Storage Tools
The data storage tools:
Sqoop
Sqoop is a data collection and ingestion tool used to import and export data between RDBMS and HDFS. SQOOP = SQL + HADOOPApache Sqoop is a tool for transferring data between Hadoop and relational database servers. Sqoop transfers data from RDBMS (relational database management system) like MySQL and Oracle to HDFS (Hadoop Distributed File System). Apart from this, it can also transform data in Hadoop MapReduce and then export it into RDBMS.
Sqoop Import
It imports every single table from RDBMS to HDFS. Each row within a table is treated as a single record in HDFS. All records are stored as text data in text files or binary data in Avro and Sequence files.
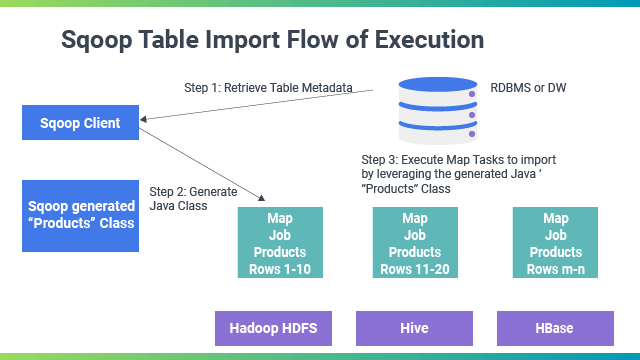
Sqoop Export
this tool exports files from HDFS back to an RDBMS. All the files given as input to Sqoop contain records, which are called rows in the table. Later, those are read and parsed into a set of records and delimited with a user-specified delimiter. 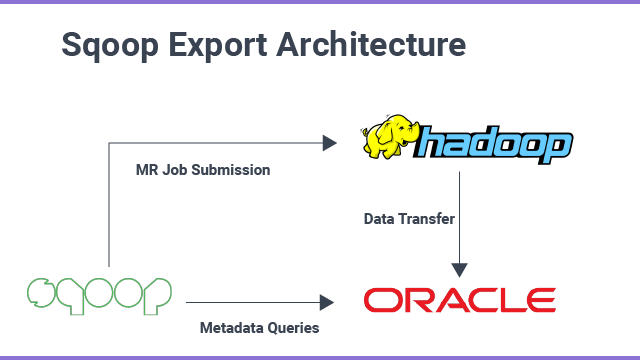
- What is Apache Sqoop?
- Import and Export Architecture
- Why do we need it?
- Features of it?
- Where Can I Use Sqoop?
- Apache Flume and SQOOP
Data Visualization Tools
Data Viz or Data Visualization is the graphical representation of data and information. Using the best Data Visualization tools or visual parts like layouts, outlines, and maps, data perception gadgets give an open technique to see and get examples, individual cases, and models in the information. In the world of information representation, devices, and innovations are necessary to break down several data measures and settle on top information-driven choices.

Explore Data Visualization Blog to know about:
- Overview of Data Visualization
- What Are Data Visualization Tools?
- List of Top 10 Data Visualization tools
2). Sisense
3). QlikView
4). IBM Watson Analytics
5). Zoho Analytics
6). Tableau Desktop
7). Infogram
8). D3.js
9). Microsoft Power BI
10). Data wrapper
What are the processing Tools?
- Google BigQuery
- Amazon Redshift
It is a cloud-based Infrastructure as a Service model designed by Google, which is used to store and process massive data sets with several SQL queries. It can be said that BigQuery is a type of database that is different from transactional databases like MySQL and MongoDB. Although we can use BigQuery as a transactional database, the only problem we will face would be that it would take more time to execute the query.

Explore Google BigQuery to know about:
- Introduction to Google BigQuery
- Why Choose BigQuery?
- How to Use BigQuery?
- Combining BigQuery and DataLab
Amazon Redshift
It is a type of data warehouse service in the Cloud that is fully managed, reliable, scalable, and fast and is a part of Amazon’s Cloud Computing platform, which is Amazon Web Services. We can start with some gigabytes of data only and scale it up to petabytes or more.
ExploreAmazon Redshift to know more about its:
- Why Choose Amazon Redshift?
- Amazon Redshift with QuickSight
Data Preprocessing Tools
- R
- Weka
- RapidMiner
- Python
- Data Preprocessing in R
R is a framework comprising various packages that can be used for Data Preprocessing, like dplyr, etc.
Data Preprocessing in Weka
Weka is a software that contains a collection of Machine Learning algorithms for the Data Mining process. It consists of Data Preprocessing tools that are used before applying Machine Learning algorithms.
Data Preprocessing in RapidMiner
RapidMiner is an open-source Predictive Analytics Platform for the Data Mining process. It provides efficient tools for performing the exact Data Preprocessing process.
Data Preprocessing in Python
Python is a programming language that provides various libraries that are used for Data Preprocessing.
What are the best Data Wrangling tools?
- Tabula
- OpenRefine
- R
- Data Wrangler
- CSV Kit
- Python with Pandas
- Mr. Data Converter
Wrangling in Tabula
Tabula is a tool used to convert the tabular data present in pdf into a structured form of data, i.e., spreadsheet.
Data Wrangling in OpenRefine
OpenRefine is open-source software that provides a friendly Graphical User Interface (GUI) that helps to manipulate the data according to your problem statement and makes Data Preparation process simpler. Therefore, it is handy software for non-data scientists.
Data Wrangling in R
R is an important programming language for data scientists. It provides various packages like dplyr, tidyr, etc., for performing data manipulation.
Data Wrangling using Data Wrangler
Data Wrangler is a tool that is used to convert real-world data into a structured format. After the conversion, the file can be imported into the required application like Excel, R, etc. Therefore, less time will be spent on formatting data manually.
Data Wrangling in CSVKit
CSVKit is a toolkit that provides the facility of conversion of CSV files into different formats like CSV to JSON, JSON to CSV, and much more. This is what makes the process of data wrangling easy.
Data Wrangling using Python with Pandas
Python is a language with the Pandas library. This library helps the data scientist deal with complex problems efficiently and efficiently, making the Data Preparation process efficient.
Data Wrangling using Mr. Data Converter
Mr. Data Converter is a tool that takes Excel files as input and converts the file into required formats. It supports the conversion of HTML, XML, and JSON formats.
What are the best Big Data testing tools?
It is defined as a large volume of data, structured or unstructured. Data may exist in any format, like flat files, images, videos, etc. However, its primary characteristics are three V’s – Volume, Velocity, and Variety, where volume represents the size of the data collected from various sources like sensors, and transactions, velocity is described as the speed (handle and process rates), and variety represents the formats of data. Learn more about Continuous Load Testing in this insight.
Key Analytics Testing Tools
There are various Big Data tools/components –
- HDFS (Hadoop Distributed File System)
- Hive
- HBase

Explore Big Data Testing to know about:
- Data Testing Strategy
- How Does its Testing Strategy Work?
- How to adopt its Testing?
- Top 5 Benefits of its Testing Strategy
- Why does its testing Strategy Matter?
- Big Data Testing Best Practices
- What are the key testing Tools?
Some Additional useful Tools for its Management are
Conclusion
To fulfill the need to achieve high performance, Big Data Advanced Analytics tools play a very vital role in it. Some various open-source tools and frameworks are responsible for retrieving meaningful information from a huge set of data.
- Discover more about the Top 6 Big Data Challenges and Solutions
- Click to explore Big Data Security and Management


























