
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is Apache Spark?
Apache Spark is a fast, in-memory data processing engine with expressive development APIs to allow data workers to execute streaming conveniently. With Spark running on Apache Hadoop YARN, developers everywhere can now create applications to exploit Spark’s power, derive insights, and enrich their data science workloads within a single, shared dataset in Apache Hadoop.
What is Streaming?
Streaming data is unstructured data generated continuously by thousands of data sources. It includes a wide variety of data, such as log files generated by customers using your mobile or web applications, in-game player activity, information from social networks, Financial trading, and telemetry from connected devices or instrumentation in data centres.
Each Dataset in Spark Resilient Distributed Dataset is divided into logical partitions across the cluster. Click to explore about our, RDD in Apache Spark
What is Structured Streaming?
It limits what can be expressed, enabling optimizations since we can perform complex data computations that are impossible in stream processing.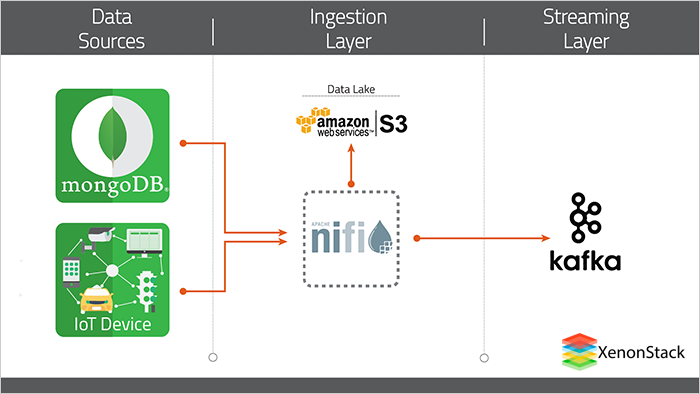
Why do we use Structured Streaming?
In it, any data stream is treated as unbound data: new records added to the stream are like rows being appended to the table. This allows us to treat both batch and streaming data as tables. DataFrame/Dataset queries can apply to both batch and streaming data. Users describe the query they want to run, the input and output locations, and a few more details optionally.
Real-Time Streaming with Apache Spark, Apache Nifi, and Apache Kafka

What is the Data Collection Layer?
The data collection layer is the first layer where we ingest data from different locations. We will define our data flow pipelines using the different data sources in Apache NiFi or Apache MiNiFi.-
File System
-
Cloud bucket(Google storage, Amazon S3)
-
Databases(MySql, Postgre, MongoDB, Cassandra)
-
Real-time stream from the IoT devices
Apache Nifi
Nifi is a data flow automation tool that allows users to send, receive, route, transform, and sort data as needed in an automated and configurable way. Nifi has a user-friendly drag-and-drop graphical user interface that allows users to create data flow per their requirements. Apache NiFi has a predefined processor to fetch/push data to any data source. We can also perform some data transformations in Apache NiFi using predefined processors.What is a Data Routing Layer?
This layer refers to the layer that will send data to multiple different data sources, i.e., Cloud bucket, database, and local file system. We can define this in our Apache NiFi flow. Apache NiFi enables the data to be routed to multiple destinations in parallel.Fast data is not about just volume of data, we measure volume but concerning its incoming rate. Volume and Velocity both are considered while talking about Fast Data Source- A Guide to Streaming Analytics
Apache Kafka
Apache Kafka is a distributed publish-subscribe messaging system used to ingest real-time data streams and make them available to the consumer in a parallel and fault-tolerant manner. Kafka is suitable for building a real-time streaming data pipeline that reliably moves data between different processing systems. Kafka consists of Topics, Consumers, Producers, Brokers, Partitions, and Clusters. Kafka's topics are divided into many partitions. Partitions allow you to parallelize the topic by splitting the data in a particular topic across multiple brokers. Each partition can be placed on a separate machine, allowing multiple consumers to read from a topic in parallel.Apache Kafka use cases.
- Stream Processing
- Metrics Collection and Monitoring
- Website activity tracking
What are the Data Transformation Layers?
Below given are the Data Transformation layers.Apache Spark Structured Streaming
It is the new Apache Spark streaming model and framework built on the SQL engine. Introduce in its 2.0 version too, provides fast, scalable, fault-tolerant, and low-latency processing. The main idea is that you should not have to reason about it but instead use a single API for both operations. Thus it allows you to write batch queries on your streaming data. It provides dataset/data frame API in Scala, Java, Python, or R to express its aggregation,event-time windows, and stream-to-bath join.Dataframe
A data frame is a distributed collection of data organized in a named column and row. With proper optimization, it is similar to the table in the relational database. Dataframes exist to deal with both structured and unstructured data formats, such as Avro, CSV, elastic search, and Cassandra.Dataset
The dataset is a strongly typed data structure in SparkSQL mapped to a relational schema. It is an extension to the data frame API that represents structured queries with encoders. Spark Dataset provides both type safety and an object-oriented programming interface.A cluster computing platform intended to be fast and general-purpose, it is an open-source, extensive range data processing engine. Source: Apache Spark Architecture and Use Cases
How do you read Streaming data from Kafka through Apache Spark?
It provides a tied-in batch and streaming API to view data published to Kafka as a DataFrame. The first step is to specify the location of our Kafka cluster and the topic to read. Spark allows you to read an individual topic, like a specific set of topics, a regex pattern of topics, or even a specific set of partitions belonging to a set of topics.Import org.apache.spark.sql.function._
Create sparkSession
val spark = SparkSession
.builder
.appName("Spark-Kafka-Integration")
.master("local")
.getOrCreate()
Connecting to kafka topic Val df = spark.readStream.format("kafka").option(
"kafka.bootstrap.servers", "host1:port1,host2:port2"
).option("subscribe", "topic1").option("starting Offsets", "earliest").load() df.printSchema() reveals the schema of our DataFrame.root | -- key: binary (nullable = true)
| -- value: binary (nullable = true)
| -- topic: string (nullable = true)
| -- partition: integer (nullable = true)
| -- offset: long (nullable = true)
| -- timestamp: timestamp (nullable = true)
| -- timestampType: integer (nullable = true)
Streaming ETL
Now that the stream is set up, we can start performing the necessary ETL ( Extract, Transform, and Load) to extract meaningful information. Let's say that real-time streaming data is pushed by NIfi to Kafka, as below. {
"city": "",
"country": "India",
"countryCode": "+91”
"lat": 0.00,
"regionName": "Mumbai"
"status": "success"
"zip": ""
}
val result = df.select(get_json_object(($ "value").cast("string"), "$.country")
.alias("countByCountry"))
.groupBy("countByContry")
.county()
result.writeStream.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1").start
Low Latency Continuous Processing Mode in Structured Streaming
Continuous Processing is a new Execution engine in Spark 2.3 that allows very low end-to-end latency with at least one fault tolerance guarantee. Compare this with the default micro-batch processing engine, which can achieve an exact-once guarantee of latency of 1 second. It sparks wait for 1 second and batches together all the events received during that interval into a micro-batch.
After a micro-batch execution is complete, collect the next batch and reschedule. This scheduling is frequently completed to give an impression of its execution. However, low latency doesn’t come without any costs. In fact, faster processing decreases the delivery guarantees to at least once from exactly once. So, continuous execution is advised for systems where the processing latency is more important than the delivery guarantee.
val result = spark.writeStream.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous(" 1 seconds ")) //only this line include for continuous
.start()
For continuous mode, you can choose which mode helps to execute without modifying the application logic. To run a query in a continuous processing mode, you only need to specify a continuous trigger with the desired checkpoint interval as the parameter. There is no need to change the logic of the code.

Using this API, we will consume and transform complex data streaming from Apache Kafka. We can express complex transformations like exactly-once event-time aggregation and output the results to various systems. The system then runs its query incrementally, maintaining enough state to recover from failure and keep the results consistent in external storage.
- Explore about Apache Spark on AWS
- Click here to read the Guide to Real-Time Streaming Data Visualization.



























