Introduction to Apache Spark
It is a cluster computing platform intended to be fast and general-purpose. In other words, it is an open-source, extensive range data processing engine. It provides a lot of functionality -- High-level APIs in Java, Scala, Python, and R.
- The very simplified, challenging, and the computationally intensive task of high processing volumes of real-time or archived data.
- Fast programming up to 100x faster than Apache Hadoop MapReduce in memory.
- Building data applications as a library and also to perform ad-hoc data analysis interactively.
- Increase in processing speed of a claim.
- In-memory cluster computation capability.
Apache Spark is a fast cluster computing platform developed for performing more computations and stream processing. Source: Apache Spark Optimization Techniques
It is a compelling open-source processing engine developed around agility, ease of use, and advanced analytics.It Spark is most famous for running the Iterative Machine Learning Algorithm. With Spark following tasks can be performed -
- Batch processing
- Stream processing
Apache Spark’s Components
- Spark’s MLlib for machine learning
- GraphX for graph analysis
- Spark Streaming for stream processing
- Spark SQL for structured data processing
What are the key features?
| Fast | Ease of development | Deployment flexibility | Unified Stack | Multi- language support |
| 10x faster on disk. 100x faster in memory. | Interactive shell. Less code. More operators. Write programs quickly | Deployment -Mesos, YARN, Standalone Storage -MapR-XD, HDFS, S3 | Build applications combining different processing model. Batch Analytics, Streaming Analytics and Interactive Analytics. | - Scala - Python - Java - Spark - R |
Other Features of are listed below:
Currently implements APIs in Scala, Java, and Python, with assistance for additional languages such as R programming language.
- It blends well with the Hadoop ecosystem and data sources like Hive, HBase, Cassandra, etc.
- It can run on standalone.
- Unified Platform for writing big data applications.
- Computational Engine is responsible for scheduling, distributing, and monitoring applications.
- Designed to be highly accessible.
- Dynamic in Nature, as to make it easy to develop a parallel application as Spark provides high-level operators.
- In in-memory processing, we can enhance the processing speed. Here the data is being stored, so we need not retrieve data from the disk each time. Therefore, time is saved.
- We can reuse the Spark code for batch-processing, join stream against historical data.
- Support Multiple Languages like Java, R, Scala, Python to provide dynamicity and overcomes the limitation of Hadoop i.e., can build applications only in Java.
- Spark can run independently. Thus it gives flexibility.
- Cost Efficient, as in Hadoop, a large amount of storage, and large data center required during replication.
Big Data Challenges include the best way of handling the numerous amount of data that involves the process of storing, analyzing the huge set of information on various data stores. Click to explore about, Top 6 Big Data Challenges and Solutions
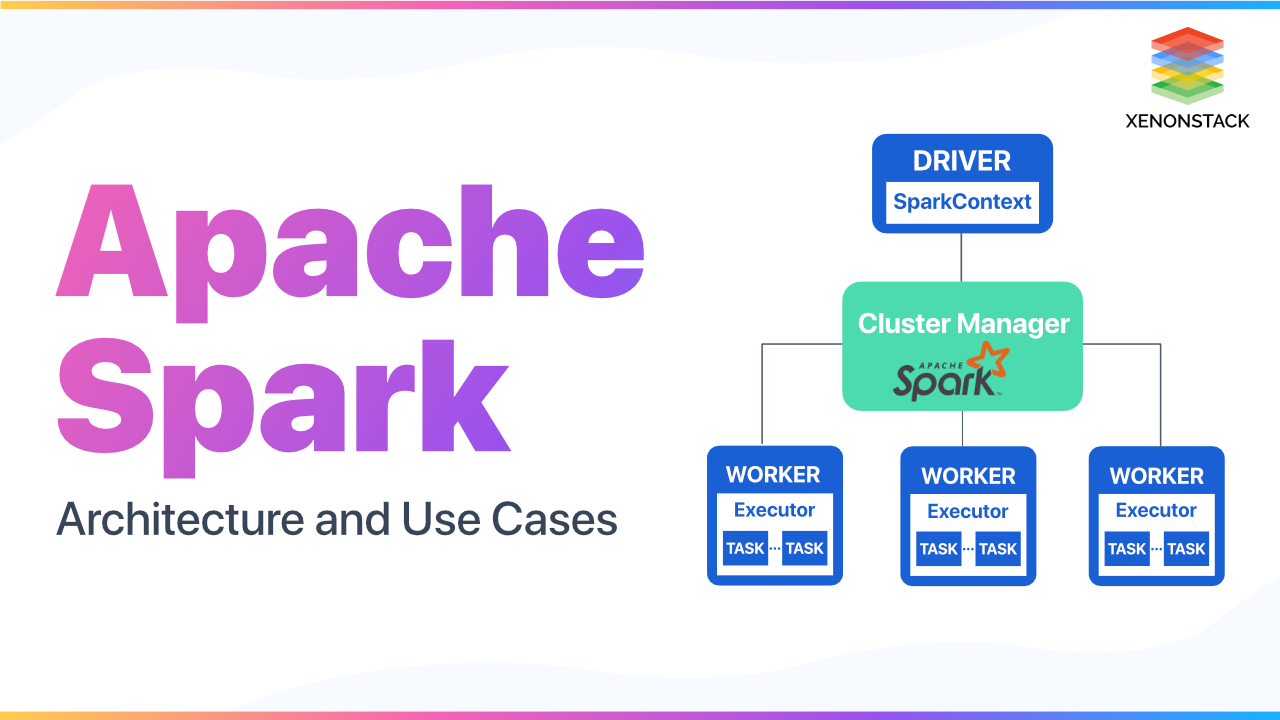
What is the architecture of Apache Spark?
It consists of various principal elements, including Spark core and upper-level libraries. Spark core operates on distinct cluster managers and can obtain data in any Hadoop data source.
Spark Core - It provides a simple programming interface for large-scale processing datasets, the RDD API. It holds a relationship with the Spark cluster administrator. All Spark applications run as an independent set of processes, regulated by a SparkContext in a plan.
Upper-level libraries - Numerous libraries have been built on top of Spark Core for controlling diverse workloads.
Cluster Manager - It allocates resources to each application in the driver program. There are necessarily three kinds of cluster managers maintained by it-
What are the best Use Cases?
As Spark is a general-purpose framework for cluster computing, it is used for a diverse range of applications -- In the Finance Industry
- In e-commerce Industry
- Use in Healthcare
- In Media, Entertainment Industry
- In Travel Industry
- Streaming ETL
- Data Enrichment
- Trigger event detection
- Complex session analysis
- Classification
- Clustering
- Collaborative Filtering
- Interactive Analysis
- Data Processing application
Spark authentication is the configuration parameter through which authentication can be configured. Source: Apache Spark On Kubernetes and Spark Security
What is deployment Mode in Apache Spark?
When we submit a job for execution, the behavior of the job depends on one parameter i.e., the Driver component. In the deployment of Spark, it specifies where the driver program will execute. The deployment can be in two possible ways i.e. -
- Client mode - As the behavior depends on the driver component, so here job will run on the machine from which job is submitted. So this mode is client mode.
- Cluster mode - Here driver component of spark job will not run on the local machine from which job is submitted, so this mode is cluster mode.
Here job will launch driver components inside the cluster. Load balancing is a process of distributing the workload dynamically and uniformly across all the available nodes in the cloud. This improves the overall system performance by shifting the workloads among different nodes. Load balancing takes care of the following things -
- Uniform distribution of load on nodes
- Improves overall performance of the system
- Higher user satisfaction
- Faster Response
- System stability
Load Balancing Measurement Parameter
- Throughput- The amount of work to be done in the given amount of time.
- Response time- The amount of time used to start fulfilling the demand of the user after registering the request.
- Fault Tolerance- The ability of the load balancing algorithm that allows the system to work in some failure condition of the system.
- Scalability - The strength of the algorithm to scale itself according to required conditions.
- Performance- The overall check of the algorithms working by considering accuracy, cost, and speed.
- Resource Utilization- It is used to keep a check on the usage of various resources.
Algorithm for load balancing
There are many load balancing algorithms, but they are generally classified into two categories -
Static Algorithm - These are good for a homogeneous and stable environment. Some of the static algorithms are -
- Round Robin Load Balancing Algorithm (RR)
- Load Balancing Min-Min Algorithm (LB Min-Min)
- Load Balancing Min-Max Algorithm (LB Min-Max)
- Distributed System.
- Non-Distributed System.
- Honeybee Foraging Behavior Load Balancing Algorithm.
- Throttled Load Balancing Algorithm.
- ESCE (Equally Spread Current Execution) Load Balancing Algorithm.
- Ant Colony Load Balancing Algorithm.
- Biased Random Sampling Load Balancing Algorithm.
- Modified Throttled Load Balancing Algorithm.

Why Apache Spark is better than Apache Hadoop?
There are many advantages of Apache Spark in comparison to Hadoop. For example- Faster- It is much faster while doing Map side shuffling and Reduce side shuffling.
- Language Support- It has API assistance for modern data science languages like Python, R, Scala, and Java.
- Supports Realtime and Batch processing- Spark supports batch data processing where a collection of transactions is collected over some time. For instance, climate information attaining in from sensors can be processed by Spark directly.
- Lazy Operation- They are used to optimize solutions in it.
- Support for multiple transformations and actions- Hadoop supports only MapReduce, but it handles many alterations and developments, including MapReduce.
- In-memory Computation- The most significant benefit of using Spark is that it saves and loads the data in and from the RAM rather than from the disk. RAM has a much more powerful processing speed than Hard Drive, and Spark uses in-memory calculations to speed up 100x faster than the Hadoop framework.
Why use Scala for implementing Apache?
Scala Programming is a Object Oriented Programming + Functional Programming Scala (Scalable Language) is an open-source language, a multi-paradigm programming language, and promotes functional as well as to object-oriented standards. From the functional programming viewpoint: each function in Scala is a value and from the object oriented aspect: each benefit in Scala is an object. Some are the reason for choosing Scala for implementing Spark -- Python is slower than Scala, if you have significant processing logic written in your codes, then Scala will offer better performance.
- As Java does not support REPL (Read-Evaluate-Print Loop) interactive shell, with an interactive shell, developers, and data scientists can investigate and obtain their dataset and prototype their application quickly.
- Scala renders the expressive power of dynamic programming language without compromising on type safety.
- It retains a perfect balance between productivity and performance.
- Scala has well-designed libraries for scientific computing, linear algebra, and random number generation.
- Less complexity.
Apache Hadoop scales from a single server to thousands of servers. Hadoop detects the failures at the application layer and handles that failure. Source: How to Adopt Apache Hadoop with GPU?
What is Scala?
Scala is a modern multi-paradigm programming language produced to display typical programming patterns in a concise, sophisticated, and type-safe way. Scala stands for Scalable language. Other languages are also scalable, but they are expandable up to a specific limit, but Scala is much more scalable compared to other languages. If we Talk about the word Big Data; Scala is an imperative language. Scala is not more about procedure, objects, and it’s more about functions. It smoothly integrates features of an object-oriented and functional language. There are multiple reasons to learn Scala -- Statically typed
- Runs on JVM, full inter-operation with Java
- Object-Oriented
- Functional
- Dynamic Features
What are the features of Scala?
- Type Inference - Not require to mention data type and function return type explicitly. Scala is smart enough to infer the type of data. The return type of function is commanded by the kind of last expression present in the function.
- Singleton Object - In Scala, there are no static variables or methods. Scala uses a singleton object, which is class with only one object in the source file. Singleton object is declared by using the object instead of the class keyword.
- Immutability Scala uses the immutability concept. Each declared variable is immutable by default. Immutable means you can't modify its value. You can also create mutable variables that can be changed.
- Lazy computation
- Case classes and Pattern matching
- Concurrency control
- String interpolation
- Higher-order function
- Traits
A Comprehensive Approach
Apache Spark due to its very simplified, challenging, and the computationally intensive task of high processin capabilities helps to Enterprises to process data faster, solving complex data problem in very less time. To know more about Data Processing Services we advise talking to our expert.
- Explore more about Open Source Big Data Tools
- Read more about Big Data Testing Best Practices


