
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Data Transformation using ETL - A Comprehensive Guide
9:41
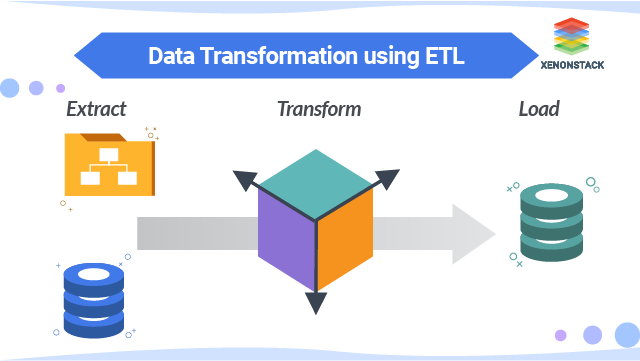
What is Data Transformation?
Data Transformation is the method of changing data from one order or structure into another order or arrangement. Data Transformation is crucial to actions such as data unification and data administration. Data Transformation can cover a range of activities. In Data Transformation, we work on two types of methods. In the first process, we implement data discovery, where we recognize the origins and data types. Then we determine the composition and Data Transformations that need to happen. After this, we complete data mapping to determine how a particular field is mapped, transformed, merged, separated, and aggregated.Transform Data into Intelligence, and discover how to develop a Modern Enterprise Data Strategy. Explore our Services, Enterprise Data Strategy to Transform BusinessIn the second method, we pluck data from the source. The scope of sources can differ, including structured sources, like databases, or streaming sources then we do transformations. You transform the data, such as changing date formats, updating text strings or combining rows and columns, then we transfer the data to the destination store. The destination might be a database or a data warehouse that controls structured and unstructured data.
Why do we need Data Transformation?
Usually, corporations transform the data to make it cooperative with other data, transfer it to different systems, combine it with other data. For example, if there is a parent company that wants the data of all the employees of the sales department of the child company in its database then first the data of the employees of the sales department will be extracted and then loaded to the parent company's database. Several reasons tell why the Data Transformation is done:- You want to compare sales data from another source or calculating sales from different regions.
- You want to combine unstructured data or streaming data with structured data to examine it simultaneously.
- You want to append information to your data to improve it.
- You are relocating your data to a new source.
Challenges in Data Transformation
Converting data into massive Data form People try to transform data into significant amounts of data. They might not be informed of the complexity of the delivery, access, and control of data from a deep range of sources and then storing these data in a big data store. Less efficient Every conversion is required to experience a range of various tests to assure that only essential data reaches the final datastore/warehouse. The tests are mostly more time-consuming and less effective big data sets. Data from different Sources Storing data from various origins to a target system undergoes several constraints. There are a lot of chances of data damage and corruption. Not having a proper vision of customer Data a considerable amount of organizations now has an isolated system including several scraps of data about client/customer communications, but no clear plan to drag them collectively. It leads to petabytes of data and makes their work more painful.What is Data Transformation in ETL?
In Data Transformation, ETL methods are used. ETL defines extraction, transformation, and load. These database methods are combined into one medium to pick data out of one data store and put it into another data store. The extract is the manner of selecting data from a database. In extraction, the data is collected from various types of origins. Transform converts the extracted data into the order it needs to be in so that it can be set into another database. The load is the function of rewriting the data into the target datastore.ETL Architectures
Data Architecture
1. Data Quality
Low-quality data should be identified in a data evaluation period and refined in the generated operational systems. For example, if there are missing values in the data, then It makes no reason to load the data store with sparse quality data.
2. Metadata
Specialized metadata represents the structure as well as the format of the source and target datastore also the mapping and conversion rules between them. Metadata should be evident and usable to both applications and people.
3. Similar origin and Target Data Forms
Target data forms should be created from a physical data model. The more varied the source and target data forms, the more complex the ETL methods, processing, and preservation work. In the duration of physical implementation, even files are the most common data cause.
4. Dependencies
Dependencies in the data will decide the structure of load tables. Addictions also lead to a decrease in lateral storing procedures.
Application Architecture
1. Recoverable loads
we need to be capable to decide the relevant development if the system crashes Incomplete loads can be anxiety. Depending on the size of the data warehouse and volume of the data.
2. Logging
ETL methods should log data about the data stores, modify, and load. Essential data covers date processed, several rows, read rows, written data, faults found, and rules implemented.
Technology Architecture
1. Disk memory
The data stores conceivably have requirements for huge disk memory, but there is also a lot of unknown disk memory required for staging states and standard files.
2. Scheduling
Storing the data stores could affect numbers of source files, which originate on various systems, use multiple techniques, and are delivered at different times.
3. Amount and Recurrence of Loads
When batch applications arrange the datastore, a large quantity of data will manage to decrease the batch window. The number of data affects the recovery work as well.
ETL using Python and SQL
-
Using Python - Extraction
import sqlalchemy import create_engine from sqlalchemy import Table from sqlalchemy from sqlalchemy import inspect, Column, Integer, String, MetaData, ForeignKey eng = create_engine('myDataBase.db') eng meta = MetaData() meta.create_all(eng) ins = inspect(eng) ins.get_columns('employees') with eng.connect() as conn: rw = conn.execute('SELECT * FROM employees') for rows in rw: print(rows) conn.close() This code is used to create the metadata and instantiate the table which already exists. This code connects to the engine, which is already connected with the database rws = con.execute("""SELECT MAX(JoiningDate), EmpId FROM employees;""") for rows in rws: print(rows) conn.close() Code will get the Most Junior Employees from the database. import pandas df = pandas.read_sql_query(""""SELECT MAX(JoiningDate), Emp_Id FROM employees;"""") conn=eng.connect()); This will load the data in the panda data frame. Now you can implement further tasks on the data present in the data frame.
-
Using SQL
CREATE TABLE managers AS SELECT emp_id, firstname, lastname, designation, salary By using this code, we extracted the data. We selected only the data from the managers. DECLARE CURSOR emp_curr IS SELECT emp_id, salary FROM managers WHERE designation = "manager" FOR UPDATE; incr_sal NUMBER; FROM emp; Here we selected those managers who are having salary less than 15000. This information will be used to transform the data. BEGIN FOR emp_record IN emp_cur LOOP IF emp_record.salary < 15000 THEN incr_sal := 5000; END IF; This code will perform Data Transformation. UPDATE manager SET salary = salary + incr_sal WHERE CURRENT OF emp_curr; END LOOP; END;
Benefits of ETL
Enterprise Centric
- A lot of ETL tools can merge structured data with unstructured data in a single mapping, and they can manipulate very massive volumes of data that don't certainly have to be saved in data stores/warehouses.
- Suitable for datastore/warehouse conditions.
Supply Centric
- The most excellent benefit of an ETL tool is that if the device is flow-based, then it gives a visible movement of the system's logic.
- ETL is suitable for significant data movements with complicated rules and transforms.
Customer-Centric
- ETL tools execute sustaining and traceability considerably easier than hand-coding.
- ETL tools provide a more robust set of cleansing methods than those available in SQL So that you can perform complex ETL queries
ETL Challenges and Solutions
- To use ETL tools, you must be a data-oriented programmer or database analyst.
- If the requirement changes, then it will be difficult for ETL tools to perform the queries.
- It is not an ideal choice where we want real-time data access because it needs a quick response.
Ways to resolve issues of ETL
1. Partition Large Tables
Cut large tables in shorter ones. Every partition has its contents, and the tables tree is more lightweight, thus providing more rapid access to the data.
2. Cache the Data
Caching data can considerably speed things up as memory access functions faster than do hard drives. Caching is restricted by the vast amount of memory the hardware supports.
3. Parallel processing
Rather than processing serially, optimize data by processing in parallel. Prevent processing because they need to end before the upcoming work can begin.
Next Steps Towards Data Transformation
Talk to our experts about implementing compound AI system, How Industries and different departments use Agentic Workflows and Decision Intelligence to Become Decision Centric. Utilizes AI to automate and optimize IT support and operations, improving efficiency and responsiveness.
More Ways to Explore Data Insights
Transforming Data Management
Data Processing with EtLT: A Modern Architectural Shift
7 Essential Data Strategy | A Quick Guide


























