
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Overview of Stream Analytics
Stream Analytics delivers the most powerful insights from the data. Nowadays, there are a lot of Data Processing platforms available to process data from our ingestion platforms. Some support streaming of data and others support real streaming of data called Real-Time data. Streaming means that we can process the data instantly as it arrives, and then process and analyse it at ingestion time. However, in streaming, we can consider some delay in streaming data from the ingestion layer. However, real-time data needs to have tight deadlines regarding time.
So we usually believe that if our platform can capture any event within 1 ms, we call it Real-Time Streaming data. But when we talk about making business decisions, detecting frauds, analysing real-time logs, and predicting errors in real-time, all these scenarios come to streaming, so the data is received instantly as it arrives, termed real-time data.
Stream Analytics Tools & Frameworks
So in the market, there are many open source technologies available like Apache Kafka, in which we can ingest data at millions of messages per sec. Also, Apache Spark Streaming, Apache Flink, Apache Storm analyzes Constant Streams of data. 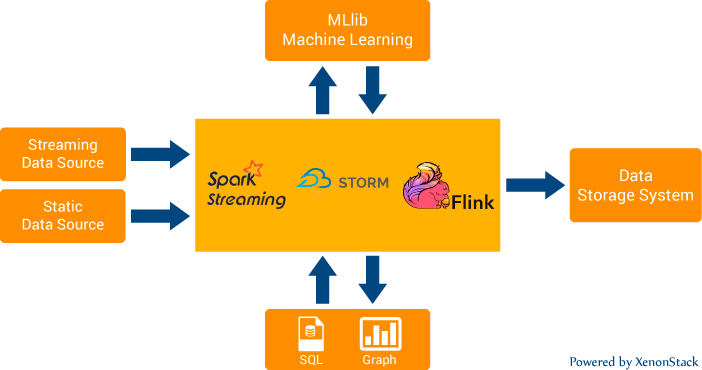 Apache Spark Streaming is the tool to specify the time-based window to stream data from our message queue. So it does not process every message individually. We can call it the processing of real streams in micro-batches. Whereas Apache Storm and Apache Flink can stream data in real-time.
Apache Spark Streaming is the tool to specify the time-based window to stream data from our message queue. So it does not process every message individually. We can call it the processing of real streams in micro-batches. Whereas Apache Storm and Apache Flink can stream data in real-time.
Why Stream Analytics is important?
As we know, Hadoop, S3, and other distributed file systems support data processing in huge volumes. We can also query them using their different frameworks like Hive, which uses MapReduce as their execution engine.Why we need Real-Time Stream Analytics?
Many organizations are trying to collect as much data as possible regarding their products, services, or even their organizational activities, like tracking employees' activities through various methods like log tracking and taking screenshots at regular intervals. So Data Engineering allows us to convert this data into basic formats and Data Analysts. Then turn this data into useful results, which can help the organization improve their customer experiences and boost their employee's productivity. But when we talk about log analytics, fraud detection, or real-time analytics, this is not the way we want our data to be processed. The actual value data is in processing or acting upon it at the instant it is received.
Imagine we have a data warehouse like hive having petabytes of data in it. But it allows us to analyze our historical data and predict the future. So processing huge volumes of data is not enough. We need to process them in real-time so that any organization can take business decisions immediately whenever an important event occurs. This is necessary for Intelligence and surveillance systems, fraud detection, etc. Earlier handling of these constant data streams at a high ingestion rate is managed by firstly storing the data and then running analytics on it. But organizations are looking for platforms to look into business insights in real-time and act upon them in real-time. Alerting platforms are also built on top of these real-time streams. But the Effectiveness of these platforms lies in how honestly we are processing the data in real-time.
Software testing helps to check whether the actual results match the expected results and to assure that the software system is Bug- free. Source: Guide to Functional Testing
What are the best practices for streaming analytics?
Stream analytics is a strong tool for collecting data in real-time from numerous sources and processing it to derive valuable insights. However, it might result in better performance and accurate findings. This section will review some streaming analytics recommended practices to guarantee a smooth and effective installation.
-
Use Appropriate Technology Stack: Pick the right technology stack is critical for stream analytics. It is essential to consider the kind of data being gathered, its volume, and the frequency with which it needs to be analyzed. The technology stack should deal with the new data effectively and accurately. Additionally, it should be able to offer the appropriate levels of performance and scalability.
-
Leverage the Cloud: Stream analytics can benefit significantly from the cloud. Thanks to its adaptability and scalability, businesses can quickly access and analyze large amounts of data. Additionally, utilizing the cloud can lower expenses and boost productivity.
-
Optimize data flow: The design should speed up the collection, processing, and analysis of all data. This can be accomplished by optimizing the architecture of the data flow, such as by using parallel processing, using the appropriate infrastructure and system configurations, reducing the amount of data stored, and using the appropriate instruments for analyzing the data.
-
Perform Quality Assurance: Stream analytics relies heavily on high-quality data. Poor data quality can result in inaccurate outcomes. To guarantee this accuracy, it is essential to have a procedure for monitoring and managing data quality. This includes validating the incoming data and fixing errors with quality control methods.
-
Process Automation: Stream analytics can require a lot of manual labor. However, automation has the potential to speed up and improve efficiency. Data collection, cleansing, transformation, and analysis can all benefit from automation. Additionally, automation can assist in ensuring that the data and results are accurate.
-
Performance Monitoring: The stream analytics system's performance must be continuously monitored. Monitoring, data cleansing, transformation, and analysis are all part of this. Performance monitoring can help ensure the system's optimal operation and prompt identification and resolution of any issues.
Following these best practices, businesses can get the most out of their stream analytics projects. They can ensure that their projects are successful and that their data is accurate and readily available.
Stream Analytics Use Cases
The ability to analyse, integrate and predict data in real-time at a large scale opens up many new use cases for streaming analytics. Organisations have been using batch and historical data to gain insights; with streaming in the picture, organisations can enhance their capabilities to gain more refined, valuable, and real-time insights. Some of the use cases of streaming analytics are mentioned below.
-
Finance and banking-related fraud detection
-
Real-time stock market analysis
-
Sales, Marketing, and Business Analytics
-
Customer/user activity monitoring
-
Log Monitoring: Troubleshooting systems and servers
-
Security Information and Event Management: analyzing logs and real-time event data for threat detection.
-
Warehouse and Retail inventory management: Provide seamless user experience and inventory management across all devices
-
Personalized User experiences
Use of Reactive Programming & Functional Programming
Now, when we are thinking of building our alerting platforms, anomaly detection engines, etc., it is vital to consider the style of programming you are following on top of our real-time data. Nowadays, Reactive Programming and Functional Programming are at their boom.
What is Reactive Programming?
So, we can consider Reactive Programming as a subscriber and publisher pattern. Often, we see the column on almost every website where we can subscribe to their newsletter. Whenever the editor posts the newsletter, whoever has a subscription will get the newsletter via email or another way. So the difference between Reactive and Traditional Programming is that the data is available to the subscriber as soon as it is received. And it is made possible by using the Reactive Programming model. In Reactive Programming, certain components (classes) are registered for that event whenever any events occur. So instead of invoking target elements by event generator, all targets automatically get triggered whenever an event occurs.
What is Functional Programming?
Now when we are processing data at a high rate, concurrency is the point of concern. So the performance of our analytics job highly depends upon memory allocation/deallocation. So in Functional Programming, we don’t need to initialize loops/iterators on our own. We will be using Functional Programming styles to iterate over the data. The CPU itself takes care of the allocation and deallocation of data and makes the best use of memory, which results in better concurrency or parallelism.What is Stream Analytics and Processing in Big Data?
While streaming and analysing the real-time data, there are chances that some messages can be missed, or in short, the problem is how we can handle data errors. So, two types of architectures are useful while building real-time pipelines.Lambda Architecture for Big Data
This architecture was introduced by Nathan Marz in which we have three layers to provide real-time streaming and compensate for any data error that occurs, if any. The three layers are Batch Layer, Speed layer, and Serving Layer.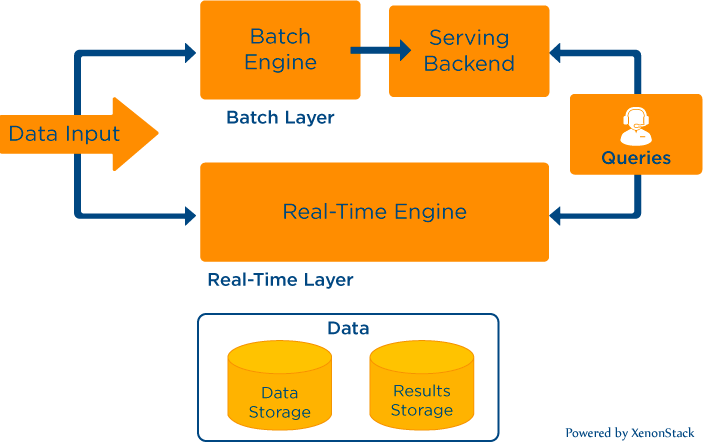 So data is routed to the batch and speed layers by our data collector concurrently. So Hadoop is our batch layer, and Apache Storm is our speed layer. And NoSQL datastore like Cassandra, MongoDB is our serving layer in which store the analyze results. So the idea behind these layers was that the seed layer would be providing real-time results into the serving layer and if any data errors or any data is missed. At the same time, stream processing, then batches job will compensate for that. The MapReduce job will run at the regular interval and update our serving layer, providing accurate results.
So data is routed to the batch and speed layers by our data collector concurrently. So Hadoop is our batch layer, and Apache Storm is our speed layer. And NoSQL datastore like Cassandra, MongoDB is our serving layer in which store the analyze results. So the idea behind these layers was that the seed layer would be providing real-time results into the serving layer and if any data errors or any data is missed. At the same time, stream processing, then batches job will compensate for that. The MapReduce job will run at the regular interval and update our serving layer, providing accurate results.
Kappa Architecture for Big Data
The above Lambda architecture solves our problem for data error and provides flexibility to provide real-time and accurate results to the user.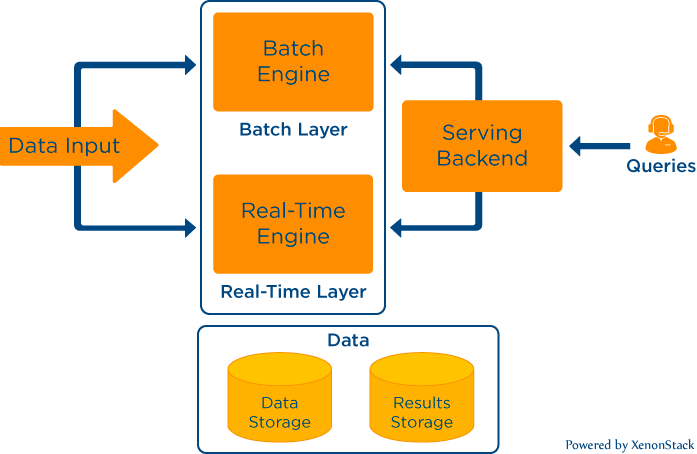 But Apache Kafka's founders raise the question on this Lambda architecture. They loved the benefits provided by the lambda architecture. Still, they also state that building the pipeline and maintaining analysis logic in both batch and speed layers is tough. So If we use frameworks like Apache Spark streaming frameworks, Apache Flink and Beam support batch and real-time streaming. So it will be straightforward for developers to maintain the logical part of the data pipeline.
But Apache Kafka's founders raise the question on this Lambda architecture. They loved the benefits provided by the lambda architecture. Still, they also state that building the pipeline and maintaining analysis logic in both batch and speed layers is tough. So If we use frameworks like Apache Spark streaming frameworks, Apache Flink and Beam support batch and real-time streaming. So it will be straightforward for developers to maintain the logical part of the data pipeline.
What is Stream Processing and Analytics For IoT?
Internet of things is a scorching topic these days. So numerous efforts are going on to connect devices to the web or a network. In short, we should be monitoring our remote IoT devices from our dashboards. IoT Devices includes sensors, washing machines, car engines, coffee makers, etc., and it almost covers every machinery/electronic device you can think of.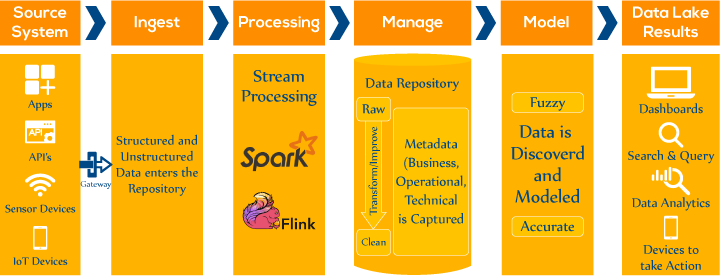 So let’s say we were building a retail product in which we need to provide real-time alerts to organizations regarding their electricity consumption by their meters. There were thousands of sensors, and our data collector was ingesting data at a very high rate, I mean in millions of events per second. So Alerting platforms need to provide real-time monitoring and alerts to the organization regarding the sensor's status/usage. To meet these requirements, Our platform should provide real-time streaming of data and ensure the accuracy of results.
So let’s say we were building a retail product in which we need to provide real-time alerts to organizations regarding their electricity consumption by their meters. There were thousands of sensors, and our data collector was ingesting data at a very high rate, I mean in millions of events per second. So Alerting platforms need to provide real-time monitoring and alerts to the organization regarding the sensor's status/usage. To meet these requirements, Our platform should provide real-time streaming of data and ensure the accuracy of results.
What is Fast Data?
A few years ago, we remembered when it was just impossible to analyze petabytes of data. The emergence of Hadoop made it possible to run analytical queries on our vast amount of historical data. As we know, Big Data is a buzz for the last few years, but Modern Data Pipelines are always receiving data at a high ingestion rate. So this constant flow of data at high velocity is termed Fast Data. So, Fast data is not about just the volume of data like Data Warehouses, in which data is measured in GigaBytes, TeraBytes, or PetaBytes. Instead, we measure volume but concerning its incoming rate like MB per second, GB per hour, TB per day. So, volume and velocity are both considered when talking about fast data.
What is Fast Data Processing?
As explained earlier, architecture is becoming very popular for processing data with less overhead and more flexibility. So, our Data Pipeline should be able to handle data of any size and at any velocity. The platform should be intelligent enough to scale up and down automatically according to the load on the data pipeline. I remember a use case where we were building a Data Pipeline for a Data Science Company in which their data sources were various websites, mobile devices, and even raw files.
The main challenge we faced while building that pipeline was that data was coming at a variable rate, and also some raw files were too big. Then we realize that to support random data incoming rates, we need an automated way to detect the load on the server and scale it up/down accordingly. Also, we built a Customs Collector in which support files are in GB or even TB’s. So Idea behind that was the auto-buffering mechanism. We keep on varying our minimum and maximum buffer size depending on the scale of the raw file we receive.
Conclusion
Real-time data streaming operates by creating the use of constant queries that work on time and buffer windows. However, if we compare it with the traditional database model, data was stored and indexed for further processing. It is totally the opposite Real-time data streaming uses data while in motion within the server. To know more about real-time streaming data, we recommend talking to our expert.



























