
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What Is Data Lineage and Why Is It Critical for Modern Data Architecture?
When the info from the first person reaches the last person, it transforms into something altogether different. Employees are perplexed, as though they have no idea how the original data changed utterly. As an enterprise's data assets flow via its Data Architecture, this is also the case with poor Data Lineage. Customers, regulators, and enterprises find using a company's Big Data less entertaining even though it can overcome several challenges.
Businesses require compliant and secure data. This information must be available when and where it is needed. With multiple end-users, platforms, and sources in various formats, such as video, text, images, and audio, the need for clean Big Data becomes even more complicated. When Big Data is stored remotely, it becomes less clear how the data got there in the Cloud. Understanding Data Lineage addresses these and other issues.
The data lineage includes:
-
The origin of the data.
-
Each stop along the way.
-
An explanation of how and why the data has moved over time.
From source to final destination, the data lineage can be visually documented, including any stops, deviations, or changes along the way. This process makes operational aspects like day-to-day use and error resolution easier to track.
Key Takeaways
- Data lineage documents the complete path of data from source to destination — including all transformations, movements, and changes
- Enterprises use data lineage for error resolution, compliance reporting, system migration, and impact analysis
- Implementation requires metadata collection at every pipeline stage: ingestion, processing, query history, and data lakes
- Eight best practices govern effective lineage management — from automated extraction to end-to-end validation
- For CDOs and Analytics Leaders: Data lineage eliminates the manual investigation work that consumes data team capacity when reports conflict or audits are required — it is the foundation of a trusted, self-documenting data environment
- For Chief AI Officers: AI model outputs are only defensible when the data feeding them is traceable — lineage is the audit infrastructure that makes AI governance operational
What problem does Data Lineage solve?
Data Lineage helps organizations understand where data comes from, how it changes, and where it goes.
What Is a Data Lineage Example and How Does It Work?
Data lineage diagrams depict how data transforms and travels from source to destination throughout its complete data lifespan. A business lineage diagram is an interactive visualization that depicts the overall data flow from source to report without revealing all of the technical intricacies and adjustments. An information architect can use a technical data lineage diagram to see transformations, drill down into the table, column, and query-level Lineage, and traverse data pipelines.
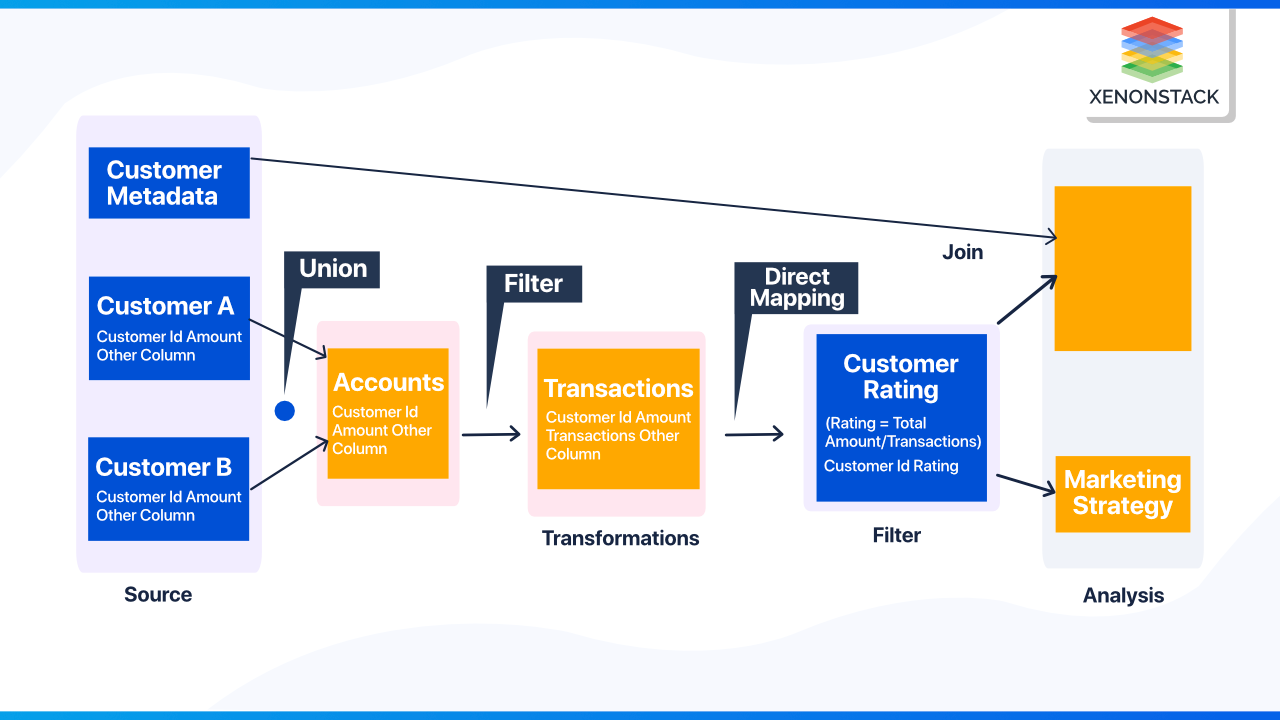
Let's understand with the help of an example that visualizes end-to-end data lineage at a high level with hops of the column - customer ID and how it can solve several related problems
-
Table Customer A and Customer B includes the column Customer ID and Amount
-
Table Accounts includes Customer ID and Amount for all customers
-
Table Transactions includes Customer ID, Total amount, and Number of Transactions per customer
-
Table Customer Rating includes Customer ID and Customer rating
-
Rewards include Customer ID, Customer Name, Customer Rating, and Reward
The Lineage, for example, starts with the Customer ID column in the Customer A and B tables and flows forward via the Accounts and Transaction Table to the Customer ID column in the Customer Rating table and then to corresponding columns in the Rewards and Marketing strategy table.
The above data lineage helps us ensure that data comes from trusted sources and that all the transformations have been applied correctly. In this case, it also influences the marketing team's strategic decision-making. If data operations aren't adequately tracked, data verification becomes nearly impossible, or at the very least, extraordinarily costly and time-consuming.
Why Do Enterprises Need Data Lineage?
The problem: Without data lineage, enterprises cannot verify the accuracy of their data, cannot trace the root cause of errors, and cannot provide the audit trails regulators require. Strategic decisions are made on data whose provenance is unknown.
Why the absence of lineage fails organizations:
- Error resolution requires manual investigation across disconnected systems — consuming significant IT and analyst time
- System migrations carry high risk without a map of data dependencies and transformation logic
- Regulatory audits (BCBS 239, GDPR, CCPA) require traceable data flows that manual documentation cannot reliably provide
- Data quality validation becomes costly and inconsistent when lineage is absent
What data lineage enables:
- Full data path visibility — from source to destination, including all intermediate transformations
- Error debugging — users can replay specific portions of data flow to identify where issues were introduced
- Impact analysis — IT can assess the downstream effects of any proposed data change at table, column, or report level, eliminating approximately 98% of manual impact analysis time
- Regulatory compliance — audit trails for BCBS 239, GDPR, and CCPA are documented automatically rather than reconstructed manually
- System migration confidence — complete dependency mapping reduces migration risk
Data meshes address the shortcomings of data lakes by giving data owners more autonomy and flexibility, allowing for more data experimentation and innovation, and reducing the burden on data teams to meet the needs of every data consumer through a single pipeline. Click to explore Adopt or not to Adopt Data Mesh? - A Crucial Question
How Is Data Lineage Implemented Across the Data Pipeline?
When developing a data lineage system, we must track every operation that changes or processes the data. At each data level, transformation must map data tables, views, columns, and reports, and the data must be tracked between databases and ETL operations.
Collect metadata from each step and put it in a metadata repository for lineage analysis to make this easier. Here's how Lineage is accomplished at various phases of the data pipeline:
-
Data Ingestion: Monitoring data flow inside data ingestion jobs and checking for errors in the mapping between source and destination systems or any mistakes in data transfer
-
Data Processing: Tracking the results of specific actions conducted on the data system, for example, reading a text file, applying filters, counting values from a specified column, and publishing the results to another table. Each level of data processing is examined independently for mistakes or security/compliance issues.
-
Query History: Keeping track of user queries and automatic reports generated by databases and data warehouses. Filters join, and other operations allow users to create new datasets successfully. It necessitates performing data lineage on critical queries and reports to verify the flow. Users can also use lineage data to assist them in improving their queries.
-
Data lakes: Identifying security or governance vulnerabilities by tracing user access to different objects or data fields. Due to the massive amount of unstructured data, these issues might be challenging to enforce in large data lakes.
What is required to implement Data Lineage?
Metadata collection, transformation tracking, and repository management.
What are the advantages of Data Lineage?
From IT to business, the entire organization can benefit from data lineage. It gives an organization's data the visibility and context it requires and allows IT to focus on strategic projects rather than manually mapping data. These advantages of data lineage enable businesses to:
Trust data and better understanding
Data lineage benefits the business user by providing the required context for an organization's data. It displays the source of your data, how data sets are produced and aggregated, the quality of data sets, and any alterations along the data journey.
Comply with regulations
Data traceability for regulatory purposes, such as BCBS239, CCPA, and GDPR, is challenging to map. It can take a long time, leading to fines and penalties if done incorrectly. Data lineage assists the Risk Management and Data Governance teams by documenting how data moves through various systems from source to destination and allowing risk management to observe the audit trail for all data transformations.
Save time doing manual impact analysis: When modifying data, data lineage allows IT to undertake impact analysis at a granular level (columnar, table, or business report) to observe any changes to downstream systems. It eliminates approximately 98 % of the time IT spends on manual analysis.
Data Observability abolishes the need for debugging in a respective deployment environment by monitoring the performance of applications.Explore here How Data Observability Drives Data Analytics Platform?
What are the best practices for data lineage?
The best practices of Data Lineage are described below:
1. Automate data lineage extraction
It was common practice for companies to document lineage manually. However, due to production's dynamic and fast-paced nature, manual tracking is no longer practicable. To engage with the fast-paced business environment, you must automate the process.
Best-in-class data catalogs are also advised to increase automation. They use AI and machine learning to aggregate metadata from many systems to create a logical lineage flow. It also can extract metadata and draw inferences from it.
2. Metadata Validation
Because data is always prone to errors, including the owners of various processes and tools in lineage tracing is critical. Owners are closest to and most aware of the details generated by their programmes. They can help point out defects or inaccuracies in records or procedures.
3. Inclusion of source metadata
It is critical to include the data generated by the many operations that process, transform, or transport the data while tracing data lineage. As a result, lineage tracking should include metadata established by these operations on the data.
4. Modifying and Updating the data
The data owner has unique control over the data. He should keep his information in a secure location where only those with authorization rights can access it. As a result, the owner knows who updates, utilises, and amends the data and who to contact if an issue arises.
5. Assigning a person To verify lineage
The proprietors of the tools and applications that generate metadata about your data understand how timely, accurate, and relevant the metadata is better than anyone else.
The data owner must properly transmit data handling rights to the person who must utilize it in the future. Data lineage assists the owner/analyst track who is actively utilizing and updating the data.
6. Progressive extraction and validation
To map the lineage as precisely as possible, it's best to record metadata in the order of the data pipeline stages. This results in a well-defined timeframe and a much more legible structure for the massive metadata log.
The high-level links can be validated first, making progressive validation of this data easy. Once they're evident, the deeper complexities can be evaluated level by level. While reading or extracting data, the progressive technique maintains a logical pattern and reduces errors.
Data quality is a measurement of the scope of data for the required purpose. It shows the reliability of a given dataset. Read more about Data Quality and its Challenges
7. Identifying and marking critical Data
In this case, the company must identify the relevance of data, keep track of it, and even separate the critical data. Strict policies should be created for any sensitive data to maintain and secure its secret.
8. End to end Lineage validation
Validate lineage in stages, beginning with high-level linkages between systems and moving on to related datasets, data items, and transformation documentation.
9. Storing the data
Many people believe that if we use data, we should destroy it. The organization must recognise that every aspect of data is critical. If not now, you may require the information in the future. To do so, you'll need to construct datasets that will aid in managing and tracking any additional data that is useful in conjunction with your primary data.
10. Use of data within the organization
Every business uses data multiple times to extract information and generate reports. The reports assist the organization in gaining insight into its operations and, as a result, making decisions. Suppose there is an issue in the report. In that case, an organization can discover the cause of the error by following data lineage best practices.
Data fabric is a dynamic approach to managing data. It's a sophisticated architecture that harmonizes data management standards and procedures across cloud, on-premises, and edge devices. Discover more about Big Data Fabric Implementations and Benefits
What are the techniques of Data Lineage?
Techniques for Data lineage are mentioned below:
Pattern-based Lineage
Instead of dealing with the code that alters the data, it employs patterns to execute Lineage. It searches for patterns in metadata to create a lineage. The essential advantage of this technique is that, unlike data lineage via parsing, pattern-based Lineage does not require knowledge of any programming language to process data. It keeps an eye on the data rather than the algorithms.
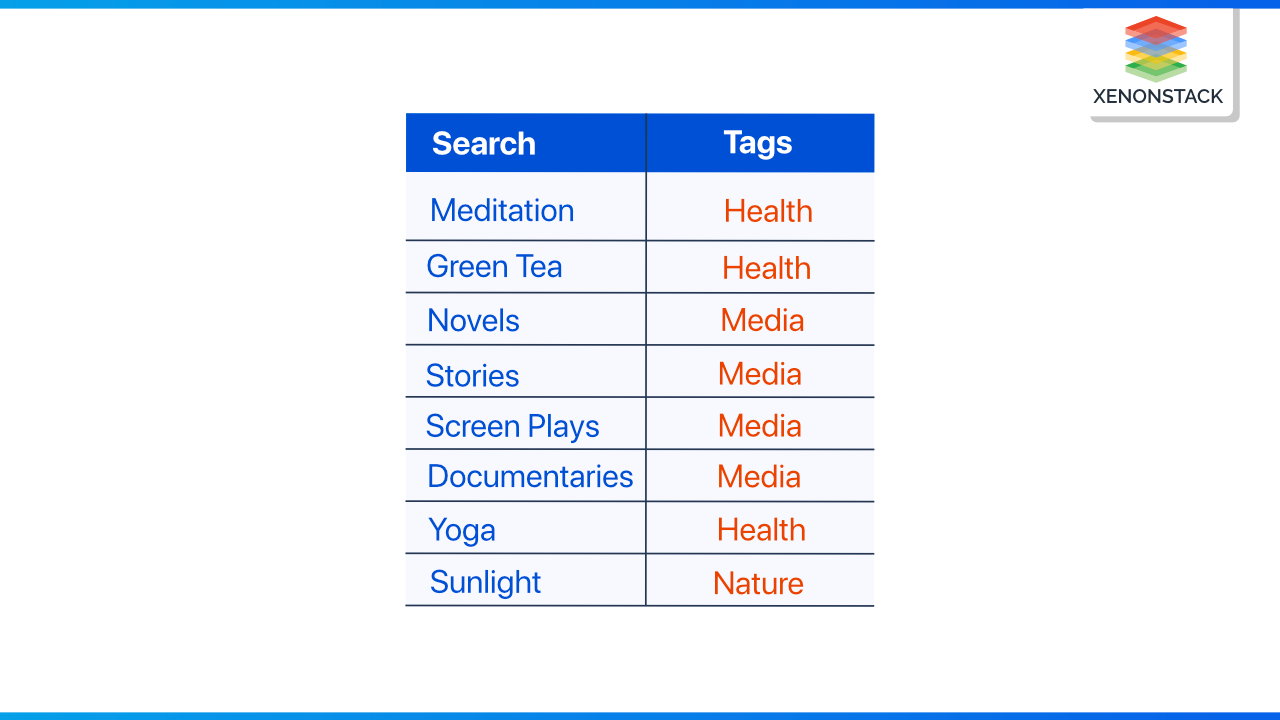
Lineage by data tagging
A transformation engine tags data that transforms or moves. The tag is then tracked to create a lineage representation from beginning to end. It only works, though, if you have a reliable transformation mechanism in place to manage all data flow.
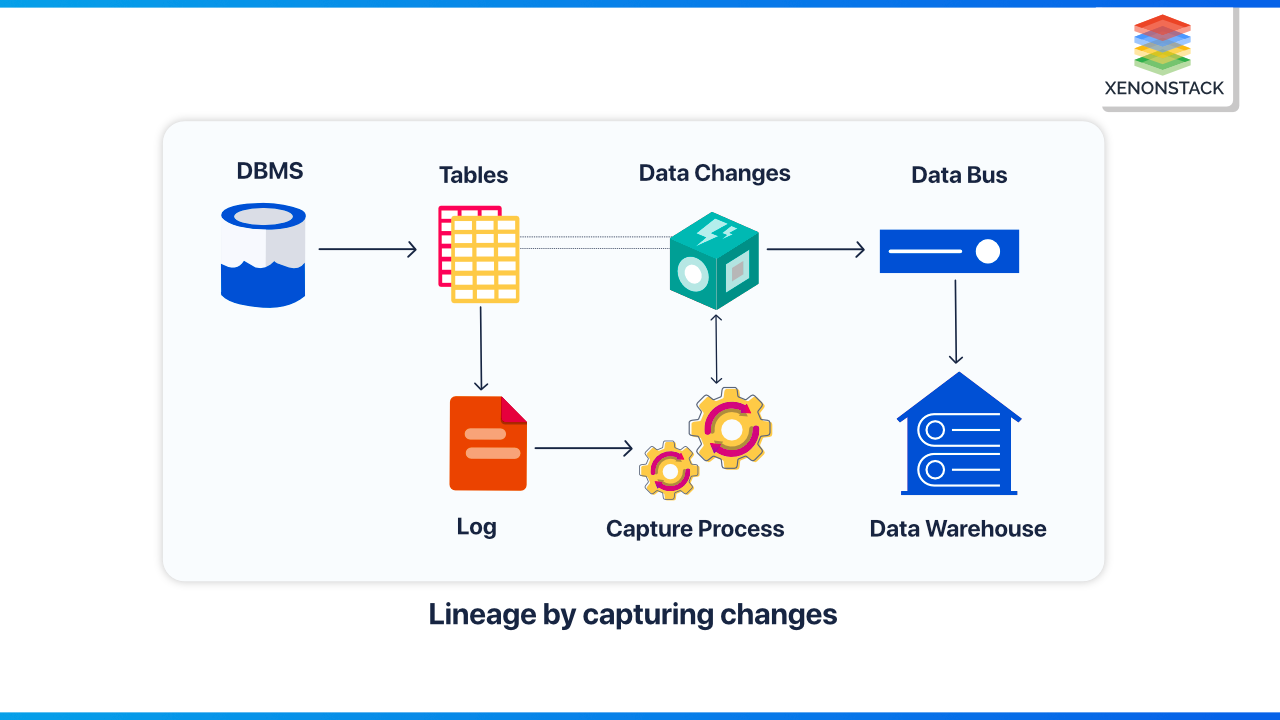
Lineage by parsing
It reads the logic used to process data automatically. Because it monitors data as it moves, this type of data lineage makes it simple to capture changes across systems. However, it does necessitate a thorough understanding of the programming languages and tools utilized throughout the data lifecycle.
What Are the Leading Data Lineage Tools?
| Tool | Positioning |
|---|---|
| Atlan | Collaborative data workspace with active metadata and lineage |
| Alation | Data catalog with machine learning-driven lineage and governance |
| OvalEdge | End-to-end data governance and lineage platform |
| Datameer | Cloud-native data transformation with lineage tracking |
| Trifacta | Data preparation with transformation-level lineage |
| Octopai | Automated metadata management and cross-platform lineage |
| Collibra | Enterprise data governance with integrated lineage capabilities |
| CloverDX | Data integration platform with built-in lineage documentation |
When evaluating tools, prioritize: automation capability, metadata intelligence, cross-system coverage, and governance integration.
What should you look for in a Data Lineage tool?
Automation, metadata intelligence, and governance support.
What Is the Future of Data Lineage?
As data engineering adopts DataOps and automation principles parallel to DevOps, high-quality lineage data will power a new generation of use cases: automated data pipeline testing, proactive impact analysis, and self-documenting data architectures.
Data lineage technology is positioned to augment and partially automate the work of the data engineer — reducing time spent on manual governance tasks and redirecting capacity toward value-creating activities. As data volumes continue growing exponentially across cloud, on-premises, and edge systems, organizations with mature lineage infrastructure will maintain governance control that manually managed environments cannot sustain.
Future capability directions:
- Automated lineage in DataOps pipelines — lineage generated as a byproduct of pipeline execution, not a separate documentation effort
- AI-enhanced metadata inference — machine learning constructs lineage connections across systems where explicit metadata is incomplete
- Use-case-driven lineage tools — purpose-built lineage capabilities embedded in compliance, quality, and observability workflows
How Should CDOs and Analytics Leaders Measure Data Lineage Performance?
Manual lineage coverage reports and tool deployment counts measure infrastructure presence — not operational value. The right measurement framework for data leaders connects lineage governance to compliance readiness, decision quality, and operational efficiency.
Four-Dimension KPI Framework for Data Lineage Performance:
| Dimension | Key Metrics | What It Measures |
|---|---|---|
| Lineage Coverage | Percentage of data assets with documented end-to-end lineage; pipeline coverage rate | Is the lineage infrastructure comprehensive enough to support governance? |
| Compliance Readiness | Audit trail completeness rate; regulatory response time; BCBS 239/GDPR documentation pass rate | Are lineage records sufficient to satisfy regulatory examination? |
| Operational Efficiency | IT manual impact analysis time reduction; error resolution cycle time; migration risk incidents | Is lineage reducing the operational burden on IT and data engineering? |
| Data Trust & Adoption | BI system trust score; percentage of decisions supported by traceable data; data discovery time | Is lineage improving confidence in data across the business? |
Portfolio-Level Metrics for CDOs, VPs of Data & Analytics, and Chief AI Officers:
- Lineage completeness rate — Percentage of enterprise data assets with full source-to-destination lineage documented and maintained
- Regulatory response time — Time from audit request to complete lineage documentation delivery; should decrease as automation matures
- Impact analysis acceleration — Reduction in IT time required to assess downstream effects of data changes (target: 95%+ reduction vs. manual baseline)
- AI traceability index — Percentage of AI/ML model training and inference datasets with documented, validated lineage
Data lineage is not a data engineering artifact — it is the audit infrastructure for enterprise AI. When a model produces an unexpected output, the first question regulators and business stakeholders ask is: what data produced this result, and can you prove it was accurate? Without lineage, that question cannot be answered. Build lineage coverage for all AI training and inference datasets before scaling model deployment — AI governance without data lineage is not governance.
Conclusion: Why Data Lineage Is Foundational Enterprise Infrastructure
Data lineage ensures traceability, compliance, trust, and governance across every system in the enterprise data architecture. It enables accurate decision-making, simplifies IT operations, reduces regulatory risk, and provides the visibility required to scale data and AI systems responsibly.
For CDOs, CAOs, VPs of Data & Analytics, and Chief AI Officers, the implication is direct: data lineage is not a documentation project — it is the operational backbone of a governed data environment. Organizations that automate and scale lineage coverage today build the traceability foundation that makes every downstream analytics, compliance, and AI initiative defensible.
Without data lineage, enterprises lose visibility. With data lineage, enterprises gain control.
- Read more about Augmented Data Management
- Discover here 7 Key Elements of Data Strategy



























