
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction
An Energy Analytics Company provides Predictive Analytics & Power Forecasting Solution to various Wind & Solar Farms worldwide. That is how their typical data lake architecture looks like. And while explaining the challenges faced during this journey, we will walk you through how we reach out to Data Mesh Architecture Patterns and How it solves the Major Data Platform Architecture Problems.
Data Mesh is not some kind of new technology or framework. It is just an idea of reusing an existing ecosystem of technology & tools in innovative ways to solve the enterprise's significant problems when they become a Proper Product Company from a Start-Up.
What is Data mesh ?
Data mesh creates a layer of connectivity that removes the complexities associated with connecting, managing, and supporting data access. It is a method of connecting data that is spread across multiple data silos.
Data as a Product
The concept of Centralized Storage for various kinds of entities integrated from different systems has become very popular in recent years. But it makes it very hard for DownStream Consumers to understand the data without the Data Catalog and Separate Team required to maintain the Data Catalog having Domain Knowledge.
But many fundamental principles are followed in Data Mesh while designing your Data Platform.
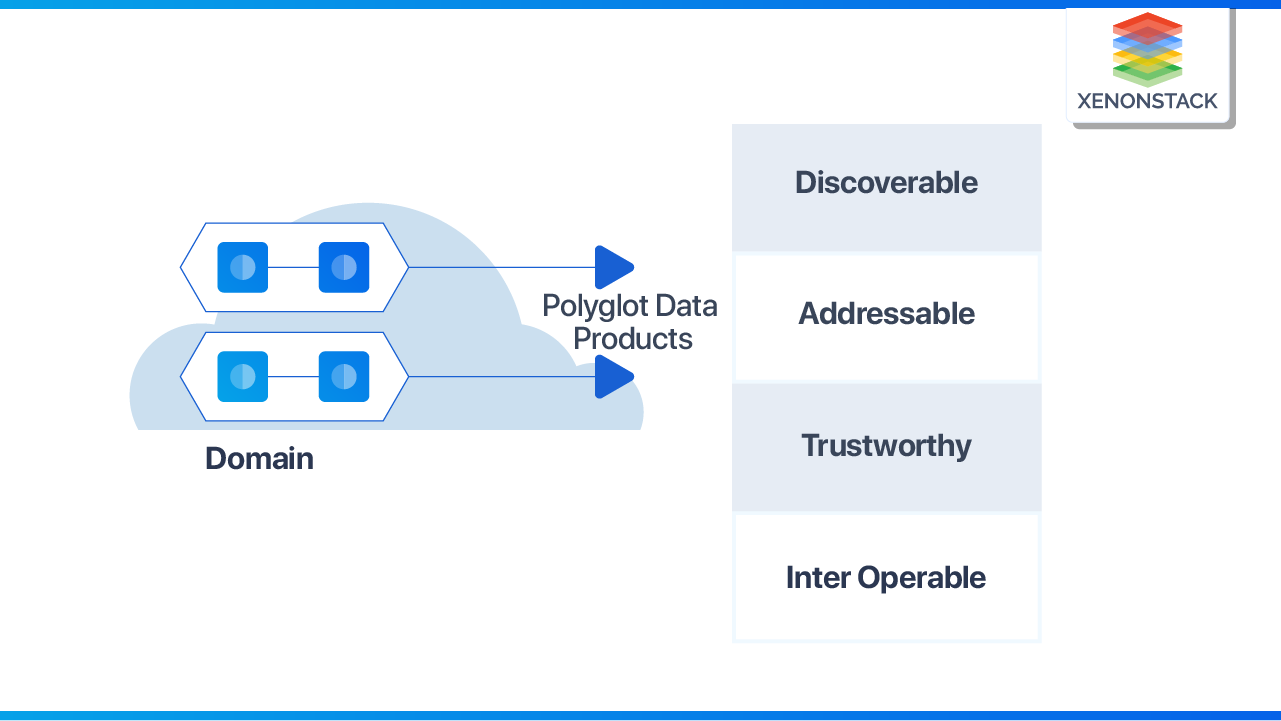
Discoverability
Once the data is available as a product, it must be discoverable through a data catalog; Each data product should have metadata information such as owner, lineage, source, and sample data. The data consumers teams should be able to register for easy discoverability of the data. The mind shift provides the data as a product in a discoverable fashion to the downstream teams.
Addressability
A data product should be available for accessing any information easily. The standard should be set for addressing the data. Under different domains, they might store and serve their data into other formats like CSV, serialized parquet format into s3, or they can store and access it through streams such as Kafka topics. But a common convention should be developed, which helps users to address it pragmatically.
Trustworthy
Without data truthfulness, data products have no meaningful use for analytics and other operations. The data owner must provide an acceptableSLOfor the data's truthfulness.
Also, how it is going to reflect the real-time scenario and the insights that have been generated based on those data points. Automated data integrity testing can help provide acceptable data quality at the time of creating a data product. Providing data lineage as metadata with data products helps users gain confidence in data integrity.
Interoperability
In distributed domain data architecture, the key concern is to have interoperability between domains. Users should correlate data across different domains and insightfully stitch them using joins, filters, aggregates, etc. There should be standards sets for type formatting, identifying common metadata fields, and dataset address conventions to enable interoperability in polyglot domains.
Domain-Driven Data Models
Microservices Architecture allows Product Teams to break their overall Solution into a Group of different independent/interconnected services, making it more manageable.
Similarly, While Defining Storage Architecture, Instead of going for a common database kind of approach, it makes sense to segregate your storage into different domains and define the Data Lake Entities accordingly. It will help the BI & Analytics Team see the other Data Domains available instead of spending their own time understanding the same.
Cross-Functional Data Engineering Teams
Microservices Architecture inspires us to split our Data Engineering Team into sub-teams having complete domain knowledge of the datasets they produce, transform, and serve to analytics teams. This Team Structure will help different sub-teams focus on their respective domains easily and also becomes easy to collaborate between cross teams elegantly.
Clear Ownerships & Governance of DataSets
Once the Data Platform Teams have a clear understanding of What they are ingesting, it eases the process to define the datasets' ownerships. Instead of a Centralized Governance Approach, Data Mesh Architecture makes it easy to define Data Governance Policies.
Challenges in Current Architecture
Lack of Domain Knowledge in Data Platform Team
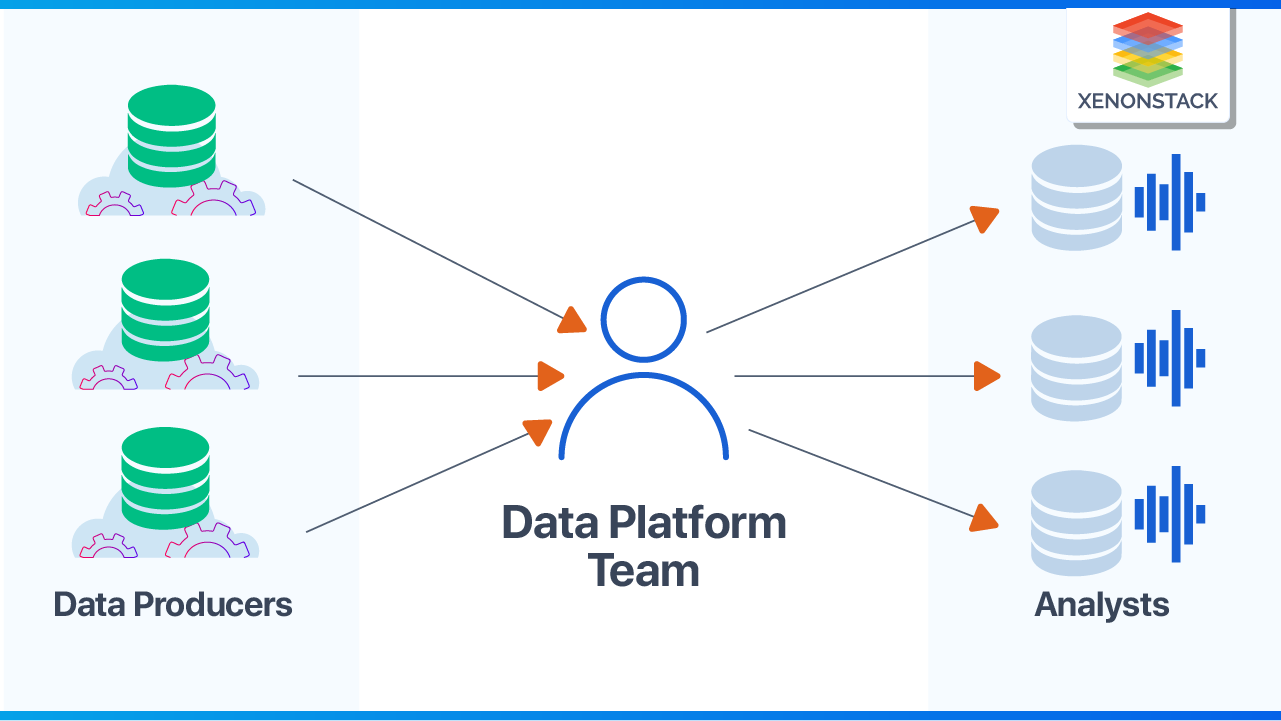
Typically, Data Engineers focus on just bringing the data from whatever Data Sources and working with the BI & Analytics Team and understanding their Usage Patterns and defining the Data Lake Structure.
However, Data Engineering doesn't have that Domain Knowledge for given datasets. Once that data reaches the Analytics Team, Data loses its context. It can happen that the Data Platform Team has created its own version of Data Sets in Data Lake or Warehouse according to their understanding.
Data Platform Team becoming Bottle Neck for Serving Data with Context
Many times it happens, Customers want to expose their data to the Analytics Team, and both Customer & Analytics teams understand the data's context. But the Engineering Team doesn't have much idea of the Data Domain. And for bringing the data into the Data Lake in reading Optimised Format becomes challenging, then traditional KT session starts between Customer, DE, and Analytics Team for designing storage for Data Lake to make data available for BI & Analytics Teams.
Lack of Ownership of DataSets in Centralized Data Platform
Traditional Data Lake Architecture uses ETL/ELT Processes to bring data into the Platform and Data Platform Teams, entirely focusing only on building those Data Lake Tables and Exposing the Datasets to the Analytics Team through some MetaStore ( or using Catalog nowadays). But the question is Who will take ownership of those datasets, which means who can guide the DownStream Teams that What that Data means and how it needs to be used.
Lack of Domain-Driven Data Quality
Nowadays, many Data Quality Tools and Frameworks can help us profile our data and understand their quality. But this isn't enough for the Analytics Team because, along with Basic Data Quality Metrics, they have many Domain-Specific different aspects of defining Data Quality.
Adopt or not to Adopt Data Mesh?
The adoption of the Data mesh is dependent on the following factors in the organization.
Number of data sources
Take the data number of data sources into consideration before ramping up for the Data Mesh. How many data sources do you have in the organizations.
Team size
What is the size of the team? Size of the data scientists, Data Engineering team.
Data Domain Quantity
How many products the company owns. Do other team marketing or sales teams rely on the data to decide on it?
Bottleneck
Its data engineering team is a bottleneck in implementing any new product.
A Fundamental Shift
To move from traditional data architecture to data mesh need to consider some fundamental shifts.
|
FROM |
TO |
|
Centralized ownership |
Decentralized ownership |
|
Pipelines as a first-class concern |
Domain data as a first-class concern |
|
Data as by-product |
Data as Product |
|
Solid Data Engineering Team |
Cross-Functional Domain data teams |
|
Centralized data lake |
An Ecosystem of data products |
Typical Data Lake Architecture
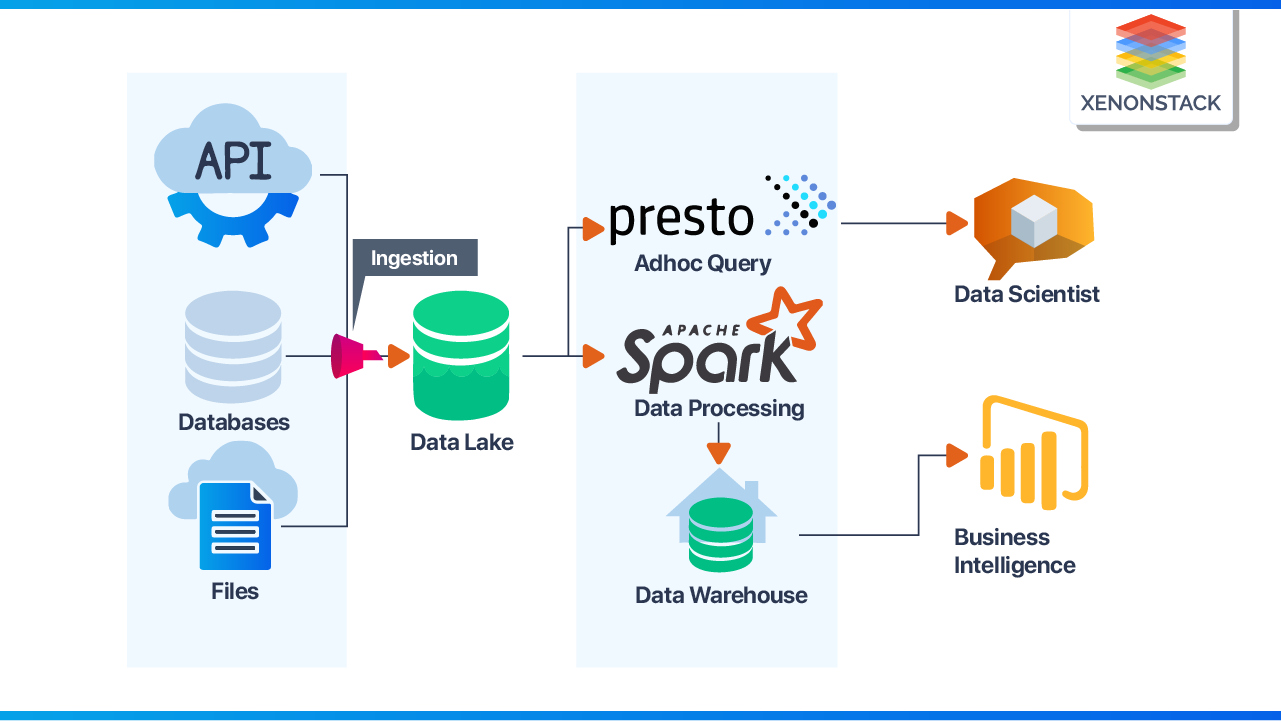
Almost Every Data Platform company is working around the above architecture pattern. When different Enterprises reach a stage of serving customers of Different Domains, they will find their basic Team Structure & Architecture Approach principles non-scalable.
Usually, The Data Ingestion Team brings data into Data Lake. The Engineering & Analytics Team defines Standard Data Structure for LakeHouse / Warehouse and processes & transforms the data into read optimized format.
So, Generally, three teams are working across :
Data Ingestion:Dedicated Team for the integration of Customer Data Sources
Data Platform:Maintains Data Platform including Data Lake, Warehouse, Marts, Governance, Catalog
Analytics Team:Responsible for deciding based on Data, i.e., Business Intelligence & Data Science Team
Conclusion
Data meshes address the shortcomings of data lakes by giving data owners more autonomy and flexibility, allowing for more data experimentation and innovation, and reducing the burden on data teams to meet the needs of every data consumer through a single pipeline.


























