
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Data Lake
If you are looking for an enterprise-level solution to reduce the cost and complexity of big data, using Data Lake services is the best and most cost-efficient solution. Moreover, it is easy and self-service management that requires little to no coding. Data Ingestion with Apache NiFi for Data Lake delivers easy-to-use, powerful, and reliable solutions to process and distribute data over several resources. NiFi works in both standalone mode and cluster mode. Apache NiFi is used for routing and processing data from any source to any destination. The process can also do some Data Transformation. It is a UI-based platform where we need to define our source from where we want to collect data, processors for converting the data, and a destination where we want to store the data.
Big Data Analytics and Ingestion: Unleashing the Power of Data Collection
In today's fast-paced world, enterprises harness the power of data from various sources to build real-time data lakes. But how do we seamlessly integrate these diverse sources into one cohesive stream? The solutions to these challenges have been extensively discussed and articulated in this blog. We delve into the art of data ingestion, storage, and processing, specifically focusing on leveraging Apache Nifi to handle Twitter data. Stay tuned for upcoming blogs where we explore data collection and ingestion from various sources:
-
Data ingestion From Logs
-
Data Ingestion from IoT Devices
-
The Data Collection and Ingestion from RDBMS (e.g., MySQL)
-
Data Collection and Ingestion from Zip Files
-
The Data Collection and Ingestion from Text/CSV Files
What are the Objectives of Data Lake for Enterprise?
Below are the objectives of the enterprise data lake
-
Central Repository for Big Data Management.
-
Reduce costs by offloading analytical systems and archiving cold data
-
Testing Setup for experimenting with new technologies and data
-
Automation of Data pipelines.
-
Metadata Management and Catalog
-
Tracking measurements with alerts on failure or violations
-
Data Governance with a clear distinction of roles and responsibilities
-
Data Discovery, Prototyping, and experimentation
Apache NiFi and its Architecture
Apache NiFi provides an easy-to-use, powerful, and reliable system to process and distribute data over several resources. NiFi helps to route and process data from any source to any destination. The process can also do some data transformation. It is a UI-based platform where we need to define our source from where we want to collect data, processors for converting the data, and a destination where we want to store the data. Each processor in NiFi has some relationships like success, retry, failed, invalid data, etc., which we can use while connecting one processor to another. These links help transfer the data to any storage or processor even after the failure of the processor.

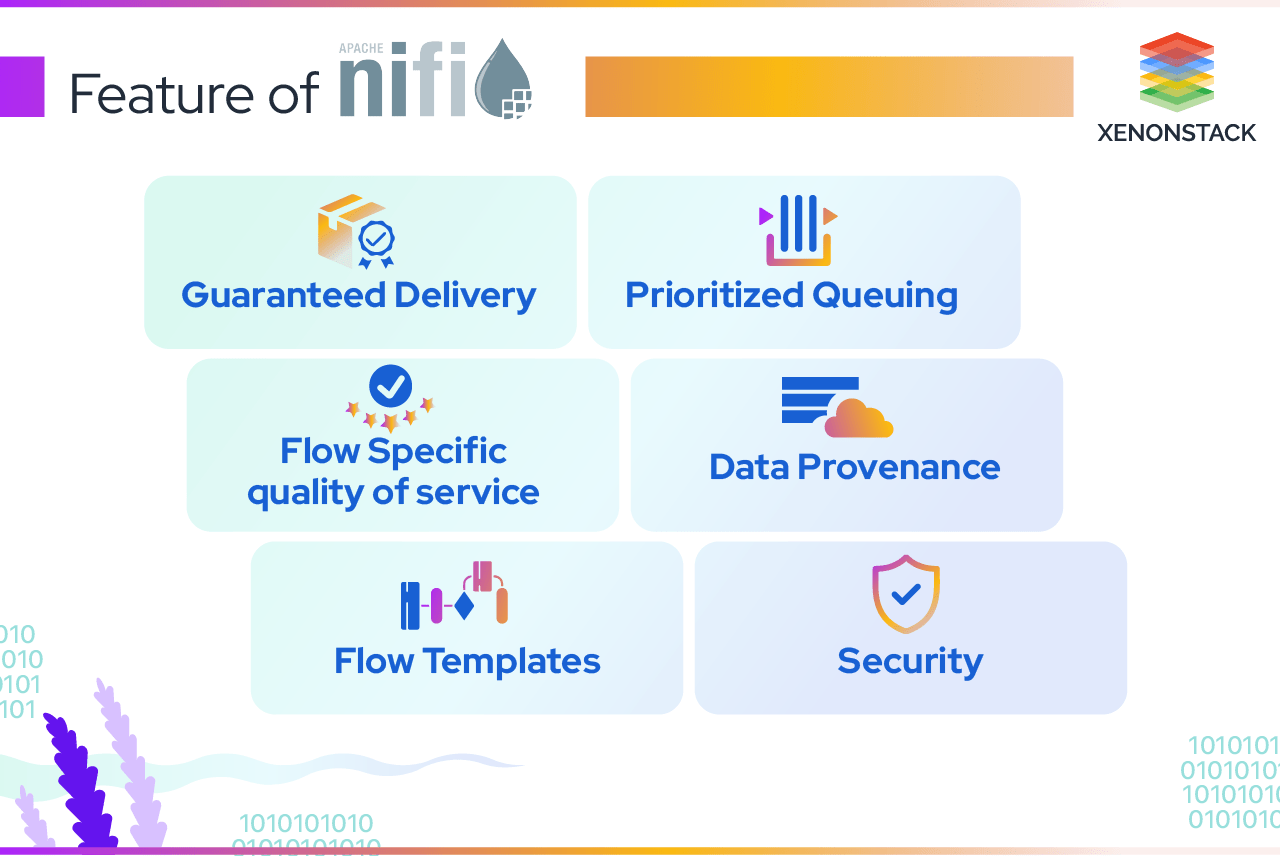
Features of Apache NiFi
1. Guaranteed Delivery
A core philosophy of NiFi has been that guaranteed delivery is a must, even at a vast scale. It is achievable by using a purpose-built persistent write-ahead log and content repository.
2. Data Buffering / Back Pressure and Pressure Release
Apache NiFi supports buffering of all queued data and the ability to provide back pressure as those lines reach specified limits or to an age of data as it gets a specified period.
3. Prioritized Queuing
Apache NiFi allows setting one or more prioritization schemes for how to retrieve data from a queue. The default is oldest first, but it can be configured to pull the newest first, most significant first, or another custom scheme.
4. Flow Specific quality of service
There are points of a data flow where the data is critical and less intolerant. Sometimes, it must be processed and delivered within seconds to be of any value. Apache NiFi enables the fine-grained flow of particular configurations of these concerns.
5. Data Provenance
Apache NiFi automatically records, indexes, and makes available provenance data as objects flow through the system, even across fan-in, fan-out, transformations, and more. This information is critical in supporting compliance, troubleshooting, optimization, and other scenarios.
6. Recovery / Recording a rolling buffer of fine-grained history
Apache NiFi’s content repository is designed to act as a rolling history buffer. As Data ages off, please remove it from the content repository or as space is needed.
7. Visual Command and Control
Apache NiFi enables the visual establishment of data flows in real-time. And provide a UI-based approach to building different data flows.
8. Flow Templates
It also allows us to create templates of frequently used data streams. It can also help migrate the data flows from one machine to another.
9. Security
Apache NiFi supports Multi-tenant Authorization. The authority level of a given data flow applies to each component, allowing the admin user to have a fine-grained level of access control. It means each NiFi cluster can handle the requirements of one or more organizations.
10. Parallel Stream to Multiple Destination
With Apache NiFi, we can move data to multiple destinations simultaneously. After processing the data stream, we can route the flow to the various destinations using NiFi’s processor. It can be helpful when we need to back our data on multiple goals.
What is Apache NiFi Clustering?
When dealing with large volumes of data, a single instance of Apache NiFi may not be sufficient to handle the workload effectively. To address this issue and improve scalability, NiFi servers can be clustered. Creating a data flow on one node makes it possible to replicate this flow on every node in the cluster. With the introduction of the Zero-Master Clustering paradigm in Apache NiFi 1.0.0, the previous concept of a single "Master Node" has been replaced. In the past, if the master node were lost, data would still flow, but the application could not display the flow's topology or statistics. However, Zero-Master clustering can make changes from any cluster node, providing greater flexibility and resilience.
Each node has the same data flow, so they work on the same task as the others, but each operates on different datasets. In the Apache NiFi cluster, one node is elected as the Master (Cluster Coordinator), and another sends heartbeats/status information to the master node. This node is responsible for the disconnection of the other nodes that do not send any pulse/status information. This election of the master node is done via Apache Zookeeper. When the master nodes disconnect, Apache Zookeeper elects any active node as the master node.
1. Building Data Lake using Apache NiFi
Building a Data Lake using Apache Nifi required the following:-
Amazon S3
-
Amazon Redshift
-
Apache Kafka
-
Apache Spark
-
ElasticSearch
-
Apache Flink
-
Apache Hive
AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals.
2. Fetching Tweets with NiFi’s Processor
NiFi’s ‘ GetTwitter’ processor is used to fetch tweets. It uses Twitter Streaming API to retrieve tweets. In this processor, we need to define the endpoint we need to use. We can also apply filters by location, hashtags, and particular IDs.
i. Twitter Endpoint
Here, we can set the endpoint from which data should get pulled. Available Parameters :
ii. Sample Endpoint
Fetch public tweets from all over the world.
iii. Firehose Endpoint
This is the same as streaming API, but it ensures 100% guaranteed delivery of tweets with filters.
iv. Filter Endpoint
If we want to filter by any hashtags or keywords
v. Consumer Key
Consumer key provided by Twitter.
vi. Consumer Secret
Consumer video by Twitter.
vii. Access Token
Access Token provided by Twitter.
viii. Access Token Secret
Twitter provides Access Token Secret.
ix. Languages
Languages for which tweets should fetch out.
x. Terms to Filter
Hashtags for which tweets should fetch out.
xi. IDs to follow
Twitter user IDs that should be followed.
The processor GetTwitter is now ready to transmit the data(tweets). From here, we can move our data stream anywhere, like Amazon S3, Apache Kafka, ElasticSearch, Amazon Redshift, HDFS, Hive, Cassandra, etc. NiFi can transfer data to multiple destinations parallelly.
3. Data Lake using Apache NiFi and Apache Kafka
For this, we are using the NiFi processor ‘PublishKafka_0_10’. In the Scheduling tab, we can configure how many concurrent tasks to execute and schedule the processor. In the Properties Tab, we can set up our Kafka broker URLs, topic names, request sizes, etc. It will write data on the given topic. For the best results, we can create a Kafka topic manually of defined partitions. Apache Kafka processes data with Apache Beam, Flink, and Spark. Data Lake Services are designed to preserve all attributes, especially when the scope of the data is unknown.
Integrating Apache NiFi to Amazon Redshift using Amazon Kinesis
Now, we integrate Apache NiFi into Amazon Redshift. NiFi uses Amazon Kinesis Firehose Delivery Stream to store data to Amazon Redshift. This delivery Stream should be utilized for moving data to Amazon Redshift, Amazon S3, and Amazon ElasticSearch Service. We need to specify this while creating the Amazon Kinesis Firehose Delivery Stream. We must move data to Amazon Redshift and configure Amazon Kinesis Firehose Delivery Stream. While delivering data to Amazon Redshift, firstly, the data is provided to the Amazon S3 bucket.
Then, the Amazon Redshift Copy command is helpful to move data to the Amazon Redshift Cluster. We can also enable data transformation while creating a Kinesis Firehose Delivery Stream. In this, we can back up the data to another Amazon S3 bucket other than an intermediate one. So, for this, we will use the processor PutKinesisFirehose. This processor will use the Kinesis Firehose stream to deliver data to Amazon Redshift. Here, we will configure AWS credentials and Kinesis Firehose Delivery Stream.
Big Data Integration Using Apache NiFi to Amazon S3
PutKinesisFirehose sends data to both Amazon Redshift and Amazon S3 as the intermediator. If someone only wants to use Amazon S3 as storage, NiFi can only send data to Amazon S3. For this, we need to use the NiFi processor PutS3Object. In it, we have to configure our AWS credentials, bucket name, path, etc.
Partitioning in Amazon S3 Bucket
The most important aspect of storing data in S3 is partitioning. Here, we can partition our data using expression language in the object key field. So, Right now, we have used day-wise partitioning. So tweets should be stored in the days folder. And this partitioning approach can be beneficial while doing Twitter analysis. Suppose we want to analyze tweets for this day or this week. So, using partitioning, we don’t need to scan all the tweets we stored in S3. We will define our filters using partitions.Data Lake Services using Apache NiFi to Hive
For transferring data to Apache Hive, NiFi has processors - PutHiveStreaming, for which the incoming flow file is expected to be in Avro format, and PutHiveQL, for which incoming FlowFile is projected to be the HiveQL command to execute. Now, we will use PutHiveStreaming to send data to Hive. We have output data as JSON for Twitter, so we need to convert it first to the Avro format, and then we will send it to PutHiveStreaming. In PutHiveStreaming, we will configure our Hive Metastore URI, Database Name, and table name. For this, the table we use must exist in the Hive.
1. Defining ElasticSearch HTTP-basic
For routing data ElasticSearch, we will use the NiFi processor PutElasticSearchHttp. It will move the data to the defined ElasticSearch index. We have set our ElasticSearch’s URL, index, type, etc. Now, this processor will write data Twitter data to the ElasticSearch index. Firstly, we need to create the index into ElasticSearch and manually map fields like ‘created_at’ because we need this to type ‘Date.'
2. Big Data Visualization in Kibana for Data Lake Services
Implementing Big Data Visualization in Kibana is fo
How do you integrate Apache Spark and NiFi for Data Lake Services?
Apache Spark is widely used for processing large amounts of data in batch and streaming modes. Site-to-site communication is employed when transmitting data from Apache NiFi to Apache Spark. The output port plays a crucial role in publishing data from the source. In the data flow mentioned above, we have utilized the TailFile processor to configure the 'nifi-app.log' file for tailing. This ensures that all the relevant information is sent to the output port, ready to be consumed by Spark. This output port can be leveraged while writing Spark jobs, enabling seamless integration between Apache NiFi and Apache Spark. Similarly, we can send out Twitter records to any output port, extending the possibilities for Spark streaming.
How do you integrate Apache Flink with Apache NiFi for Data Lake?
It is an open-source stream processing framework developed by the Apache Software Foundation. We can use this for stream processing, network/sensor monitoring, error detection, etc. We have tested the data transmission to Amazon S3 and Kafka. NiFi to Apache Flink data transmission also uses site-to-site communication. The output port helps publish data from the source.
-
NiFiSink to push data to the NiFi input port
-
NiFiDataPacket to represent data to/from NiFi
How Can XenonStack Help You?
XenonStack provides Data lake Services for building Real-time and streaming Big Data Analytics applications for IoT and Predictive analytics using Cloud Data Warehouse for enterprises and Startups.
- Discover more about Unified Data Ingestion Solutions
- Explore here about Data Integration Pattern Types



























