
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Data Pipelines
In today's world, organizations are moving towards data-driven decisions making. They are using data to create applications that can help them to make decisions. Data helps them to improve their productivity and revenue by working on the business challenges. Using data, organizations get to know the market trends, customer experience and can take actions accordingly.
But, It is not always possible, data that they need, placed at only one location. The data they need may be placed at several locations; therefore, they need to approach several sources to collect data. That is a time-consuming process as well as a complicated task as the data volume increases.
To solve these issues, they require Data Pipeline to have data available that can be used to get insights and make decisions. Data Pipeline helps to extract data from various sources and transform them to use it. Data pipelines can be used to transfer data from one place to another, ETL (Extract-Transform-Load), ELT (Extract-Load-Transform), data enrichment, and real-time data analysis.
What is a Data Pipeline?
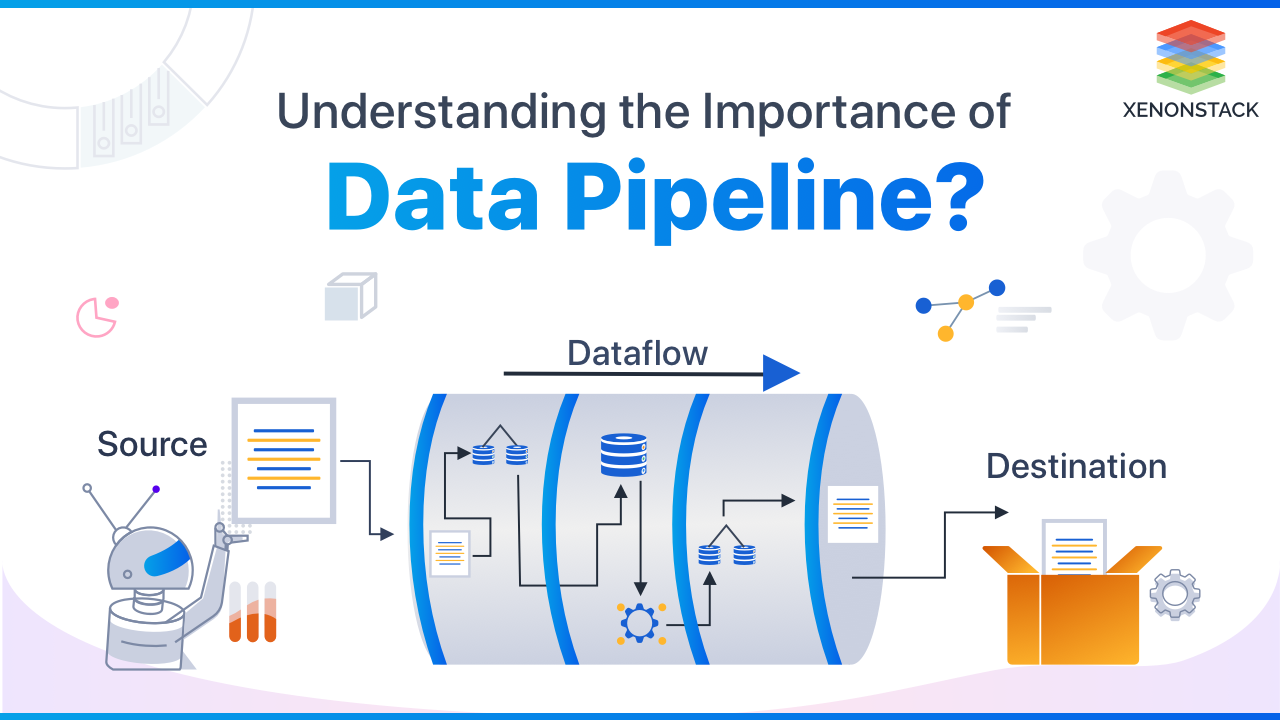
Data Pipeline is a series of steps that collect raw data from various sources, transform, combine, validate, and transfer them to a destination. It eliminates the manual task and allows the data to move smoothly. Thus It also eliminates manual errors. It divides the data into small chunks and processes it parallelly, thus reducing the computing power.
Types of Data Pipelines
According to the purpose, there are different types of data pipeline solutions. Such as:
- Real-time: This is valuable to process data in real-time. Real-time is useful when data is processed from a streaming source such as financial markets.
- Batch: Rather than real-time data, when organizations want to move a large volume of data after a regular interval, the Batch process is optimized. Such as to timely monitor marketing data for analysis in other systems.
- Cloud-native: It can be used when they work with cloud data such as data from AWS bucket. This can be hosted in the cloud, thus allowing to save money on infrastructure because otherwise, organizations rely on the infrastructure for hosting the pipeline.
- Open source: Open-source data pipelines are alternative to commercial vendors. These are cheaper than their commercial counterparts (peer). But to use these tools and expertise is required to be used if organizations have the expertise to develop and extend their functionality.
Components of Data Pipeline:
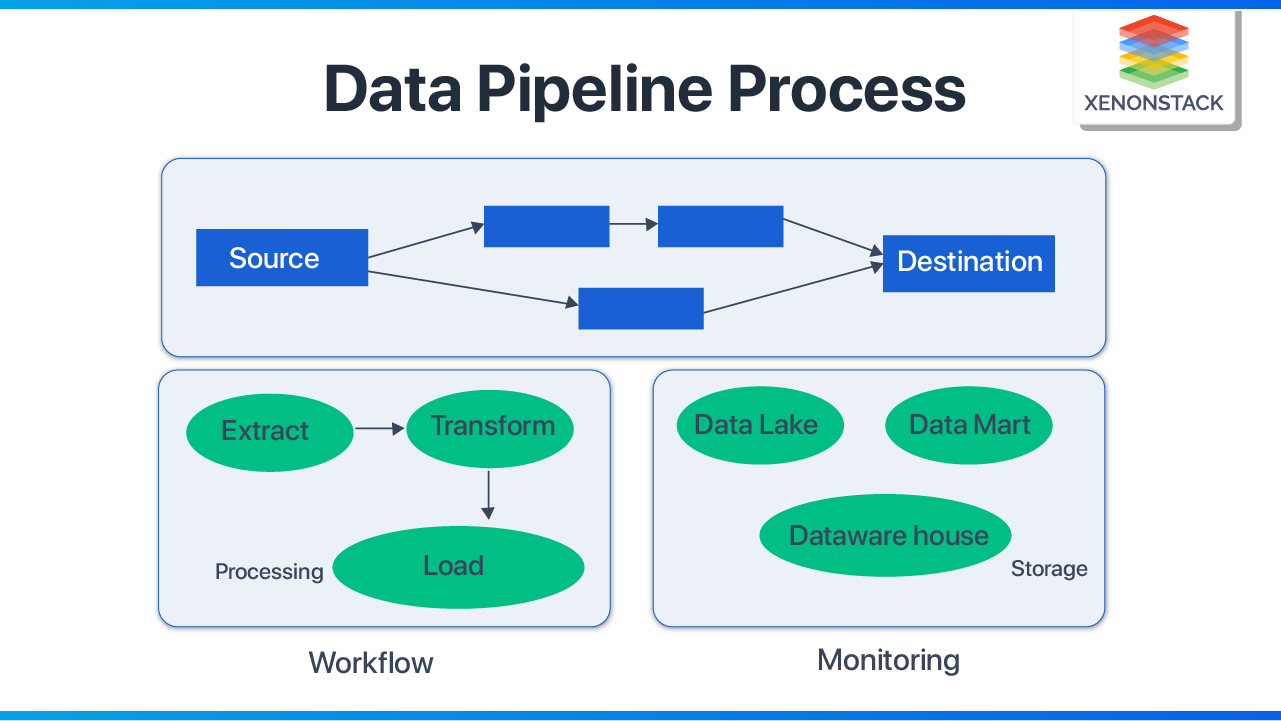
Let's discuss the components of the data pipeline to understand its work that how does it make and move data:
-
Source: The data pipeline collects the data from the data source; it can be a source of generation or any data storage system.
-
Destination: This is the point where data to be transferred. The destination point depends on the application for which data is extracted. It can be an analytics tool or a storage place.
- Data flow: When Data moves from source to destination, that process is known as Data flow. ETL (Extract, Transform, and Load) is one of its examples.
- Processing: This is a data flow implementation that determines how data is to be extracted, transformed, and stored as we have various methods for implementing them.
- Workflow: It decides the sequence of processes and monitors their dependency. It makes sure that upstream(ingestion of data) must be completed before downstream( transfer of data).
- Monitoring: Consistent monitoring is required for data health, consistency, and loss. It also monitors the speed and efficiency of the pipeline depending on the data volume.
A data mesh is a type of decentralised data architecture that organises data by business domain.Read more about to Adopt or not to Adopt Data Mesh? - A Crucial Question
The Elements of a Data Pipeline
Let's look at the significant components of a typical data pipeline to see how they prepare massive datasets for analysis. These are the following:
The origin
A pipeline extracts data from these locations. Relational database management systems (RDBMS), customer relationship management systems (CRMs), enterprise resource planning systems (ERPs), social media management tools, and even IoT device sensors are examples.
Destination
This is the data pipeline's endpoint, where all of its extracted data is dumped. A data pipeline's final destination is frequently a data lake or a data warehouse, which is kept for analysis. That isn't always the case, though. Data can be supplied directly into data visualization tools for analysis.
Information Flow
As data moves from source to destination, it changes. Dataflow is the term for the movement of data. ETL, or extract, transform, and load, is one of the most prevalent dataflow methodologies.
Preparation
Steps involved in extracting data from various sources, altering it, and transporting it to a specific location. A data pipeline's processing component determines how data flow should be implemented. What extraction procedure should be utilized for ingesting data, for example. Batch processing and stream processing are two typical ways of extracting data from sources.
Processes
Workflow is concerned with how jobs in a data pipeline are executed and their interdependence. When a data pipeline runs, it is determined by its dependencies and sequencing. In most data pipelines, upstream activities must be completed successfully before downstream jobs may begin.
Monitoring
To ensure data correctness and prevent data loss, a data pipeline must be monitored on a regular basis. A pipeline's speed and efficiency are also checked, especially as the bulk of the data grows higher.
Why is Data Pipeline Important?
-
The Data Pipeline is important when the data is stored at different locations, their combined analysis is required. For instance, there is a system for e-commerce that requires the user's personal and product purchase data to target the customers. Therefore, it needs a data pipeline to collect data from CRM (where the user's data is saved) and website data regarding their purchase, order, and visit data.
-
It may be possible that there is a large volume of data, and analysis applications are also very large and complex. It may be possible that using the same system for analysis where data generated or present slows down the analysis process. As a result, reducing the effect on the performance of the service data pipeline is required.
-
When analysis and production teams are different, user organizations do not want the analysis team to access the production system. In this case, it is not necessary to share the whole data with the data analyst.
To reduce the interruptions to automate the process so that every time does not have to collect data manually whenever it is required.
Challenges of Data Pipelines
The challenges of Data Pipelines are listed below:
Data Migration
- Depending on data consumption, enterprises may need to migrate their data from one place to another. Many companies run batch jobs at night time to take advantage of non-peak hours compute resources. Therefore, you see yesterday’s data as of today’s data, making real-time decisions impossible.
- Apache Kafka tends to be preferred for large-scale data ingestion. It partitions data so that producers, brokers, and consumers can scale automatically as workload and throughput expand.
Auto Scaling of Data Processing and Data Storage
- Today’s data volume and velocity can render your approach to import data in isolated, all-or-nothing atomic batches. The best solution is a managed system that provides automatic scaling of data storage and worker nodes. It will provide ease at managing the unforeseeable workloads of different traffic patterns.
- For example, in the case of Kinesis Data Stream, a CloudWatch alarm watches Kinesis Data Stream shard metrics, and a custom threshold of the alarm is set up. The alarm threshold is reached as the number of requests has grown and the alarm is fired. This firing sends a notification to an Application Auto Scaling policy that will scale up the number of kinesis data stream shards.
- Another example is the auto-scaling of data processing. In the case of Lightweight ETL like Lambda Pipeline, AWS Lambda will create an instance of the function the first time you invoke a lambda function and run its handler method. Now, if the function is invoked again while the first event is being processed, Lambda initializes another instance, and the lambda function processes two events concurrently. As more events come in, the lambda function creates new instances as needed. As the requests decrease, Lambda releases the scaling capacity for other functions.
- In the case of Heavyweight ETL like Spark, the cluster can scale up and down the processing unit (Worker Nodes) depending upon the workload.
Optimized Reads and Writes of Data in Pipeline Process
- The performance of the pipeline can be enhanced by reducing the size of the data you are ingesting, that is, ingesting only necessary raw data and keeping the intermediate data frames compact. Reading only useful data into memory can speed up your application.
- It is equally important to optimize the writes of data you perform in the pipeline. Writing less output into the destination source also improves the performance easily. This step often gets less attention. The data written to data warehouses are mostly not compact. It will not only help to reduce the cost of data storage but also the cost of downstream processes to handle unnecessary rows. So, tidying up your pipeline output spreads performance benefits to the whole system and company.
Data Caching and Configs for Smooth Functioning of Pipeline Runs
- Through data caching, the outputs or downloaded dependencies from one run can be reused in later runs, thereby improving the build time. It will help in reducing the cost to recreate or redownload the same files again. It is helpful in situations where at the start of each run, the same dependencies are downloaded again and again. This is a time-consuming process involving a large number of network calls.
Data-driven decision-making allows organizations to take strategic decisions and actions that align with their objectives and goal at the right time.Click to explore: Azure Data Factory vs. Apache Airflow
Best practices of Data Pipelines
The best practices of Data Pipelines are mentioned below:
Choosing the Right Data Pipeline
The first step is to recognize which pipeline you need for data handling. There are three types of pipelines:
- Continuous Pipeline - Continuous Pipeline should be used whenever we require continuous processing of data for making it available for real-time analytics. For example, in Spark Streaming, live input data streams are received and divided into batches. Spark engine processes the data and generates the final results of the stream in batches. The user has to pay for computing 24*7 even if no data is received from their data sources.
- Event-Driven Pipeline - It is a serverless compute service. It gets triggered when an event arrives. For example, in the case of AWS Lambda, the handler method is triggered each time an event arrives. The user is charged based on the number of requests for their functions and the duration it takes to execute the code. The user only has to pay when new data arrives from their Data Source.
- Batch Pipeline - This type of approach can be adopted when analytics or end consumers don’t bother about the data latency. It is mostly suitable for building Data Lakes used for Data Analysis, Model Training, Hindcasting, etc.
-
Serverless Data Pipeline should be preferred while choosing the data pipeline as it helps in cost optimization.
Parallelizing the Data flow
-
Concurrent data flow can save considerable time instead of sequential data runs. Concurrent data flow is possible if the data doesn’t depend on one another.
-
For example, the user needs to import 10 structured data tables from one data source to another. The data tables don’t depend on each other, so we can run two batches of tables parallelly instead of running all the tables in a sequence. As a result, each batch will run five tables synchronously and help to reduce the runtime of the pipeline to half of the serial run.
Applying Data Quality Check
-
Data Quality needs to be maintained at any level so that the trustworthiness and value of data cannot be jeopardized. Teams can introduce schema-based tests, which test each data table with predefined checks, including the presence of null/blank data and column data type. The desired output can be produced if the data checks match, else, the data is rejected. Users can also perform indexing in the table to avoid duplicate records.
-
For example, in a data pipeline, data received from the client is in protobuf format. We will by-parse protobuf to extract the data, which will automatically apply a schema-based test on the data, where the data failing will be put into a different location to be handled explicitly, and processed data will be taken to a different stream.
-
Another example is of using AWS Deequ for data quality checks. We can use Deequ to compute data quality metrics like completeness, maximum, or correlation and be defined about changes in data distribution. AWS Deequ can help us in building scheduled data quality metrics and allow us to define special handling, like alarms based on quality.
Creating Generic Pipelines
-
Multiple groups often need to use the same core data to perform analysis. The same piece of code can be reused if a particular pipeline/code is repeated or a new pipeline needs to be built.
-
This will help to save energy and time since we can reuse pipeline assets to create new pipelines rather than developing a new one from scratch every time. You can parameterize the values used in the pipelines instead of hardcoding them. Different groups can use the same code by simply changing the parameters according to their specifications.
-
For example, the developer can build a boilerplate code so that it can be used by different teams with or without little alterations. Let’s consider we have a code that requires database connection details. The team can create a generic utility and pass the values in the form of parameters. Now, the different teams can use this utility, change the database connection details according to needs and run the job.
Monitoring and Alerting
-
Monitoring the job manually can be tedious since you need to look closely at the log file. The user can automate this process by clicking on the option to get email notifications related to the running status of a job and get notified in case of job failure. This improves the response time and restarts the work in a short duration of time with greater accuracy.
-
For example, while monitoring the Kinesis stream, the developer can view the write and read throughput. If the Write and Read Throughput exceeds the threshold, the developer can scale out the shards and if the pipeline resource usage is less than estimated, the developer can scale down the resources and improve cost optimization. The developer can get alerts through email or slack so that they can act spontaneously in case of need.
Implementing Documentation
-
Well-documented data flow can help new team members to understand the project details. Using flowcharts is preferred for better understanding. Documenting the code is also considered as the best practice since it will help new team members to get an easy understanding and walk-through of the code architecture and working.
For example, consider the ETL flow given below. Data is extracted from the source to the staging area, Data is transformed in the staging area,
Transformed data is loaded to a DataWarehouse
A well-designed Big Data Architecture makes it simple for a company to process data and forecast future trends to make informed decisions.Discover more about Top 9 Challenges of Big Data Architecture
The benefits of a significant data pipeline
A data pipeline is just a sequence of steps transporting raw data from one location to another. A transactional database could be a source in the context of business intelligence. The data is analyzed for business insights at the destination. Transformation logic is applied to data during this journey from the source to the destination to prepare it for analysis. There are numerous advantages to this method; here are our top six.
Replicated Patterns
Individual pipes are seen as examples of patterns in a more extensive architecture that may be reused and repurposed for new data flows when data processing is viewed as a network of pipelines.
Integration of new data sources takes less time
Having a familiar concept and tools for how data should flow through analytics systems makes it easier to plan to ingest new data sources and minimizes the time and expense of integrating them.
Data quality assurance
Thinking of your data flows as pipelines that need to be monitored and meaningful to end users increases data quality and minimizes the chances of pipeline breakdowns going undiscovered.
Confidence in the pipeline's security
Security is baked in from the start by having repeatable patterns and a consistent understanding of tools and architectures. Reasonable security procedures can be applied to new dataflows or data sources with ease.
Build-in stages
When you think of your dataflows as pipelines, you can scale them up gradually. You can get started early and achieve value immediately by starting with a modest controllable slice from a data source to a user.
Data Pipeline vs. ETL
Most people use the Data pipeline and ETL interchangeably. But they are different ones. ETL is a specific type of pipeline; it is a subset of the whole pipeline process. ETL used for Extract(pull), Transform(modify) and then Load(insert) data. Historically it is used as a batch workload, which means it is configured to run batches on a particular day or time only. But now, a new ETL tool is emerging for real-time streaming events also.
A data pipeline is a broader term used to transfer data from one system to another. Every time it doesn't need to transform the data.
Conclusion
Data collection, transformation, and movement are time-consuming and complex tasks, but a Data pipeline makes it easy for everyone who uses data to make strategic and operational decisions. Organizations can use a data pipeline that uses data stored at different locations and analyzes a broad view of the data. It makes the application more accurate, efficient, and acceptable using diverse data.
- Explore more about Data Quality - Everything you need to know
- Click to know about What is Data Observability?


























