.webp?width=1921&height=622&name=usecase-banner%20(1).webp)

What Is Data Quality Management? Definition, Architecture, Frameworks, and Best Practices
Low-quality data impacts business processes directly and measurably. Duplicate records cause operational errors — a logistics dataset containing both delivered and pending orders with overlapping entries will trigger re-delivery attempts on already-fulfilled shipments. Late data updates compound this problem, degrading analysis accuracy and slowing decision cycles across the enterprise.
These are not edge cases. They are systemic failures that occur when organizations lack a structured approach to data quality management (DQM). As data volumes grow and AI systems depend increasingly on reliable data inputs, the cost of poor data quality escalates from an operational inconvenience to a strategic liability.
Intelligent data management solutions — including AI-powered Data Quality Agents — can automate and streamline quality monitoring, validation, and remediation to prevent quality degradation at scale.
Key Takeaways
- Data quality management is the combination of people, processes, and technology that ensures data is accurate, consistent, complete, and fit for business use
- A DQM architecture has three core components: Workflow Manager, Rules Intelligence Manager, and Dashboard Manager
- Five quality pillars define measurement: consistency, accuracy, orderliness, auditability, and completeness
- Tools like Apache Griffin, AWS Deequ, and enterprise platforms (IBM Infosphere, Microsoft DQS, SAS) provide the automation layer
- For CDOs and Analytics Leaders: Without governed data quality, analytics teams lose the majority of their productivity to data correction rather than insight generation — DQM is the prerequisite for any reliable BI or AI system
- For Chief AI Officers: AI models trained or operated on low-quality data produce outputs that are unauditable and operationally unreliable — data quality infrastructure is a non-negotiable AI deployment prerequisite
Why is data quality important for business?
Poor data quality causes duplication, incorrect decisions, delayed operations, and reduced trust in business systems.
What Is Data Quality — and Why Does It Matter?
Data quality is the measure of data's fitness for its intended purpose. It reflects the reliability of a dataset and directly determines the effectiveness of every system built on top of it.
The data value hierarchy clarifies why this matters:
- Data is the raw foundation
- Information is data in context
- Knowledge is actionable information
- Wisdom is the application of knowledge to decisions
Low-quality data corrupts every layer above it. Poor data produces unreliable information, which produces flawed knowledge, which produces bad decisions. High-quality data is collected and analyzed through a defined set of guidelines that enforce accuracy and consistency — whether the source is structured (customer, supplier, product records) or unstructured (sensors, logs, event streams).
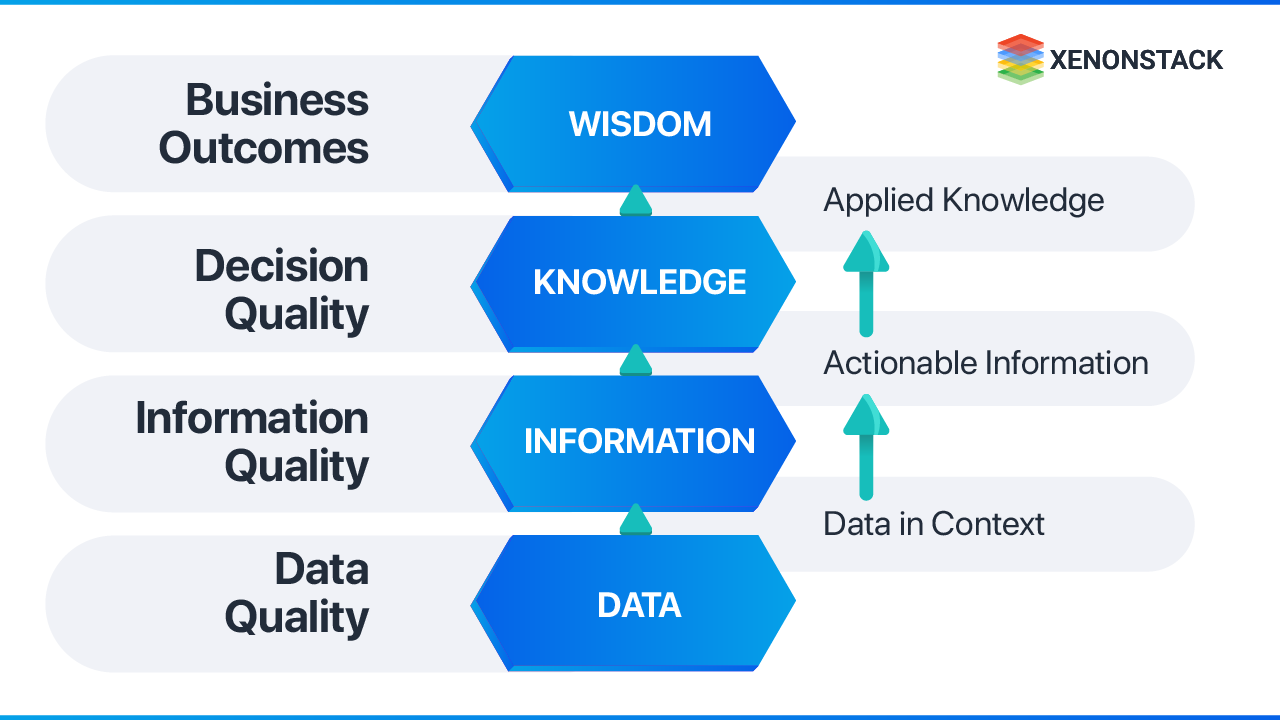
Good quality data is essential because it directly impacts business intuitions. This could be organized information sources like Customer, Supplier, Product, and so forth or unstructured information sources like sensors and logs.
Why Is Data Quality Management Critical for Business Operations?
The problem: Organizations that do not govern data quality cannot trust their Business Intelligence applications. Without trust in data, BI systems go unused — and the investment in analytics infrastructure produces no return.
Why low-quality data compounds over time:
- Incomplete data requires expensive remediation effort, consuming analyst capacity that should be applied to insight generation
- Inconsistent data prevents departments from working from a shared understanding, creating conflicting reports and misaligned decisions
- Ungoverned data creates compliance exposure under GDPR, CCPA, and sector-specific regulations
What governed data quality enables:
- A single source of truth across departments — enabling consistent, reliable decision-making
- Deeper and more accurate customer understanding — essential in competitive, data-driven markets
- Higher organizational efficiency — less time fixing data, more time acting on it
Data Management Agents enable organizations to establish a single source of truth, ensuring all departments operate from consistent, reliable data without manual reconciliation overhead.
How does data quality impact business intelligence?
BI systems rely on trusted data; without quality data, decision-making becomes unreliable.

How Does a Data Quality Framework Architecture Work?
A data quality architecture is the set of models, rules, and governance mechanisms that determine how data is collected, stored, organized, validated, and used. Its role is to create a reliable, secure data infrastructure with defined quality standards at every stage of the data lifecycle.
Three core components form the architecture:
1. What Is the Role of a Workflow Manager?
The Workflow Manager governs the data quality workflow — controlling the rules, actions, and permissions each user has within a quality process. Tools such as Bizagi (BPMN-standard workflow automation) and Atlassian Jira (development lifecycle management) support workflow configuration. For enterprise governance operating models, platforms like Collibra Data Governance Center provide scalable, adaptable workflow management with audit capabilities.
2. What Does a Rules Intelligence Manager Do?
The Rules Intelligence Manager translates high-level data quality specifications — defined by data stewards — into executable program logic. It is also responsible for data profiling generation.
For organizations without dedicated data quality tooling, ETL tools include transformation modules that function as quality rule engines — cleansing data before it reaches its destination system.
3. What Is a Dashboard Manager in Data Quality Management?
The Dashboard Manager creates the monitoring interface — displaying quality metrics and KPIs that track data quality performance over time. Effective dashboards incorporate the five core DQM attributes: completeness, consistency, accuracy, duplication rate, and integrity. BI and analytical tools provide the visualization layer for these metrics.
What are the core components of a Data Quality Framework?
Workflow manager, Rule’s Intelligence manager, and Dashboard manager.
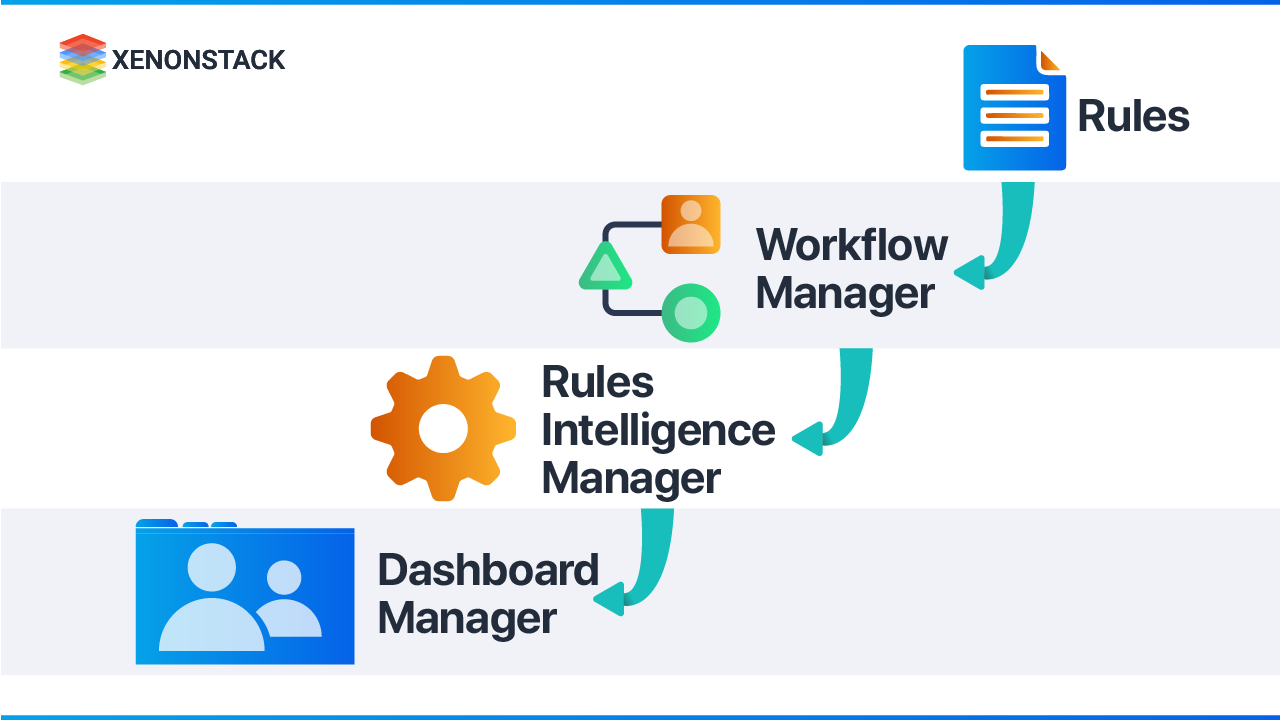
The architecture can be implemented with different technologies and tools depending on requirements and what is better for their needs.
What Strategies and Tools Improve Data Quality Management?
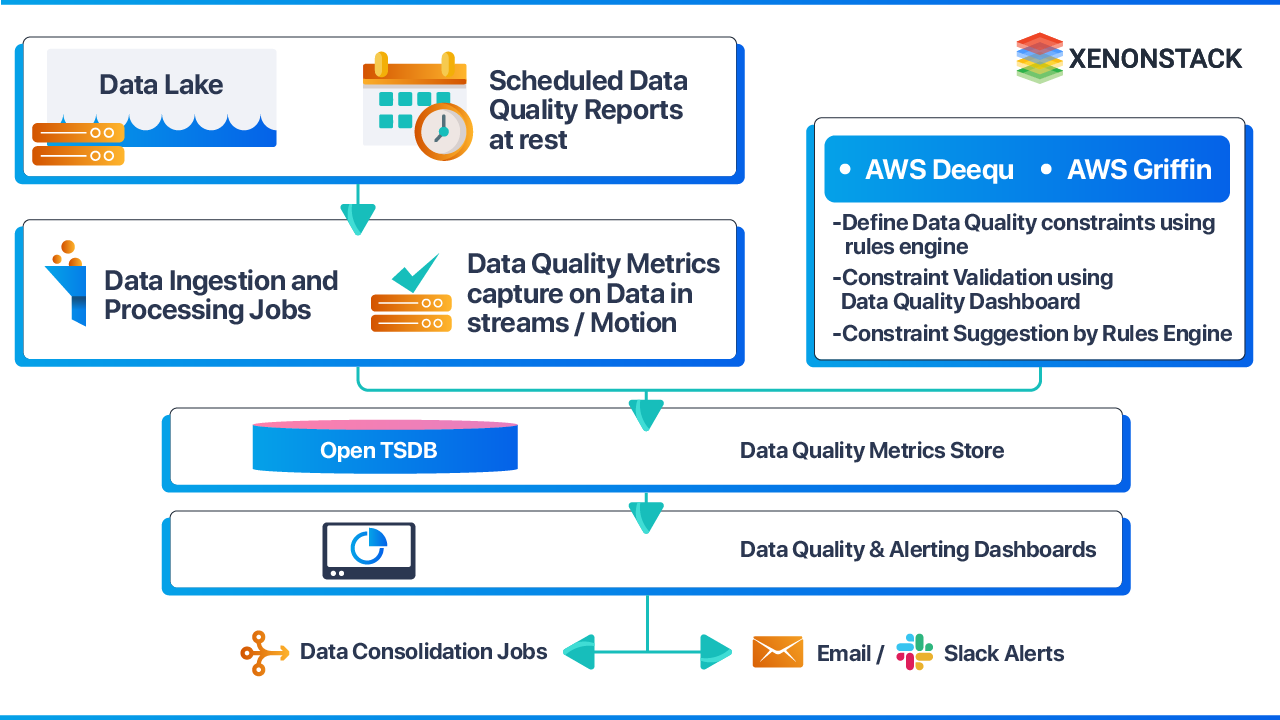
The challenge: At big data scale — high volume, high velocity, and heterogeneous data types — manual quality management is not feasible. Machine learning-based quality systems are required to detect anomalies that rule-based systems cannot identify.
Two categories of data require different management approaches:
-
Historical data quality: Apache Griffin provides a uniform process to measure quality across batch datasets. Data scientists define quality requirements (accuracy, completeness, etc.), ingest source data into the Griffin computing cluster, execute quality measurements, and store results in OpenTSDB for dashboard monitoring.
-
Real-time data quality: AWS Deequ enables automated quality constraint verification on streaming data. Organizations define constraints; Deequ computes the required metrics using Apache Spark (reading from sources like Amazon S3), verifies constraints, and generates quality reports — without requiring custom algorithm implementation.
How can organizations automate data quality monitoring?
By using tools like Apache Griffin and AWS Deequ for automated validation and reporting.
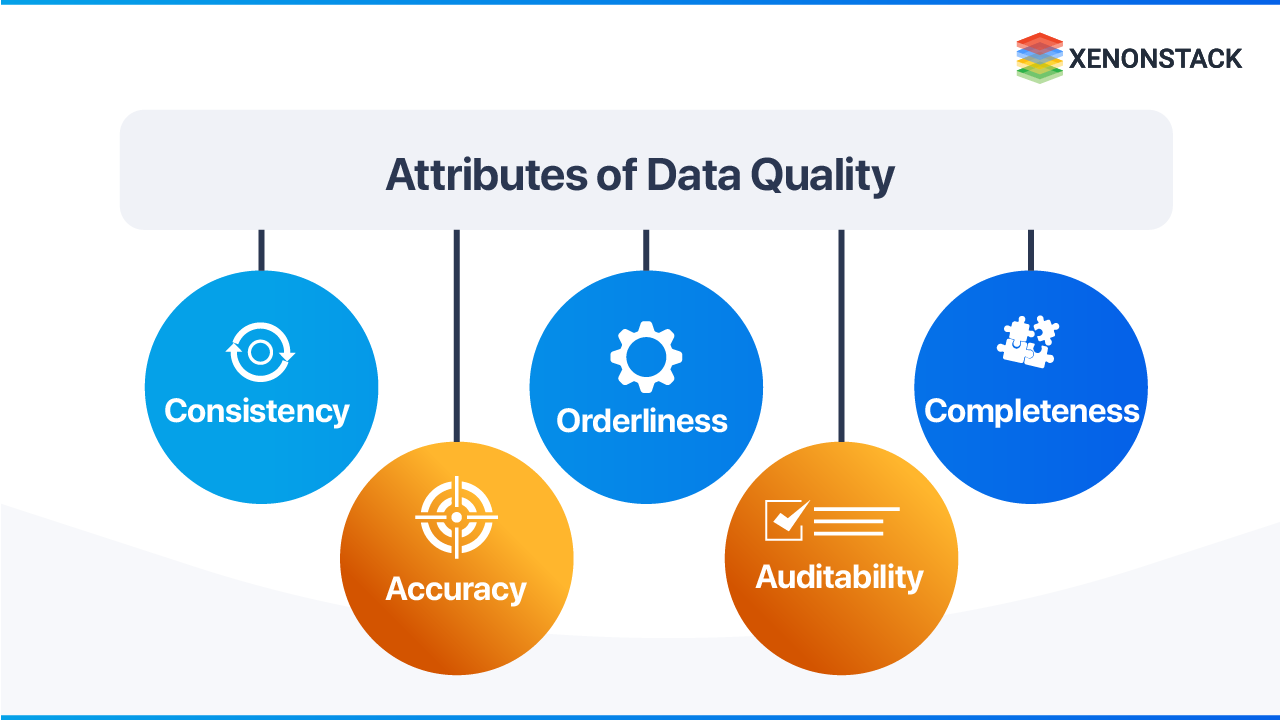
What Are the Five Core Pillars of Data Quality?
| Pillar | Definition |
|---|---|
| Consistency | No contradictions exist across the database — the same entity has the same value regardless of where it is accessed |
| Accuracy | Data correctly represents the real-world entity or event it describes |
| Orderliness | Data conforms to the required structure and format — date fields follow standard formats, codes follow defined schemas |
| Auditability | Data changes are traceable — where data is stored and how it has been modified is accessible and documented |
| Completeness | All interdependent data elements are present, enabling correct interpretation of the full dataset |
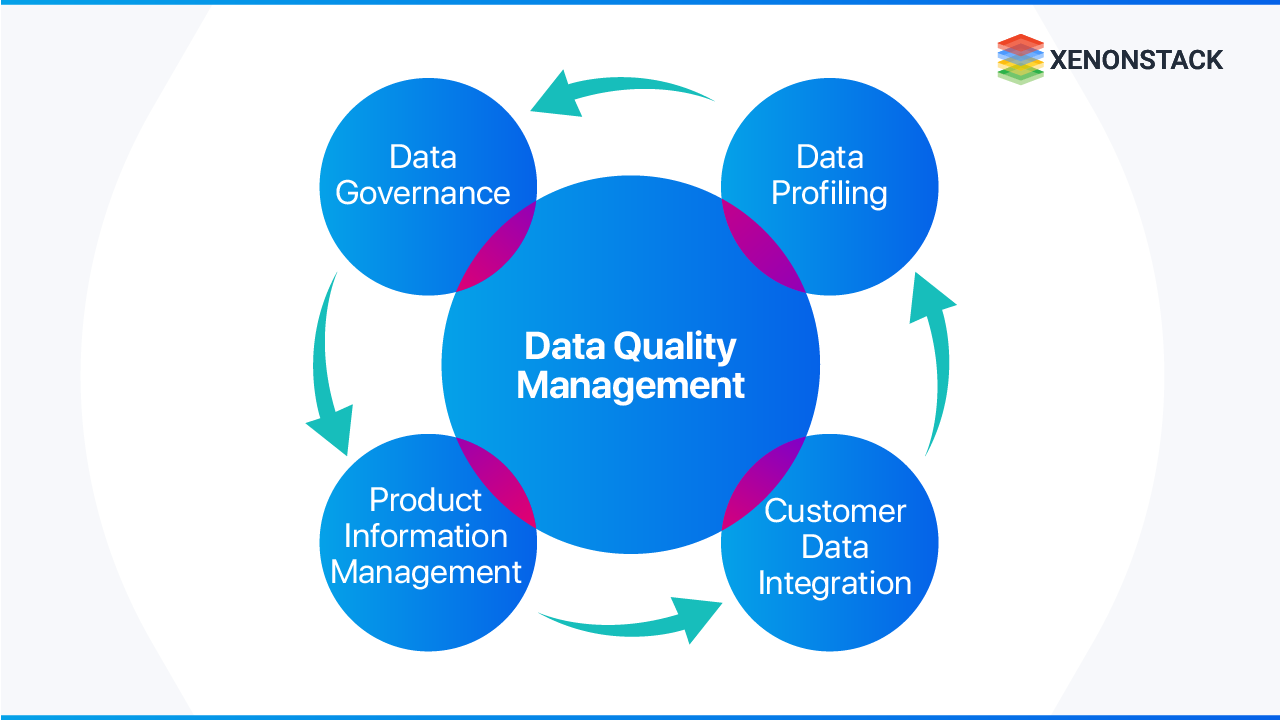
What Are the Key Data Quality Management Practices?
DQM combines the right people, technologies, and processes with the shared objective of improving data quality across the enterprise. Five core disciplines govern effective practice:
-
Data Governance Defines the business rules that data quality measurement must support. The governance framework establishes the organizational structures required to sustain the necessary level of data quality — including ownership, stewardship, and accountability.
-
Data Profiling A technique — supported by dedicated tooling — that provides deep understanding of data assets. Profiling is required for anyone responsible for quality prevention and data cleansing, as it surfaces structural characteristics, anomalies, and relationships within datasets.
-
Master Data Management (MDM) MDM and DQM are tightly coupled disciplines. Both operate within the same data governance framework, share data owner and steward roles, and address quality at the source. For most organizations, an MDM framework is the sustainable mechanism for preventing recurring quality issues — replacing repeated data cleansing cycles with structural prevention.
-
Customer Data Integration (CDI) Customer master data typically flows from self-service registration systems, CRM applications, ERP platforms, and additional sources. Consolidating these into a single source of truth requires technical integration and sustained quality governance — including matching logic, completeness validation, consistency enforcement, and accuracy verification.
-
Product Information Management (PIM) Manufacturers must align internal product data quality with distributor and retailer data requirements. PIM ensures data completeness and quality consistency across the product data supply chain — directly affecting how products are discovered and chosen by end customers.
What disciplines support Data Quality Management?
Data Governance, Data Profiling, Master Data Management, and Customer Data Integration.
What Are the Best Practices for Ensuring Data Quality?
-
Prioritize quality as a first-order requirement Data quality improvement must be treated as a high-priority organizational initiative — not a cleanup activity. Every employee must understand the business cost of low-quality data. A monitoring dashboard must provide continuous visibility into quality status.
-
Automate data entry wherever possible Manual data entry is a primary source of quality degradation. Automating data capture reduces human error and eliminates the inconsistencies introduced by manual input from team members and customers.
-
Govern both master data and metadata Master data requires quality governance — but metadata is equally critical. Timestamps and version metadata enable organizations to control data versioning and trace the lineage of changes over time. Without metadata governance, version control collapses.
How can organizations prevent poor data quality?
Prioritize governance, automate processes, and maintain metadata controls.
What Enterprise Tools Support Data Quality Management?
-
IBM InfoSphere Information Server Provides tools to understand data and its relationships, analyze quality, cleanse and standardize records, and maintain full data lineage. Converts raw, unreliable data into trusted, governed assets.
-
Microsoft Data Quality Services (DQS) Supports correction, standardization, and data de-duplication through SQL Server. Leverages cloud-based data services from trusted data providers to perform cleansing operations at scale.
-
SAS Data Quality Improves consistency and integrity across analytical datasets. Increased data quality directly increases the value and reliability of SAS analytical outputs.

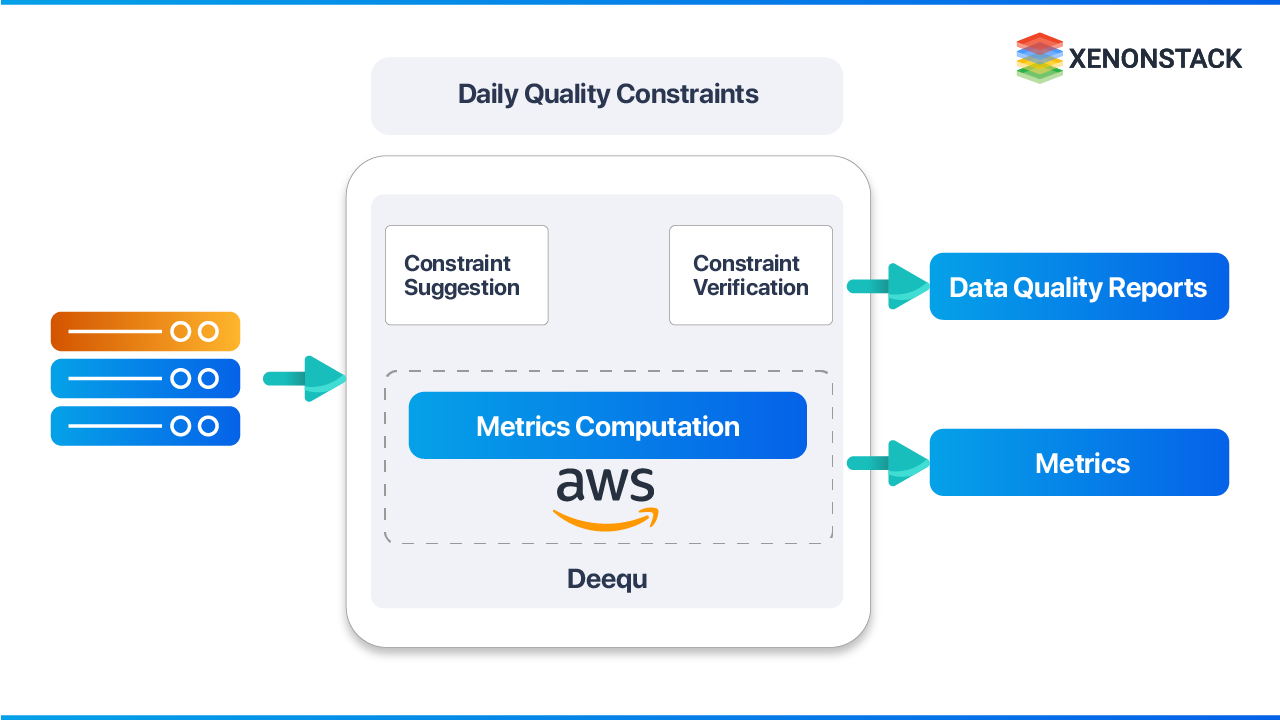
How Does Deequ Improve Data Quality Management at Scale?
Deequ is an open-source framework developed and used internally at Amazon to verify dataset quality at scale. It enables automated quality constraint verification without requiring custom metric implementation.
Three core Deequ components:
-
Metrics Computation Calculates data quality metrics — completeness, maximum values, correlation — using Apache Spark for optimized aggregation queries across sources including Amazon S3.
-
Constraint Verification Organizations define quality constraints; Deequ derives the required metrics, executes verification, and produces a data quality report with pass/fail results for each constraint.
-
Constraint Suggestion Deequ profiles datasets and automatically infers practical quality constraints — enabling organizations to bootstrap quality governance without manual constraint definition from scratch.
At Amazon, Deequ runs quality checks consistently with each new dataset version. Dataset producers add or update constraints. The framework validates requirements and publishes quality status to consumers whenever changes are detected.
What is Deequ used for?
Deequ validates data quality constraints and computes dataset quality metrics.
How Should CDOs and Analytics Leaders Measure Data Quality Management Performance?
Tracking data quality tool deployment or pipeline coverage measures infrastructure health — not business impact. CDOs and analytics leaders need a measurement framework that connects quality governance directly to operational and strategic outcomes.
Four-Dimension KPI Framework for Data Quality Performance:
| Dimension | Key Metrics | What It Measures |
|---|---|---|
| Data Accuracy & Completeness | Accuracy rate by domain; completeness score by dataset; duplication rate | Is the data infrastructure producing reliable, usable outputs? |
| Governance Enforcement | Policy compliance rate; data lineage coverage; stewardship resolution time | Is governance consistently applied across all data assets? |
| Operational Impact | Analyst hours spent on data correction; time-to-insight; remediation cycle time | Is DQM reducing the operational cost of poor data? |
| Business Outcomes | BI system adoption rate; decision accuracy improvement; compliance incident reduction | Is data quality translating into measurable business value? |
Portfolio-Level Metrics for CDOs, VPs of Data & Analytics, and Chief AI Officers:
- Data trust score — Percentage of BI and analytics outputs certified as quality-governed vs. unvalidated
- Remediation velocity — Average time from quality issue detection to resolution; should decrease as automation matures
- Quality coverage rate — Percentage of enterprise data assets with active quality monitoring, defined constraints, and documented lineage
- AI data readiness index — Percentage of datasets used in AI/ML workflows that meet defined quality thresholds for completeness, consistency, and accuracy
Data quality is not a data engineering concern — it is an AI governance requirement. Every AI model trained or operated on low-quality data produces outputs that are unreliable, unauditable, and indefensible to regulators and business stakeholders. Establish data quality standards and automated monitoring for all AI training and inference datasets before scaling model deployment. Retrofitting quality governance into production AI systems is significantly more costly than building it in from the start.
Conclusion: Why Data Quality Management Is a Strategic Imperative
Data Quality Management ensures that business decisions are based on reliable, consistent, and actionable information. Without structured governance, profiling, monitoring, and automation, enterprises absorb compounding costs — in analyst time spent on remediation, in compliance exposure, and in degraded trust in analytics systems.
For CDOs, CAOs, VPs of Data & Analytics, and Chief AI Officers, the implication is direct: data quality is not a cleanup project — it is the operational infrastructure that makes every BI investment, analytics initiative, and AI deployment defensible. Organizations that establish data quality governance now build the foundation that makes future data and AI investments scalable, auditable, and trusted.
High-quality data builds trust. Trust enables intelligence. Intelligence drives business outcomes.