
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is Chaos engineering?
It's the science of intentionally introducing failure into systems to assess resiliency. Like any scientific method, Chaos Engineering Services focuses on experiments/hypotheses and then compares the results to control (a steady-state). Taking down random services in a distributed system is the quintessential Chaos Engineering example to see how items respond and what the detriment is to the user journey.
A valid Chaos Engineering experiment is injecting a fault or fractious conditions into any part of the stack that an application requires to run (compute, storage, networking, and application infrastructure). Network saturation and storage suddenly becoming volatile at capacity are well-known failures in the technology industry, but Chaos Engineering enables much more controlled testing of these and other failures. Users and practitioners of Chaos Engineering can be almost anyone supporting the application/infrastructure stack due to the broad range of infrastructure that can be influenced
What are the Principles of Chaos Engineering?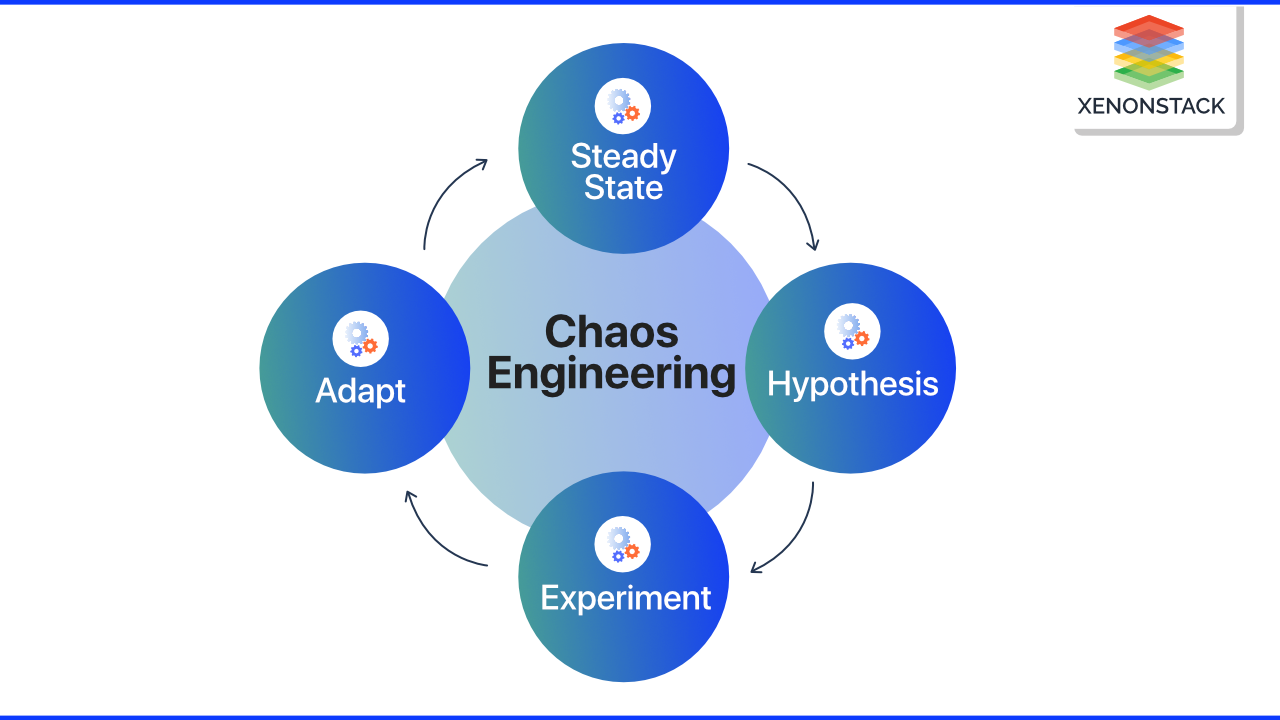
The Principles of Chaos Engineering for cloud native is a great declaration that helps explain the primary standards and objectives of Chaos Engineering. The Principles of Chaos Engineering define four practices analogous to the scientific method.
- Steady-state
- Hypothesis
- Experiment
- Adapt
How Chaos Engineering works?
All testing in chaos engineering is done through what is known as chaos experiments. Each experiment begins with the introduction of a specific fault into a system, such as latency, CPU failure, or a network black hole. Admins then observe and compare what they expect to happen to what occurs.
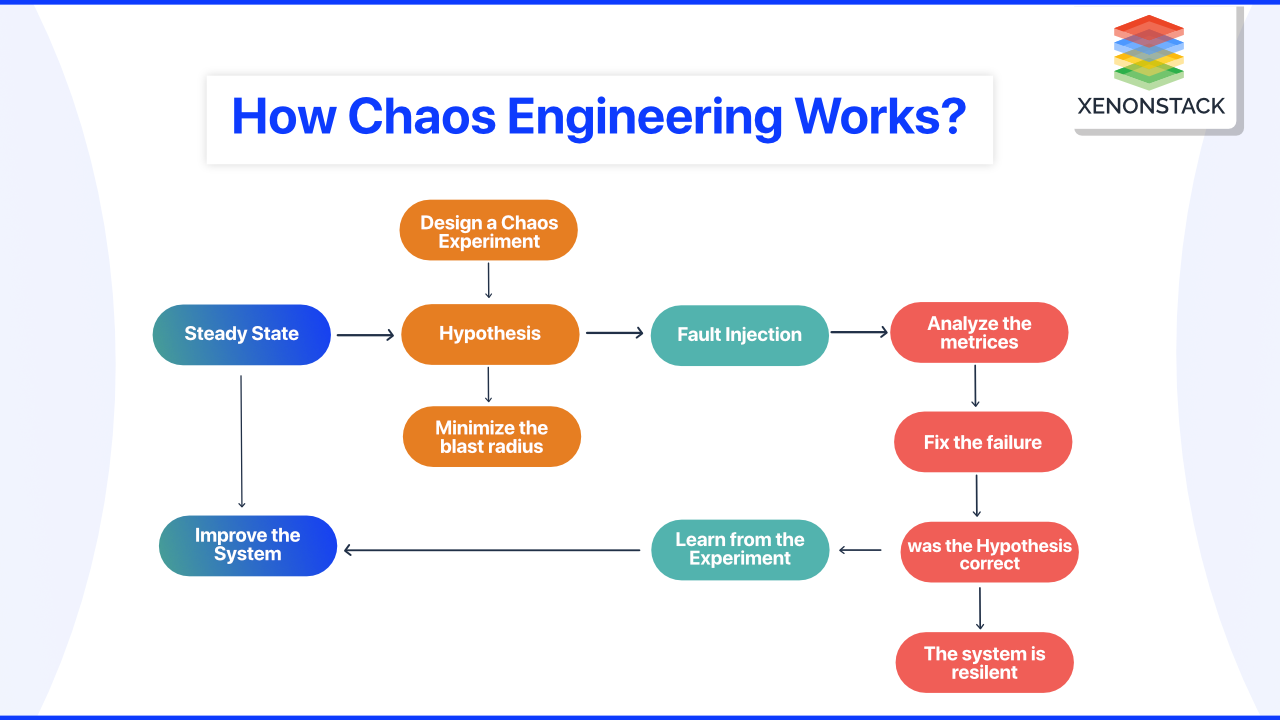 Creating a Hypothesis
Creating a Hypothesis
Engineers examine the system and decide what type of failure to cause. The primary step in chaos engineering is predicting how the system will behave when it encounters a specific bug.
Before beginning a test, engineers must also determine critical metric thresholds. Metrics are typically divided into two categories:
- Key metrics: These are the experiment's primary metrics. You can, for example, assess the impact on latency, requests per second, or system resources.
- Customer metrics: These are precautionary metrics that indicate whether or not the test was carried out sufficiently. Customer metrics include things like orders per minute and stream starts per second. If a test begins to affect customer metrics, administrators should stop experimenting.
Fault Injection
Engineers modify the system to include a specific failure. There is always a backup plan because there is no way to predict how the application will react.
The majority of chaos design methods have a reversal option. If something turns out badly, you can safely abort the test and return to the application's steady state.
Measuring the Impact
The engineers start monitoring the system until the bug/fault causes any significant problem. If it causes or starts some outage, then the team looks for the best way to solve the problem.
Verify your hypothesis
A chaos experiment has either of the outcomes: maybe the system is resilient, or there is a problem that needs to be fixed.
What are the best tools for Chaos Engineering?
List of some of the best Chaos Engineering tools in the market
- Chaos Monkey
- Gremlin
- Chaos Toolkit
- Litmus
- ChaosBlade
- Chaos Mes
- Chaos Toolkit
- PowerfulSeal
- ToxiProxy
- Istio
- KubeDoom
- AWS FIS
Why Chaos Engineering For Cloud Native?
Customer retention, customer satisfaction, and customer experience are top priorities for management in today's e-commerce world, whether it's the operations, business, product engineering, team. The dependability of your service is critical to the success of your business. While this is self-evident, service dependability has become increasingly important. The reason is straightforward: more people use digital services, and businesses have become more digital-centric. One of the reasons why server administrators, database administrators, and network administrators are becoming site reliability engineers is the digital transformation (SREs). This transformation is also fueled by the shift to microservices and application containerization.
What are the Challenges in Cloud Native?
- IT - businesses are becoming cloud-native. There are several variable parts in a cloud-native environment. When developing a cloud-native service, you will have access to middleware software components and levels of infrastructure.
- The difference between a cloud-native service and a traditional one is that cloud-native involves even more components, each of which is independently tested and bound together. But after all these processes and testing, sometimes the system fails.
- How can we practice chaos engineering in cloud-native? So cloud-native has a few principles included such as gaining declarative configuration, Flexible, scalable, using APIs, etc.
What are the Principles of Cloud Native Chaos Engineering?
-
Open Source
Open source has been central to cloud-native communities and technologies. Because chaos engineering frameworks are open source, they benefit from strong communities that help them become more comprehensive, rugged, and feature-rich -
Community Collaboration
Chaos experiments must be easy to use, highly adaptable, and tunable. Chaos experiments must be challenging, with little or no chance of producing false negatives or positives. Chaos experiments are similar to Lego blocks in that they can be used to construct meaningful chaos workflows. -
Managing Chaos Engineering
Well-known software engineering practices must be used in chaos engineering. Managing chaos scenarios can quickly become complex as more team members become involved, changes occur more frequently, and requirements change. Upgrading chaos experiments is becoming more common.
The chaos engineering framework should allow for the easy and straightforward management of chaos experiments in the Kubernetes fashion. Chaos experiments should be viewed as Kubernetes customer resources by developers and operators.
-
GitOps
Begin with low-hanging fruit or obvious and straightforward issues. As you begin to fix them, the chaos scenarios become more comprehensive and significant, as does the number of chaos scenarios. Chaos scenarios must be automated or triggered whenever a change is made to the service's applications. When a configuration change occurs to either the application or the chaos experiments, tools based on GitOps can trigger chaos.
An overview on Litmus
Litmus is built with cloud-native chaos engineering principles as its fundamental architectural aims. Litmus is a cloud-native chaos engineering framework. It allows you to build, orchestrate, and scale chaos experiments seamlessly. Litmus includes many ready-to-use chaos experiments hosted on an open hub, ChaosHub. 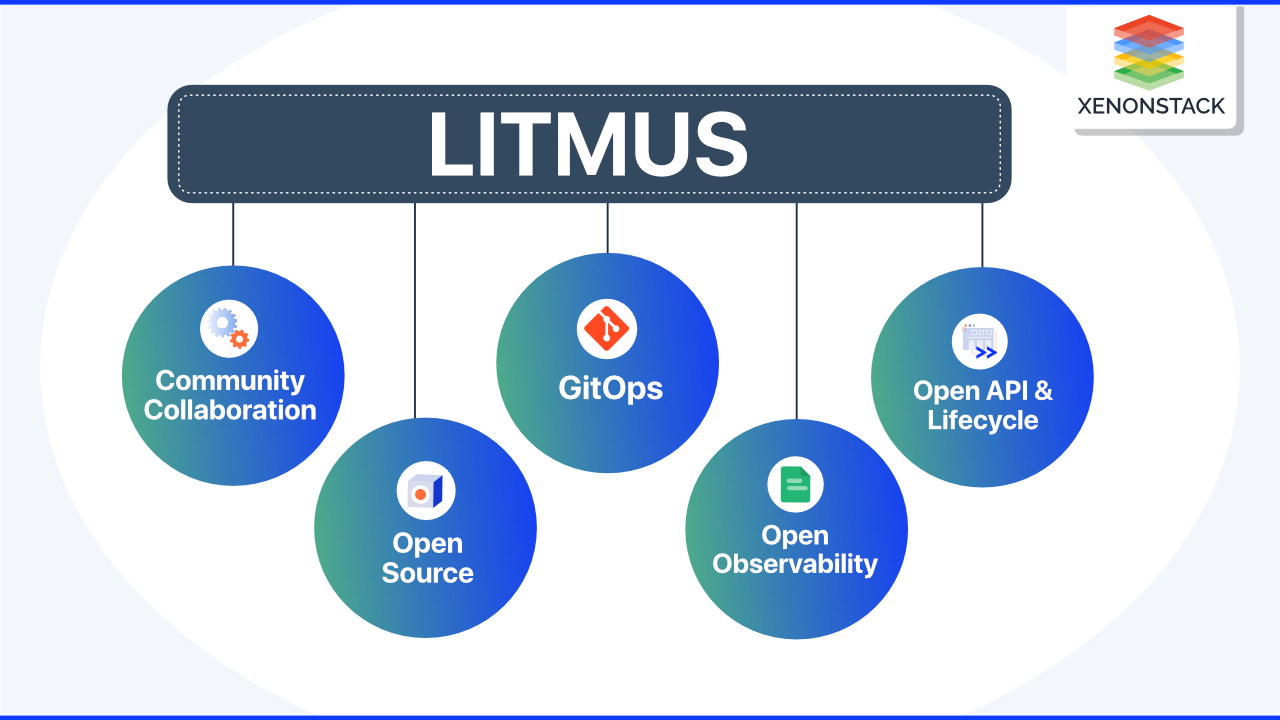
These experiments serve as the foundation for Litmus workflows, which can be compared to your actual chaos scenarios. Developers, QA & SREs work together to create the necessary chaos workflows and orchestrate them with the help of GitOps for scaling. The main components of Litmus are
- Chaos CRD or API
- Chaos Operator
- Chaos Libraries
- Chaos Hub
Chaos API
There are three APIs that Litmus provides
- ChaosEngine - A chaos engine CR is created particularly for an application and given a tag with appLabel; CR binds one or multiple ChaosExperiments to an application.
- ChaosExperiment - ChaosExperiment CR is designed to store and manage the details of actual chaos on a computer. It specifies the type of experiment and the critical parameters of the experiment.
- ChaosResult - After running an experiment, the operator generates a ChaosResult CR. One ChaosResult CR is kept per ChaosEngine. The ChaosResult CR is useful for making sense of a given ChaosExperiment. This CR is used to generate chaos analytics, which can be extremely useful – for example, when specific components are upgraded between chaos experiments and the results need to be easily compared.
Chaos Operator
The Operator-SDK is used to implement the Litmus Operator. This operator is in charge of the chaos CRs' lifecycle. Because it adheres to the lifecycle management API requirements, this operator can be used to manage the lifecycle of Litmus itself. The chaos operator can also be found at operatorhub.io.
Chaos Libraries
Chaos libraries or chaos executors do the actual chaos injection. The Litmus project, for example, has already created a chaos library called "LitmusLib." LitmusLib understands how to kill a pod, introduce a CPU hog, hog memory, or kill a node, among other faults and degradations. Other open-source chaos projects, such as Pumba and PowerfulSeal, exist alongside LitmusLib.
More information about various chaos engineering projects can be found in the CNCF landscape. The Litmus plugin framework, as shown below, enables other chaos projects to use Litmus for chaos orchestration. For example, using Pumba or PowerfulSeal, one can create a chaos chart for the pod-kill experiment and execute it using the Litmus framework.
Chaos Hub
The chaos charts can be found at hub.litmuschaos.io. Chaosium collects all reusable chaos experiments. Application developers and SREs share their chaos experiences with others so that they can be reused. The hub's goal is to share the failure tests they use to validate their applications in CI pipelines with their users, who are typically SREs.
Litmus supports a list of Chaos Experiment.
|
Pod Chaos |
Node Chaos |
Network Chaos |
Stress Chaos |
Cloud Infrastructure chaos |
Application Chaos |
|
Pod failure Container Kill Pod Autoscale |
Node Drain Forced Eviction Node Restart\Power off |
Network latency Network Corruption Duplication |
Pod, Node termination Pod, nod memory hog Pod node disk stress |
AWS EKS EC2 Termination, Disk Detach GCP Persistent Disk Detach |
Kafka leader broker failure Cassandra ring disruption |
Installation of LitmusChaos
- Prerequisite
- Install Docker
- Install Minikube
- Install Kubectl
- Start minikube
- Install Litmus - using kubectl
$kubectl apply -f https://litmuschaos.github.io/litmus/2.4.0/litmus-2.4.0.yaml
#verify your installation
$kubectl get pods -n litmus
#expected output
NAME READY STATUS RESTARTS AGE
litmusportal-frontend-97c8bf86b-mx89w 1/1 Running 2 6m24s
litmusportal-server-5cfbfc88cc-m6c5j 2/2 Running 2 6m19s
mongo-0 1/1 Running 0 6m16
#Check the services running in the namespace where you installed Litmus:
$kubectl get svc -n litmus
#expected output
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
chaos-litmus-portal-mongo ClusterIP 10.104.107.117 <none> 27017/TCP 2m
litmusportal-frontend-service NodePort 10.101.81.70 <none> 9091:30385/TCP 2m
litmusportal-server-service NodePort 10.108.151.79 <none> 9002:32456/TCP,9003:31160/TCP 2m
----------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------
#port forwarding
$kubectl port-forward service/litmusportal-frontend-service 3000:9091 -n litmus
LitmusChaos Login Page
Default Username: admin
Default Password: Litmus
LitmusChaos Dashboard
Conclusion
The idea behind this method is to solve the issues that are already present. This is a solution not only for big companies like Netflix but also for each organization dealing with the problems. It's an emerging practice, and companies can adapt without much modification in their production environment. In the end, it's a practice to improve your system for the better.
Read Next?
- Learn aboutNetwork Reliability Engineering (NRE)
- Know theBest Practises And Solutions For SRE Team



























