
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
The Internet of Things (IoT) has changed the way we interact with technology, enabling a network of interconnected devices that communicate and share data seamlessly. At the heart of this transformation lies the IoT Analytics Platform, a critical software solution designed to facilitate the development, deployment, and management of these devices and applications while enabling powerful IoT data analytics for actionable insights.
How IoT Devices Communicate and Share Data
IoT is a system of interrelated computing devices, mechanical and digital machines, or people provided with unique identifiers (UIDs) and the ability to transfer data over a network without requiring human-to-human or human-to-computer interaction. These physical objects include various devices such as:
-
Smartphones
-
Tablets
-
Wearable devices
-
Sensors and actuators
-
Smart appliances
As IoT adoption grows, businesses need efficient IoT analytics solutions to process and interpret vast amounts of data generated by these devices. Real-time IoT analytics plays a crucial role in transforming raw data into meaningful insights, driving smarter business decisions and improving operational efficiency. The term 'Internet of Things' encompasses an ecosystem where physical objects are interconnected to the Internet, yielding actionable insights through its platform.
An IoT Analytics Platform acts as a middleware layer, connecting various IoT devices to the cloud, allowing for efficient IoT data analytics, real-time monitoring, and intelligent decision-making. It serves as a centralized hub for managing the entire IoT ecosystem, streamlining processes, and maximizing the potential of connected devices with advanced IoT analytics solutions.
What is IoT Architecture?
The Internet of Things (IoT) architecture is the structured framework that enables seamless connectivity between physical devices, networks, and cloud-based analytics platforms. It defines how sensors, edge devices, gateways, and cloud services interact to collect, process, and analyze data in real time. A well-designed IoT Analytics Platform ensures scalability, security, and efficiency, allowing businesses to implement IoT analytics solutions that drive automation and intelligence.
With the power of real-time IoT analytics, industries can extract actionable insights to optimize data flow, reduce latency, and improve operational efficiency. Advanced IoT data analytics integrated with AI and machine learning enhances predictive maintenance, automation, and decision-making. Understanding this architecture is crucial for industries like smart cities, healthcare, and manufacturing to unlock the full potential of IoT.
Architecture of IoT Analytics Systems
IoT architecture typically comprises four essential layers, each playing a crucial role in the collection, transmission, processing, and utilization of data:
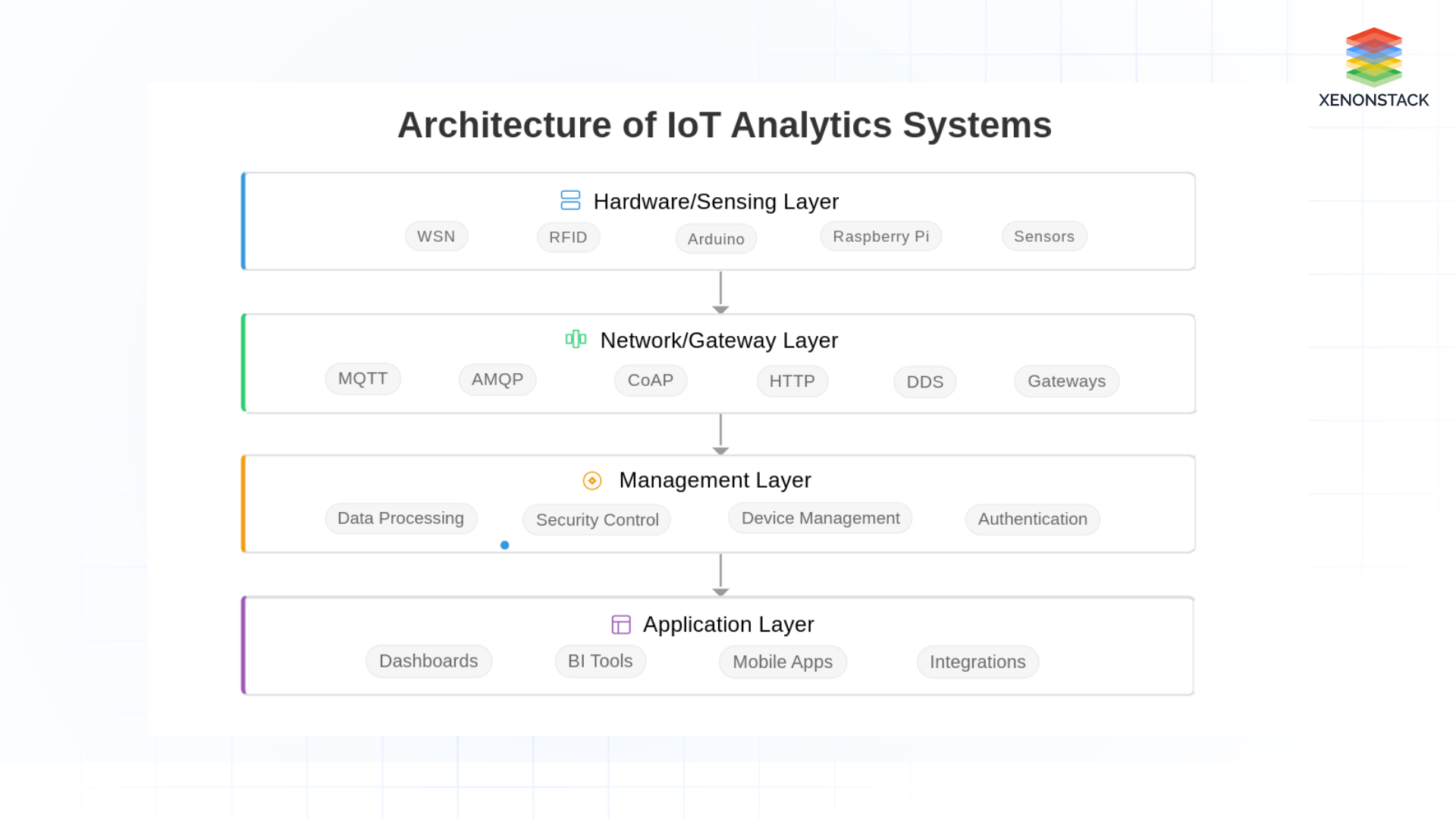 Fig 1: IoT Analytics Systems Architecture
Fig 1: IoT Analytics Systems ArchitectureHardware/Sensing Layer
This layer serves as the foundational level of the IoT architecture, comprising hardware devices connected to the network layer. Wireless Sensor Networks (WSN) and radio-frequency identification (RFID) serve as the two primary building blocks of IoT analytics solutions.
Arduino microcontrollers are directly linked with the sensors and further connected to the Raspberry Pi. The Raspberry Pi, in turn, connects to the Internet via Ethernet or WiFi, facilitating the real-time IoT analytics process by transmitting sensor data to the server. This seamless data collection enables advanced IoT data analytics, ensuring precise monitoring and control across industries.
Network/Gateway Layer
This layer acts as the bridge between the Hardware/Sensing Layer and the Management Layer, ensuring efficient data flow for IoT analytics platforms. Here, digitized data is received and routed over wired LANs, WiFi, or the Internet for further processing.
Various protocols enable seamless communication between IoT analytics solutions, IoT gateways, and servers, including:
-
MQTT (Message Queuing Telemetry Transport)
-
AMQP (Advanced Message Queuing Protocol)
-
CoAP (Constrained Application Protocol)
-
HTTP (Hypertext Transfer Protocol)
-
DDS (Data Distribution Service)
Management Layer
This layer is responsible for data modeling and security control, serving as the hub for all data handling and processing operations within an IoT Analytics Platform. It extracts relevant information from sensor-generated data, enabling businesses to leverage real-time IoT analytics for decision-making.
Key functions include:
-
Data processing and transformation
-
Device management
-
Security implementation
-
Authentication and authorization
Application Layer
This layer represents the final stage of the IoT analytics architecture, utilizing the data processed by the management layer. It includes:
-
User interfaces and dashboards
-
Business intelligence tools
-
Mobile applications
-
Third-party integrations
Operational Mechanism of IoT Platforms
IoT devices consist of a diverse collection of sensors, particularly tailored to cater to specific functionalities and environmental parameters. These sensors operate in tandem, engaging with the physical world to capture data points. Whether monitoring air quality, tracking inventory levels, or detecting anomalies in industrial machinery, these sensors serve as the eyes and ears of the IoT ecosystem.
Through the IoT platform's sophisticated architecture, this deluge of data is seamlessly channeled to the cloud infrastructure, where it undergoes processing and analysis. Subsequently, stakeholders are empowered to extract actionable insights, glean valuable analytics, and make informed decisions that drive operational efficiency and innovation.
Key Components of an IoT Platform
Connectivity
This component enables IoT devices to communicate with the internet using protocols, gateways, and APIs. It ensures reliable data exchange between devices.
Device Management
IoT devices require onboarding, provisioning, and maintenance for efficient operation. This includes firmware updates, remote configuration, and real-time monitoring.
Data Management
Managing IoT-generated data involves storage, processing, and analytics. This helps businesses extract insights and optimize performance.
Application Enablement
Developers use APIs and SDKs to build applications that interact with IoT devices. This layer simplifies app development for various use cases.
Cloud Computing Services
Cloud services provide scalable storage, computing, and analytics. They help process large volumes of IoT data efficiently.
Interoperability and Integration
IoT platforms ensure seamless communication between diverse devices. This enables accurate data transmission and system scalability.
Security
Protecting IoT systems involves encryption, authentication, and access controls. These measures safeguard data from unauthorized access.
Analytics
IoT platforms use AI and machine learning for real-time insights. Advanced analytics improve decision-making and operational efficiency.
Application Development
This component provides tools and resources for building IoT applications. Developers can create and test applications using APIs and SDKs.
How Does an IoT Platform Work?
An IoT platform works by providing the necessary infrastructure and tools for organizations to build, manage, and analyze IoT applications. It handles various functions such as:
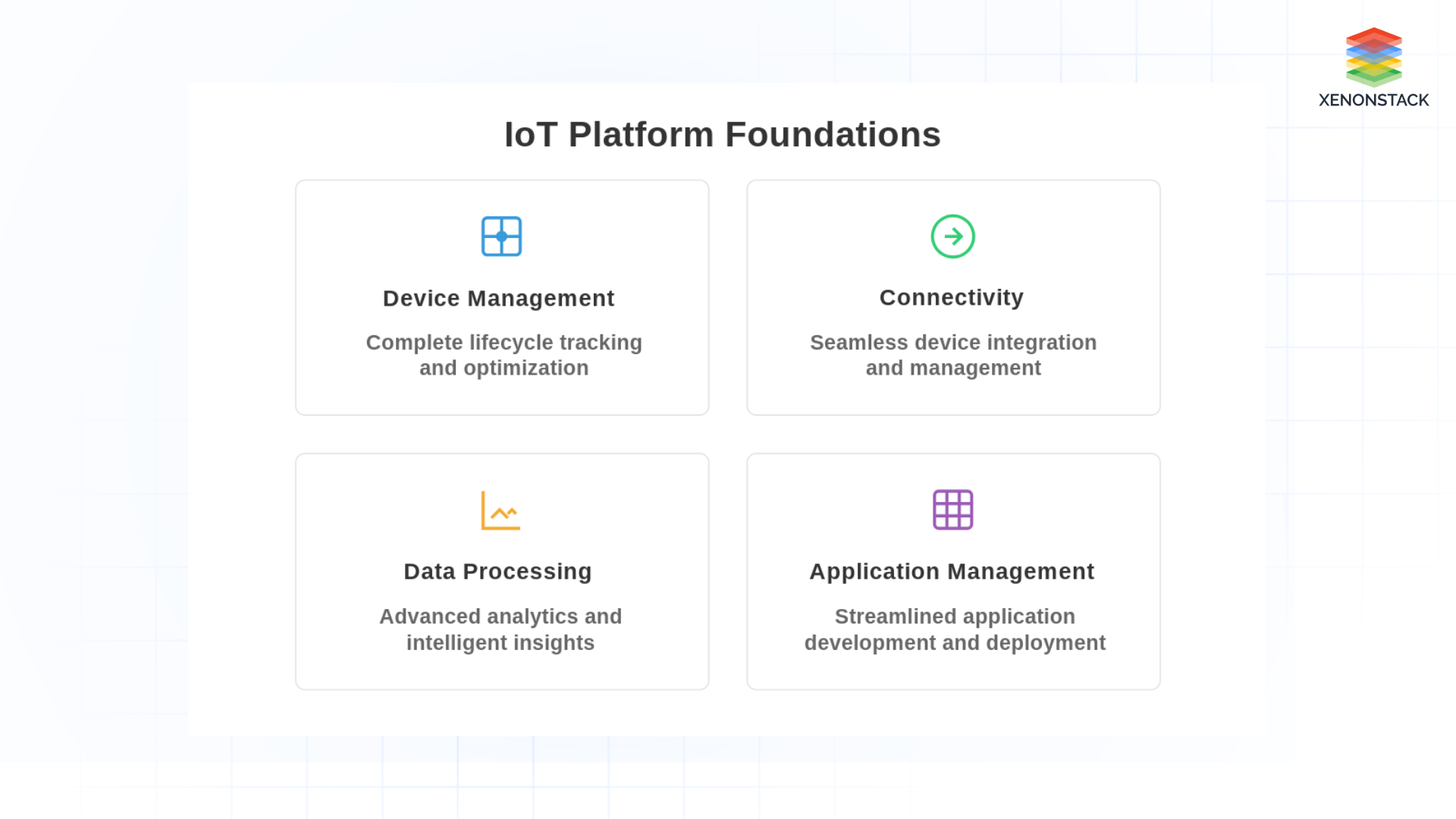 Fig 2: Foundations of IoT Platform
Fig 2: Foundations of IoT Platform
-
Device Management: IoT platforms facilitate the entire lifecycle management of IoT devices, encompassing planning, onboarding, monitoring, maintenance, and retirement processes.
-
Connectivity Management: These platforms serve as centralized solutions, connecting, managing, and analyzing data from IoT devices. They streamline IoT project deployment, reduce technical complexities, and enable smarter actions and production.
-
Data Processing and Analytics: IoT platforms contribute to sustainability efforts by offering insights into equipment performance, asset location, and resource consumption. This insight drives smarter consumption and production practices.
-
Application Management: The platforms empower the collection of physical data and subsequent application of analytics, optimizing operations, production, and revenue generation.
Most Common Protocols Used in IoT Analytics
The below mentioned protocol are most widely used in IoT Analytics:
MQTT
-
MQTT is an efficient publish/subscribe protocol ideal for low bandwidth or unreliable network conditions, frequently utilized for remote sensor data collection.
-
The MQTT broker serves as a centralized communication point where clients publish and subscribe to topics to exchange messages.
CoAP
-
The Constrained Application Protocol (CoAP) is designed for simple, constrained devices and facilitates web based, RESTful interactions using familiar methods like GET, PUT, POST, and DELETE.
-
It is particularly well suited for constrained networks and power limited IoT devices.
AMQP
-
AMQP (Advanced Messaging Queuing Protocol) is an open standard for passing messages in between applications and organizations. It connects system, provides business processes with the information they need.
HTTP
-
This is the standard protocol for web services and still is used in its solutions. The most popular architectural style, called RESTful, is widely used on mobile and web applications and must be considered in IoT Solutions.
DDS
-
DDS stands for Data Distribution Service, which is a standard for real time IoT analytics and scalable and high-performance machine-to-machine communication. DDS can be deployed in both low-footprint devices and on the cloud as well.
-
With a Humancentric, sustainable and Resilient Industry 5.0 strategy for empowering connected IoT Solutions AI-powered Robots. Explore our IoT Application Development Services.
Benefits of IoT Platforms and Analytics
IoT platforms and analytics offer a plethora of advantages for businesses across various sectors:
Real-Time Data Handling in IoT
Efficient real-time data ingestion and processing are crucial for IoT analytics, enabling organizations to extract actionable insights instantly. IoT analytics platforms such as Tinybird, Xenonstack’s IoT Analytics Platform, AWS IoT Analytics, and IBM’s real-time solutions facilitate seamless data capture, transformation, and integration with cloud services.
Key aspects of real-time data handling include:
-
Data Ingestion: Collecting and integrating high-velocity data from IoT devices for immediate processing.
-
Stream Processing: Applying real-time transformations, anomaly detection, and data enrichment for enhanced decision-making.
-
Storage & Scalability: Managing large-scale IoT data efficiently while ensuring low-latency access for analytics.
Technologies like Apache Flink and Apache Storm provide powerful stream processing capabilities, enabling complex event processing, time windowing, and stateful computations. By leveraging these solutions, businesses can enhance operational efficiency, improve response times, and drive intelligent automation.
Comparative Overview of IoT Architecture Across Platforms
Different IoT platforms follow unique architectures to manage data ingestion, processing, storage, and visualization. The table below provides a comparative overview of Xenonify IoT, Google IoT, Azure IoT, and AWS IoT, highlighting their core functionalities and distinguishing features.
|
Aspect |
Xenonify IoT |
Google IoT |
Azure IoT |
AWS IoT |
|
Data Ingestion |
Apache NiFi, MiNiFi, StreamSets, MQTT |
Cloud IoT Core (MQTT, HTTP) |
IoT Hub (MQTT, AMQP, HTTP) |
IoT Core (MQTT, WebSockets, HTTPS) |
|
Message Routing |
NiFi, StreamSets to multiple destinations |
Cloud Pub/Sub for real-time messaging |
IoT Hub for bidirectional messaging |
IoT Core manages secure message routing |
|
Data Processing |
Apache Spark real-time analytics |
Cloud Dataflow batch & stream processing |
Stream Analytics real-time insights |
IoT Analytics for time-series processing |
|
Storage |
HBase, HDFS, ElasticSearch, Druid |
BigQuery petabyte-scale storage |
Cosmos DB multi-model database |
IoT Analytics, Amazon S3 |
|
Transformation |
NiFi, StreamSets data enrichment |
ML Engine, TensorFlow insights |
Data Factory for transformation |
IoT Analytics enriches data |
|
Visualization |
Kibana, Grafana, React.js, D3.js |
DataLab, Data Studio dashboards |
Power BI analytics |
QuickSight IoT data insights |
|
Advanced Analytics |
Apache Spark ML, AI models |
Google ML tools |
Azure ML, Databricks models |
AWS ML, AI analytics |
|
Scalability |
Auto-scales based on data velocity |
Google Cloud auto-scaling |
Azure dynamic scaling |
AWS IoT scalable for billions |
Key Use Cases: Turning IoT Data into Actionable Insights
Healthcare
IoT analytics solutions enable remote patient monitoring by analyzing data from wearables and sensors, assisting healthcare professionals in tracking patient adherence to treatments and adjusting care plans in real-time. An example is the IoT healthcare app created by QardioCore. These insights help detect early health deterioration, ensure medication adherence, adjust treatment plans, and optimize resource allocation in healthcare facilities.
Industrial Manufacturing
In manufacturing, IoT analytics facilitate predictive maintenance of machinery, using sensor data to predict and prevent equipment failures before they occur. This enables early warning of equipment failures, optimized maintenance scheduling, reduced production losses, and extended equipment lifespan.
Smart Transportation
Real-time IoT analytics help optimize delivery routes, monitor fleet performance, and quickly respond to delays. An example is the IoT smart city app by Parker. By leveraging IoT data, companies can dynamically optimize routes, monitor vehicle health, analyze driver behavior, and reduce fuel consumption.
Supply Chain Management
IoT helps in tracking and managing assets throughout the supply chain, improving visibility and efficiency. An example is the supply chain management IoT app by ZillionSource. With IoT-powered insights, businesses can track inventory in real-time, monitor product conditions, optimize warehouse operations, and improve logistics planning.
Energy Management
IoT platforms help in monitoring and optimizing energy consumption, leading to more sustainable practices. An example is the energy IoT app by Oma Helen. By analyzing energy usage patterns, businesses can identify inefficiencies, optimize consumption, manage peak loads, and integrate renewable energy more effectively.
Best IoT Development Tools
-
Eclipse IoT: Eclipse IoT is an open source platform that enables IoT developers and IoT development companies to develop applications in Java. Eclipse IoT can be used to create IoT devices, cloud platforms, and gateways. The tool focuses on developing, adopting, and promoting open source IoT technologies.
-
Node-RED: Node-RED is an open-source visualization tool built on top of Node.JS and used to connect devices, services, and APIs for IoT. Node-RED is an easy-to-use interface developed by IBM's Emerging Technology division that allows you to tightly integrate and connect the hardware, APIs, or online services.
-
Tessel 2: Tessel 2 is a robust IoT platform used to build basic IoT solutions and prototypes. Integrate additional sensors and modules. This board can hold up to 12 modules, including RFID, GPS, camera, and accelerometer.
-
Arduino: Arduino is an open source prototyping platform that provides both IoT hardware and software. Arduino is a hardware specification applicable to interactive electronic devices and a suite of software that includes an integrated development environment (IDE) and the Arduino programming language.
-
Kinoma Create: Kinoma Create is a device that allows you to create a connection between two devices without much programming knowledge in JavaScript. Kinoma Create consists of many features required for developing small IoT applications.
-
Device Hive Based on Data Art's AllJyone, Device Hive is a free and open source M2M (Machine to Machine) communication framework. Launched in 2012, it is considered one of the most popular platforms for developing IoT apps.
Best Practices for Implementing IoT Cloud Platform
Prioritize Network Security
Use strong encryption, access controls, and authentication protocols to prevent unauthorized IoT device and data access.
Strengthen Device Security
Choose secure IoT devices, apply regular updates, and implement anti-tampering measures to protect against vulnerabilities.
Ensure Data Protection
Implement encryption, access controls, and anonymization techniques to secure IoT data and comply with privacy regulations.
Maintain Regulatory Compliance
Stay updated on IoT security and data privacy laws to ensure full compliance with industry standards.
Continuous Monitoring & Threat Detection
Use security monitoring tools, intrusion detection, and vulnerability scanning to detect threats and respond quickly.
Empower Employees with Security Awareness
Provide regular training on IoT security risks and best practices to enhance security preparedness.
Define Clear Business Objectives
Establish goals and KPIs to ensure the IoT analytics system delivers actionable insights and value.
Design for Scalability
Build an architecture that supports increasing devices, data volumes, and users without compromising performance.
Balance Edge & Cloud Processing
Process real-time data at the edge, perform complex analytics in the cloud, and use hybrid models for efficiency.
Ensure Data Accuracy & Consistency
Validate and standardize data with sensor health monitoring, completeness checks, and anomaly detection techniques.
Key Innovations and the Future of IoT Analytics
IoT is transforming industries by enabling real-time data collection, analysis, and decision-making. As deployments grow in scale and complexity, the supporting architecture and analytics will continue evolving. Organizations that embrace advanced IoT analytics will gain a competitive edge through efficiency, automation, and data-driven insights.
Key Innovations Driving IoT Analytics
-
AI and ML Integration – Predictive maintenance and real-time decision-making powered by on-device intelligence.
-
Edge Computing – Faster processing by reducing reliance on centralized cloud infrastructure.
-
5G Connectivity – Lower latency and higher speeds for seamless IoT communication.
-
Digital Twins – Virtual models of physical assets for monitoring and optimization.
-
Blockchain Security – Enhanced data integrity and trust in IoT ecosystems.
What’s Next for IoT?
-
Deeper integration of IoT, AI, and big data for smarter automation.
-
Privacy-focused analytics to meet regulatory and security demands.
-
Expansion into new sectors like healthcare, smart cities, and industrial automation.
-
More advanced edge analytics for real-time insights without cloud dependency.
-
Improved interoperability for seamless IoT ecosystem communication.
By adopting cutting-edge IoT analytics, businesses can unlock new opportunities, optimize operations, and drive innovation, making data their most valuable asset in the digital era.



























