
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
The wireless world of machine learning features an ascending need for powerful adjustable AI models. The time for single-sense AI is over because stakeholders now search for systems that comprehend reality similarly to humans through multiple sensory channels. Multimodal models represent the current frontier as they provide an efficient solution at scale. The AWS Neuron SDK is a critical tool for those who utilize cloud-based AI solutions, specifically within Amazon Web Services environments.
What Is AWS Neuron SDK and Its Benefits
AWS Neuron SDK is an exclusive development toolkit that enables users to maximize multimodal model performance on AWS. The software development suite of Neuron SDK serves as more than a typical library because it can maximize the performance of machine learning inference across Amazon Web Services Inferential and Trainum accelerators. Through its Neuron SDK interface, complex AI models can connect with powerful yet cost-efficient hardware from AWS. Through Neuron SDK, you can obtain maximum benefits from specialized chips without needing details about hardware complexities.
Key Benefits of AWS Neuron SDK for Machine Learning Developers
My experience in this field has demonstrated that any serious ML project needs efficient, scalable solutions. The Neuron SDK directly solves these problems by delivering multiple important benefits. First and foremost, performance optimization is baked in. Inferentia and Trainum experience maximum performance through Neuron SDK, enabling your applications to deliver quantitative speedups and decreased latency.
Then there’s the ease of integration. Your current projects most likely implement TensorFlow and PyTorch, which proves that you already work with widespread frameworks. The Neuron SDK integrates easily with popular frameworks so organizations can use existing models during workflows without major changes to their existing infrastructure. The SDK offers significant time savings together with lower learning barriers.
 Fig 1: Multimodal LLMs Processing Diverse Data Inputs
Fig 1: Multimodal LLMs Processing Diverse Data Inputs
Finally, cost efficiency is a major win. Deploying Neuron SDK generates optimized performance results, which lead to high productivity without extra expenditure. This optimisation directly results in lower operational costs for big-scale cloud deployments since these costs are top priorities across cloud systems.
Understanding Multimodal Model Deployment Challenges and Solutions
Let's step back and understand why deploying multimodal models at scale presents unique challenges.
Defining Multimodal Models
The fundamental purpose of a multimodal model is to function as an AI system that interprets information across diverse data types, including text, images, audio, video, sensor data, and additional modes of information. For example, an AI system could process image content by reading its captions while simultaneously hearing audio outputs and synthesizing a complete understanding of all presented data components. That's the power of multimodality.
Such models transform knowledge processing, robotics, recommendation systems and search functionalities because their advanced representation of the real world exceeds what single-source AI systems can achieve.
Challenges in Large-Scale Deployment
Widespread utilization of advanced models requires substantial work because of their intricate nature. Multimodal models bring difficulties in implementation because of their advanced complexity. First, computational demands are significantly higher. Multiple simultaneous data stream processing requires significant computing power and ample memory allocation. Then, data synchronization becomes critical – ensuring that data from different modalities is correctly aligned and processed in a coordinated manner adds another layer of complexity.
Furthermore, model complexity itself is amplified. Models incorporating multiple data streams have complex structures requiring fusion units alongside attention processing and individual elements for each data type. Deploying complex models alongside large datasets and heavy user loads demands proper infrastructure systems and deployment optimization approaches. Traditional deployments using CPU-based systems together with general-purpose GPU systems create bottlenecks that affect both system performance and expense levels.
AWS Neuron SDK's Unique Approach
This is where AWS Neuron SDK shines. It’s specifically designed to tackle these very challenges. Its unique approach lies in its deep integration with AWS Inferentia and Trainum chips. These aren’t your run-of-the-mill processors. They are custom-built by AWS, from the ground up, to accelerate deep learning workloads.
Neuron SDK leverages the architecture of these chips to provide hardware-level optimizations that are simply not possible with generic hardware. It handles the intricacies of mapping complex multimodal models to the Neuron architecture, optimizing data flow, and maximizing parallelism. This hardware-software synergy is the secret sauce that allows Neuron SDK to deliver exceptional performance and efficiency for large-scale multimodal deployments.
Getting Started With AWS Neuron SDK Installation and Setup
Okay, enough theory. Let's talk about getting your hands dirty. Getting started with Neuron SDK is more straightforward than you might think.
System Requirements
First, you’ll need an AWS environment, naturally. Neuron SDK is designed to run on specific Amazon EC2 instance types powered by Inferentia and Trainium. These instances are readily available and well-documented in the AWS ecosystem. You'll also need a compatible operating system – typically Linux-based distributions – and Python, the workhorse of the machine learning world. Make sure to check the AWS documentation for the most up-to-date system requirements, as they may evolve.
Installation Guide
Installation itself is quite streamlined. AWS provides clear and concise installation guides and readily available Neuron SDK packages. You'll typically use package managers like pip to install the SDK and its dependencies within your Python environment. The AWS documentation provides step-by-step instructions, and the process is generally well-automated.
Initial Configuration
Once installed, some initial configuration might be needed, depending on your specific environment and use case. This could involve setting up environment variables, configuring access credentials to AWS services, and potentially fine-tuning SDK settings for your hardware instance. Again, AWS provides ample documentation and examples to guide you through this initial setup.
Exploring AWS Neuron SDK Architecture and Core Components
Study of Neuron SDK core elements leads to a full understanding of its operational power.
 Fig 2: AWS Neuron SDK Workflow for Multimodal Model Deployment
Fig 2: AWS Neuron SDK Workflow for Multimodal Model DeploymentNeuron Runtime
The key component of SDK is Neuron Runtime, which functions as the execution engine. The execution engine serves as the mechanism that operates compiled models across Inferentia and Trainium hardware. Neuron Runtime functions as a model orchestra conductor, coordinating and optimising multiple components that run on hardware systems. Through the Neuron Runtime, developers can handle memory tasks and scheduling procedures and maintain communication with Neuron hardware while the low-level details remain abstracted from their view.
Compilation Tools
A model must undergo compilation before running on Neuron hardware devices. The Neuron SDK features compilation tools for these purposes. The compilation tools receive trained models from TensorFlow or PyTorch frameworks before being adjusted for implementation on the Neuron architecture. The compilation method includes optimising graphs alongside the fusion of operators and creating hardware-specific programming code. The compilation process is essential because it enables Inferentia and Trainium to reach their maximum performance potential.
Performance Optimization Techniques
Now, let's delve into the techniques Neuron SDK employs to achieve peak performance.
-
Operator Fusion: Combines multiple small operations into one, reducing memory overhead and improving efficiency.
-
Graph Optimizations: Refines computation graphs to eliminate redundancies and speed up execution.
-
Quantization: Uses mixed precision (FP16, BF16, INT8) to balance accuracy and performance.
-
Parallel Execution: Distributes workloads across Neuron cores for higher throughput.
-
Efficient Memory Management: Reduces data transfer overhead and optimizes cache usage.
-
Batch Processing: Processes multiple inputs at once to enhance inference speed.
Deploying Multimodal Models Efficiently Using AWS Neuron SDK
Deploying multimodal models effectively with Neuron SDK involves a structured process.
Model Preparation
The journey begins with model preparation. This involves ensuring your multimodal model is compatible with Neuron SDK. Typically, this means building your model using supported frameworks like TensorFlow or PyTorch and adhering to certain architectural guidelines. You might need to adapt certain layers or operations in your model to ensure optimal compilation and execution on Neuron.
Compilation Process
Next comes the compilation process, which we touched upon earlier. You’ll use the Neuron SDK’s compilation tools to convert your prepared model into a Neuron-optimized format. This process might involve experimentation and fine-tuning compilation parameters to achieve the best results for your specific model. AWS provides tools and documentation to help you navigate this process effectively.
Inference Optimization
Once compiled, the Neuron Runtime takes over for inference. But optimization doesn't stop at compilation. Neuron SDK provides runtime optimization techniques to enhance inference performance further. This includes techniques like operator fusion, kernel optimization, and memory layout optimizations, all happening behind the scenes within the Neuron Runtime to maximize throughput and minimize latency.
Performance Tuning and Scaling AI Workloads on Neuron SDK
The full potential of Neuron SDK for large-scale deployments will become accessible through effective performance enhancement alongside scalability improvements.
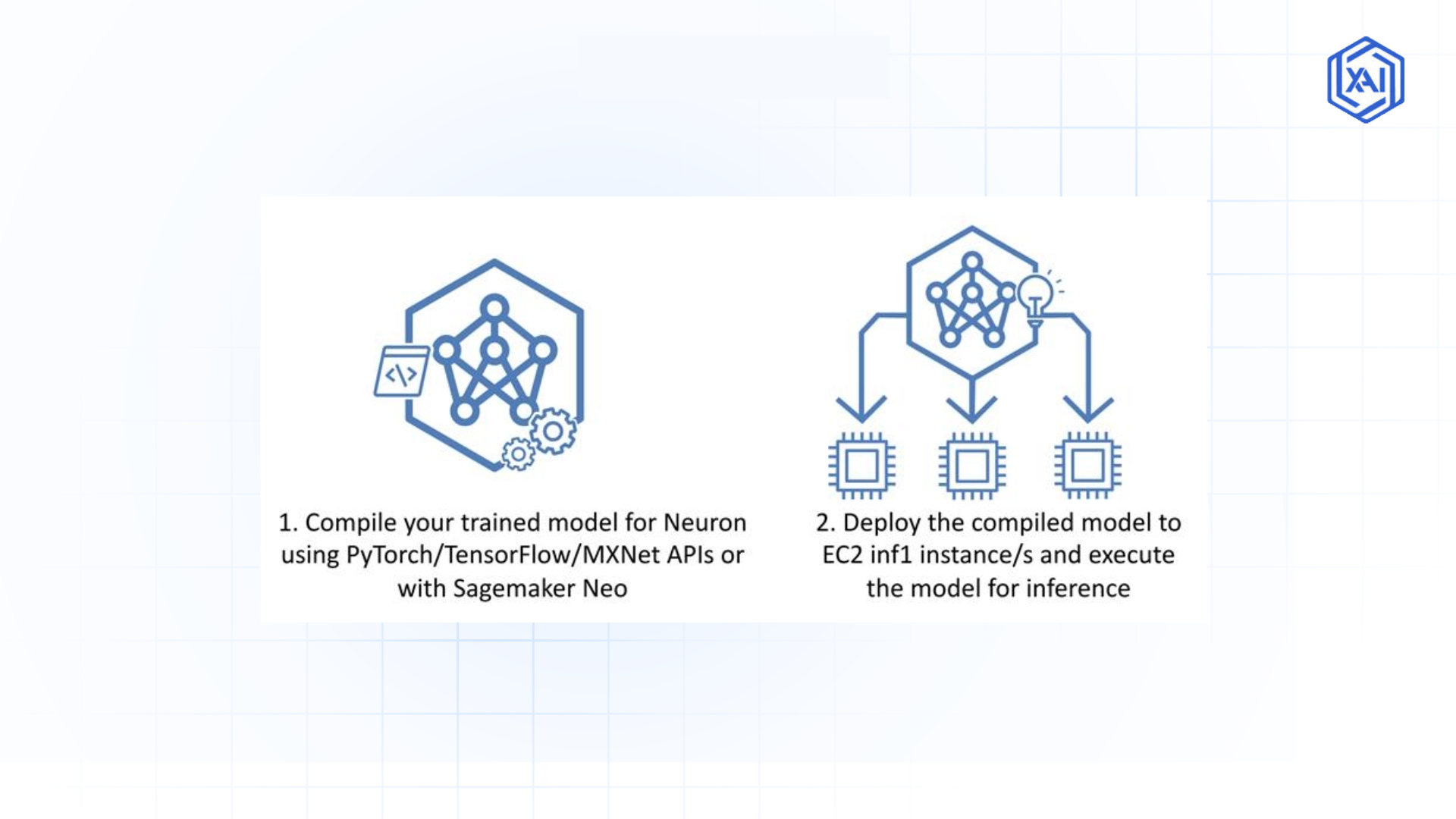 Fig 3: Compiling and Deploying AI Models With AWS Neuron SDK
Fig 3: Compiling and Deploying AI Models With AWS Neuron SDK-
Resource Management: Efficient resource management is paramount. Neuron SDK provides an interface allowing users to guide their models in utilizing Neuron hardware and system resources. The implementation of memory features, inter-thread communication systems, and process management functions exists as part of this platform. Routine resource management enables your models to operate effectively by preventing resource conflicts, which would result in performance limitations.
-
Parallel Processing: Forward processing remains essential to achieve larger inferencing operations scale. The Neuron SDK offers multiple parallel processing capabilities, enabling users to distribute their inference tasks via multiple Neuron cores combined with multiple Inferentia/Trainium chips and multiple instances. Twinned execution capabilities are vital because current applications need prompt response times and extensive data throughput for practical deployments.
-
Monitoring and Profiling: Competing performance demands visibility because you need it to refine performance. The Neuron SDK helps users monitor performance metrics through built-in tools that profile model behaviour across Neuron hardware. The tools deliver precious technical information users need to enhance model structure alongside compilation protocol and execution configuration refinement.
Best Practices for Model Deployment
The deployment process requires strict adherence to best practices because scaled-up systems demand this approach for success.
Advanced Use Cases for AWS Neuron SDK
Much beyond basic knowledge, we will examine advanced use cases.
Complex Multimodal Model Scenarios
Neuron SDK is suitable for situations involving complicated model connections across various modalities. Advanced models built with complex configurations and multiple data entry points can use Neuron SDK to process operations such as advanced video understanding systems, sophisticated medical image examination systems, and highly personalized recommendation systems. Neuron SDK delivers maximum value by enabling hardware optimizations of complex analytical systems.
Cross-Modal Inference
The signature aspect of advanced multimodal AI includes using one modality's insights to interpret another. This pattern is known as cross-modal inference. Through Neuron SDK, users gain effective control of cross-modal interaction, so their applications deliver complex functions such as visual question-answering text-to-image generation and audio-visual scene comprehension.
Edge and Cloud Deployment Strategies
Neuron SDK's primary orientation for cloud deployment also provides general benefits that apply to edge environments. The expanding edge computing solutions from AWS make it likely that Neuron SDK will assist in bringing high-performance multimodal inference operations nearer to the data sources for real-time low-latency edge applications.
Troubleshooting Common Challenges in AWS Neuron SDK Deployment
Every deployment experience includes at least one trouble. We will discuss typical deployment obstacles and provide instructions for rectifying them.
Common Deployment Issues
Different deployment issues typically include problems during the compilation process and runtime difficulties affecting performance speed. Compilation errors develop mainly because software models are incompatible or project configurations are wrong. Runtime performance bottlenecks may develop because of suboptimal resource usage, structural model constraints, and slow data preparation techniques.
Performance Bottlenecks
Recognising performance hurdles is essential for performance enhancement. The monitoring and profiling functions in Neuron SDK are applied to detect performance slowdowns. Model bottlenecks can occur in layers, during data-loading operations, and communication between processing pipelines.
Debugging Techniques
Successful debugging merges logging with profiling alongside systematic experimentation techniques. Neuron SDK enables model execution monitoring and profiling functions, which generate comprehensive execution data. You should conduct tests using various compilation parameters and runtime adjustments, together with model structure changes, to detect and fix problems.
Future of AWS Neuron SDK and Upcoming Innovations
The AWS Neuron SDK exhibits promising prospects that conform to the path of Artificial Intelligence development.
Emerging Trends
The growing demand for quick real-time inference, along with edge AI developments and complex multimodal models, will increase dependency on hardware-improved software solutions such as Neuron SDK. The future of AWS Neuron SDK includes sustained investment in hardware acceleration, model compression methods, and deployment optimization.
Roadmap and Upcoming Features
AWS invests strongly in Neuron SDK development by setting a roadmap that encompasses expanded support for frameworks, improved performance enhancements, and new capabilities to improve multimodal model deployment efficiency. Watch AWS documentation and announcements to receive the most current updates in their system.
Key Takeaways on Scaling AI With Neuron SDK
To wrap up, the AWS Neuron SDK is a powerful and purpose-built solution for deploying multimodal models at scale on AWS. It offers significant advantages in performance, efficiency, and cost-effectiveness by leveraging AWS Inferentia and Trainium accelerators. From streamlined installation to advanced optimization techniques, Neuron SDK provides a comprehensive toolkit for taking your complex AI models from the lab to real-world applications.



























