
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Generative AI Models and LLM Models
The use of data-driven machine learning (ML) has enabled the possibility of a new paradigm in research and development. ML has proven an effective tool for uncovering the structure-activity relationships in material data.
However, the paradigm shift faces challenges due to slow progress in data quality governance and the need for guidance on combining domain knowledge with data-driven analysis. These challenges are three key issues: high dimensionality of feature space vs. small sample, model accuracy vs. usability, and ML results vs. domain knowledge.
The key to resolving the above-mentioned issues and enabling accurate mining of structure-activity relationships lies in embedding domain knowledge into models with generative ability.
Types of Generative AI models
Generative AI or foundation models are designed to generate different types of content, such as text and chat, images, code, video, and embeddings. Researchers can modify these models to fit specific domains and tackle tasks by adjusting the generative AI's learning algorithms or model structures.
This section provides an overview of task-specific and general generative ai research, with a focus on the applications of generative ai models in materials research.
Task-specific GAN
1. Generative Adversarial Networks (GANs)
GAN, which stands for Generative Adversarial Network, is an advanced deep learning architecture consisting of two essential components: a generator and a discriminator. The generator's primary function is to generate synthetic data that closely resembles real data, while the discriminator is responsible for distinguishing between authentic and fabricated data. The generator enhances the authenticity of its produced data through adversarial training, while the discriminator effectively determines whether the data is real or synthetic.
Functioning as a generative model, GAN is commonly employed in deep learning to generate samples to enhance data augmentation and pre-processing techniques. Its broad application extends across various fields, such as image processing and biomedicine, where it proves valuable in producing high-quality synthetic data for research and analysis.
Explore more about GAN applications and its benefits
2. Diffusion model
Generative diffusion models can create new data using the data they were trained on. For instance, when trained on an assortment of human faces, a diffusion model can create new and lifelike faces with diverse features and expressions, even if they were not present in the original dataset.
The fundamental idea behind diffusion models is to transform a simple and easily obtainable distribution into a more complex and meaningful data distribution. This transformation is accomplished through a series of reversible operations. Once the model understands the process of transformation, it can generate new samples by starting from a point within the simple distribution and gradually spreading it towards the desired complex data distribution.
Discover the Intricacies of Generative AI Architecture
3. Variational Autoencoders (VAEs)
VAEs are generative models that combine the capabilities of autoencoders and probabilistic modeling to acquire a compressed representation of data. VAEs encode input data into a lower-dimensional latent space, allowing the generation of new samples by sampling points from the acquired distribution. With practical applications spanning image generation, data compression, anomaly detection, and drug discovery, VAEs exhibit versatility across various domains.
4. Flow model
Flow-based models are generative ai model that aims to learn the underlying structure of a given dataset. These models achieve this by understanding the probability distribution of the different values or events within the dataset. Once the model has acquired this probability distribution, it is capable of generating fresh data points that maintain identical statistical properties and characteristics to those of the initial dataset.
A key feature of flow-based models is that they apply a simple invertible transformation to the input data that can be easily reversed. By starting from a simple initial distribution, such as random noise, and applying the transformation in reverse, the model can quickly generate new samples without requiring complex optimization. This makes flow-based models computationally efficient and faster than other models.
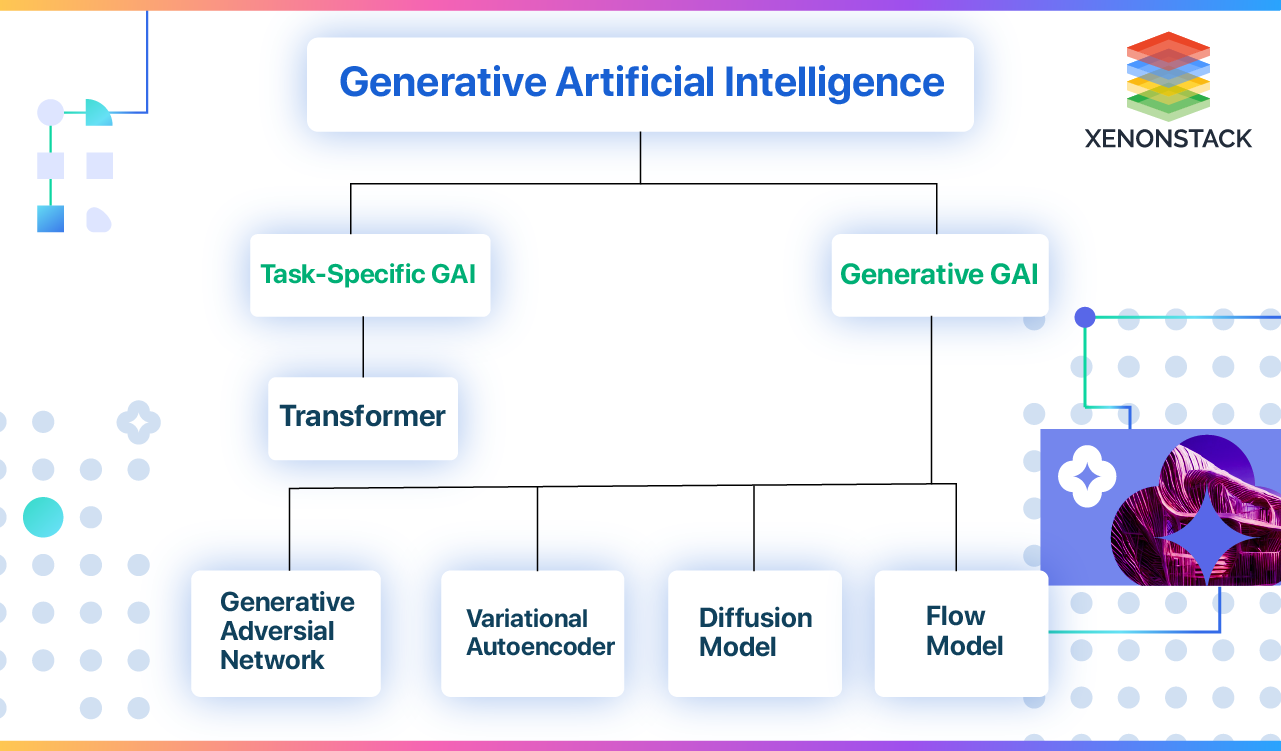
General GAI (Generative AI)
The development of big data and data representation technologies has enabled the generation of human-readable language from input data patterns and structures, allowing us to achieve objectives across various environments. This goal seeks to go beyond the language generation paradigm, restricted to adapting sample distributions for tasks.
1. The Generative Pre-Trained Transformer (GPT)
Initially showcased its potential for generating task-specific natural language through unsupervised pre-training and fine-tuning for downstream tasks. It utilizes transformer-decoder layers for next-word prediction and coherent text generation. Fine-tuning is used to adapt it to a specific task based on pre-training.
Let's explore more about Universal Language Model Fine-Tuning (ULMfit)
2. GPT-2
It expands on its predecessor's model structure and parameters and trains on various datasets beyond just web text. Despite exhibiting advanced results with zero-shot learning, it still falls under task-specific GAI.
Let's delve deeper into How to Build LLM and Foundation Models
3. GPT-3
It is a language model that employs Prompt to reduce the dependence on large, supervised datasets. It uses the linguistic structure of text probability to make predictions. The model is pre-trained on a vast amount of text, allowing it to perform few-shot or zero-shot learning. By defining a new cue template, it swiftly adjusts to new scenarios, even in situations where there is limited or no labeled data. This methodology proves advantageous for tasks that involve language comprehension and generation, as it minimizes the amount of data needed and enhances overall performance.
Recently, GPT-4, the latest model developed by OpenAI, was trained with an unprecedented scale of computations and data, surprisingly achieved human-like performance across almost all tasks, and significantly outperformed its predecessors. The introduction of GPT-4 represents a significant leap forward in the field of General Artificial Intelligence (GAI).
Building upon the success of the previous GPT models, GPT-4 showcases remarkable advancements in its ability to perceive and generate multimodal data, including text, images, and audio. This groundbreaking development holds great promise for the field of materials science research.. The formidable capabilities of GPT-4 in multimodal generation and conversational interactivity offer a promising outlook for materials science research.
4. LLaMA from Meta
Meta, formerly known as Facebook, has recently announced a new LLM in 2023. The LLM is called LLaMA, which stands for Large Language Model for Meta Applications, and comes with 600 billion parameters. LLaMA has been trained on various data sources, including social media posts, web pages, books, news articles, and more. Its purpose is to support various Meta applications such as content moderation, search, recommendation, and personalization. LLaMA claims to be more ethical by incorporating human feedback, fairness, and transparency in its training.
5. PaLM 2 from Google
The PaLM model has a new version called PaLM 2, which will be released in 2023 with 400 billion parameters. It is a multimodal LLM that can process and generate text and images. It has been trained with a large-scale dataset that covers 100 languages and 40 visual domains, making it capable of performing cross-modal tasks such as image captioning, visual question answering, text-to-image synthesis, and more. Palm 2 generalizes to new tasks and domains without fine-tuning, thanks to its zero-shot learning capability.
6. BLOOM
BLOOM generates text in 46 natural languages, dialects, and 13 programming languages. It has been trained on enormous data, totaling 1.6 terabytes, equivalent to 320 copies of Shakespeare's works. The model has the capability to process a total of 46 languages, which encompass French, Vietnamese, Mandarin, Indonesian, Catalan, 13 Indic languages (including Hindi), as well as 20 African languages. Although just over 30% of the training data was in English, the system is proficient in all mentioned languages.
7. BERT from Google
One of Google's most influential LLMs released in 2018 is BERT. BERT is an abbreviation for Bidirectional Encoder Representations from Transformers, which contains 340 million parameters. BERT, which is constructed based on the transformer framework, leverages bidirectional self-attention to acquire knowledge from extensive volumes of textual data. With its capabilities, BERT is proficient in executing diverse natural language tasks such as text classification, sentiment analysis, and named entity recognition. Additionally, BERT is widely used as a pre-trained model for fine-tuning specific downstream tasks and domains.
Generative AI Adversarial Networks
1. DALL·E 2
It is an AI system that can take a simple description in natural language and turn it into a realistic image or work of art.
2. StyleGAN 3
An AI system can generate photorealistic images of anything the user can imagine, from human faces to animals and cars. Furthermore, it provides a remarkable degree of personalization by allowing users to manipulate the generated images' style, shape, and pose.
Diffusion Models
1. Stable Diffusion
It is a generative AI model that creates photorealistic images, videos, and animations from text and image prompts. It uses diffusion technology and latent space, which reduces processing requirements and allows it to run on desktops or laptops with GPUs. With transfer learning, developers can fine-tune the model with just five images to meet their needs. It was launched in 2022.
2. DALL-E 2
An innovative language model developed by OpenAI showcases its extraordinary talent for converting textual descriptions into breathtaking images using an advanced diffusion model. The model uses contrastive learning to recognize the differences between similar images and create new ones. It has practical applications in design, advertising, and content creation, making it a groundbreaking example of human-centered AI.

How do generative AI models work?
Generative AI models function by scrutinizing patterns and information within extensive datasets, employing this understanding to create fresh content. This process encompasses various stages.
1. Data gathering
When training a generative AI model, the first step is clearly defining the objective. The objective should specify the kind of content that the model is expected to generate. A clear goal, whether images, text, or music, is crucial. The developer can tailor the training process by defining the objective to ensure the model produces the desired output.
2. Preprocessing
To create a quality Generative AI model, collect a diverse dataset that aligns with the objective. Ensure the data is preprocessed and cleaned to remove noise and errors before feeding it into the model.
3. Choose the Right Model Architecture
Choosing the exemplary model architecture is a crucial step in ensuring the success of your generative AI project. Various architectures exist, such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Transformers. Each architecture has unique advantages and limitations, so it is essential to carefully evaluate the objective and dataset before selecting the appropriate one.
4. Implement the Model
There is a need to create the neural network, define the layers, and establish the connections between them by writing code to implement the chosen model architecture; frameworks and libraries like TensorFlow and PyTorch offer prebuilt components and resources to simplify the implementation process.
5. Train the Model
Train a generative AI model involves sequentially introducing the training data to the model and refining its parameters to reduce the difference between the generated output and the intended result. This training process requires considerable computational resources and time, depending on the model's complexity and the dataset's size. Monitoring the model's progress and adjusting its training parameters, like learning rate and batch size, is crucial to achieving the best results.
6. Evaluate and Optimize
After training a model, it is crucial to assess its performance. This can be done by using appropriate metrics to measure the quality of the generated content and comparing it to the desired output. If the results are unsatisfactory, adjusting the model's architecture, training parameters, or dataset could be necessary to optimize its performance.
7. Fine-tune and Iterate
Developing a generative AI model is a process that requires continuous iteration and improvement. Once the initial results are evaluated, areas for improvement can be identified. By incorporating feedback from users, introducing fresh training data, and refining the training process, it is possible to enhance the model and optimize the results. Therefore, consistent improvements are crucial in developing a high-quality generative AI model.

Best Strategies for Training Generative AI Models
1. Choose the exemplary model architecture
When it comes to data generation, selecting the most appropriate model is a critical factor that can significantly impact the resulting data quality. The most used models are Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and autoregressive models. Each of these models has advantages and disadvantages, depending on the complexity and quality of the data.
VAEs are particularly useful for learning latent representations and generating smooth data. However, they may suffer from blurriness and mode collapse. On the other hand, GANs excel at producing sharp and realistic data, but they may be more challenging to train. Autoregressive models generate high-quality data but may be slow and memory-intensive.
When selecting the most appropriate model for particular requirements, it is crucial to compare their performance, scalability, and efficiency. This allows for a well-informed decision based on the project's specific requirements and constraints. Therefore, carefully considering these factors is critical to achieving the best results in data generation.
Explore the Advantages of Model-Centric AI for Businesses in 2023
2. Use transfer learning and pre-trained models
One practical approach for generative tasks is the application of transfer learning and pre-trained models. Transfer learning involves leveraging knowledge from one domain or task to another. Pre-trained models have already been trained on large, diverse datasets such as ImageNet, Wikipedia, and YouTube. The use of pre-existing models and applying transfer learning can substantially cut down on the time and resources required for model training. Furthermore, pre-trained models can be adapted to specific data and tasks. For example, developers may use pre-trained models like VAE or GAN for images and GPT-3 or BERT for text to generate images or text. Better results can be achieved by fine-tuning these models with their dataset or domain.
Discover the Inner Workings of the ChatGPT Model and Its Promising Future Applications
3. Use data augmentation and regularization techniques
The quality of generative tasks can be improved through data augmentation and regularization techniques. Data augmentation encompasses the creation of diverse data by applying transformations such as cropping, flipping, rotating, or introducing noise to the existing dataset. Conversely, regularization involves imposing constraints or penalties on the model to prevent overfitting and enhance generalization. These methods expand the training data's scope and diversity, mitigate the risk of memorization or replication, and enhance the generative model's resilience and variety. Techniques such as data augmentation can be used for random cropping or color jittering for image generation. In contrast, regularization techniques such as dropout, weight decay, or spectral normalization can be used for GAN training.
Discover about the Importance of Model Robustness
4. Use distributed and parallel computing
A helpful strategy to enhance generative tasks is to use distributed and parallel computing. This technique involves dividing the data and model among devices, such as GPUs, CPUs or TPUs, and coordinating their work. Distributed and parallel computing can accelerate training and enable the management of extensive, complex data and models. It also helps to reduce memory and bandwidth consumption and scale up the generative model. For instance, distributed and parallel computing techniques such as data parallelism, model parallelism, pipeline parallelism, or federated learning can be used to train generative models.
5. Use efficient and adaptive algorithms
Efficient and adaptable algorithms have the capability to swiftly and flexibly enhance the parameters and hyperparameters of the generative model. These include the learning rate, batch size, and number of epochs. These algorithms can improve the model's performance and convergence and reduce trial-and-error time. Several algorithms are available for optimizing generative models, including SGD, Adam, and AdaGrad. Additionally, Bayesian optimization, grid search, and random search algorithms are suitable for hyperparameter tuning. By leveraging these techniques, one can effectively fine-tune models to suit different data and tasks while addressing non-convex and dynamic optimization challenges. It is recommended that these methods be employed to achieve optimal results in generative modeling.
Evaluation & Monitoring Metrics for Generative AI
Language models such as OpenAI GPT-4 and Llama 2 can cause harmful outcomes if not designed carefully. The evaluation stage helps identify and measure potential harms by establishing clear metrics and completing iterative testing. Mitigation steps, such as prompt engineering and content filters, can then be taken. AI-assisted metrics can be helpful in scenarios without ground truth data, helping to measure the quality and safety of the answer. Below are metrics that help to evaluate the results generated by generative models:
-
The groundedness metric assesses how well an AI model's generated answers align with user-defined context. It ensures that claims made in an AI-generated answer are substantiated by the source context, making it essential for applications where factual correctness and contextual accuracy are critical. The input required for this metric includes the question, context, and generated answer, and the score range is Integer [1-5], where one is bad, and five is good.
-
The relevance metric is crucial for evaluating an AI system's ability to generate appropriate responses. It measures how well the model's responses relate to the given questions. A high relevance score signifies the AI system's comprehension of the input and its ability to generate coherent and suitable outputs. Conversely, low relevance scores indicate that the generated responses may deviate from the topic, lack context, or be inadequate.
-
Coherence is a metric that measures the ability of a language model to generate output that flows smoothly, reads naturally, and resembles human-like language. It assesses the readability and user-friendliness of the model's generated responses in real-world applications. The input required to calculate this metric is a question and its corresponding generated answer.
-
The Fluency score gauges how effectively an AI-generated text conforms to proper grammar, syntax, and the appropriate use of vocabulary. It is an integer score ranging from 1 to 5, with one indicating poor and five indicating good. This metric helps evaluate the linguistic correctness of the AI-generated response. It requires the question and the generated answer as input.
-
The Similarity metric rates the similarity between a ground truth sentence and the AI model's generated response on a scale of 1-5. It objectively assesses the performance ofT in text generation tasks by creating sentence-level embeddings. This metric helps compare the generated text with the desired content. To use the GPT-Similarity metric, input the question, ground truth answer, and generated answer.
- Know more about Generative Adversarial Network Architecture
- Explore more about How to Build a Generative AI Model for Image Synthesis
- Deep dive into the Introduction to Foundation Models
Conclusion of Training and Assessing Generative AI and LLM Models
Enterprises must consider the options when incorporating and deploying foundation models for their use cases. Each use case has specific requirements, and several decision points must be considered while deciding on the deployment options. These decision points include cost, effort, data privacy, intellectual property, and security. Based on these factors, an enterprise can use one or more deployment options.
Foundation models will play a vital role in accelerating the adoption of AI in businesses. They will significantly reduce the need for labeling, making it easier for businesses to experiment with AI, build efficient AI-driven automation and applications, and deploy AI in a broader range of mission-critical situations



























