
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What are Foundation Models ?
Foundation models are expansive machine learning models that undergo training on extensive datasets, enabling them to adapt to a wide range of tasks. These models, often trained using self-supervised learning or semi-supervised learning approaches, possess a notable advantage over task-specific models by leveraging unlabeled data for generalization. They have demonstrated exceptional efficacy in domains such as natural language processing, computer vision, and robotics. Prominent examples include GPT-3, which excels in generating text, language translation, and creative content, and BERT, which shows significant advancements in tasks like question answering and sentiment analysis. DALL-E 2, another remarkable model, can generate realistic images based on textual descriptions.
Foundation models typically employ deep neural networks comprising interconnected layers of neurons to grasp intricate data patterns. The scale of these networks can be immense, with millions or even billions of parameters, necessitating considerable computational resources for training. Nevertheless, their large size enables them to capture complex patterns and relationships effectively, contributing to their remarkable performance across diverse tasks.
Click here to know that how ChatGPT utilizes self-attention and encoding mechanisms to process user prompts and generate human-like responses.
History of Foundation Models
Early Beginnings: 1980s to 2000s
The foundation model journey began in the 1980s with feedforward neural networks for learning simple patterns. In the 1990s, recurrent neural networks (RNNs) emerged for processing sequential data like text. The 2000s introduced word embeddings, enabling models to understand semantic relationships between words.
The Rise of Transformers: 2010s
The 2010s saw the introduction of attention mechanisms and transformer architectures, significantly improving model performance and language modeling. In 2018, BERT (Bidirectional Encoder Representations from Transformers) demonstrated the power of transformers in understanding context and meaning in text.
The Foundation Model Era: Late 2010s to Present
Coined by Stanford HAI in 2021, the term "foundation model" refers to general-purpose models trained on broad datasets for various tasks. The late 2010s brought large language models (LLMs) like GPT-3, which showed that training on large datasets could enhance performance across diverse applications.
Recent Developments: 2022 Onwards
The releases of generative AI applications like ChatGPT and Stable Diffusion in 2022 brought foundation models into mainstream discourse, emphasizing their capabilities in content generation and creative tasks. Subsequent releases like LLaMA and Mistral in 2023 further fueled interest and scrutiny regarding open foundation models and their implications for innovation and ethics.
What Makes Foundation Models Unique?
Foundation models stand out for their versatility, enabling them to perform a wide range of tasks, such as natural language processing, question answering, and image classification, based on input prompts. Unlike traditional models focused on specific tasks, foundation models are adaptable and serve as the foundation for more specialized applications.
These models have evolved over the years, with BERT (2018) using 340 million parameters and GPT-4 (2023) leveraging 170 trillion parameters. The computational power required for these models has doubled every 3.4 months since 2012. Today, models like GPT-4, Claude 2, Llama 2, and Stable Diffusion can handle various tasks, from writing blog posts to generating images, solving math problems, and more, offering businesses powerful, multipurpose AI tools.
Why Foundation Modeling Matters?
Foundation models are transforming the machine learning lifecycle. While developing a foundation model from scratch can cost millions, using pre-trained models offers significant long-term advantages. It is faster and more cost-effective for data scientists to leverage these models to build new ML applications rather than start from zero.
Foundation models are especially valuable for automating tasks that require advanced reasoning. Some key applications include:
- Customer support
- Language translation
- Content and copywriting generation
- Image classification
- High-resolution image creation and editing
- Document extraction
- Robotics
- Healthcare
- Autonomous vehicles

Types of Foundation Models
There are many different types of foundation models, but they can be broadly categorized into three types:
-
Language models: These models are designed to process and understand natural language, allowing them to perform tasks like language translation, question answering, and text generation.
Examples of popular language models include BERT, GPT-3, and T5.
-
Computer vision models: These models are designed to process and understand visual data, allowing them to perform tasks like image classification, object detection, and scene understanding.
Examples of popular computer vision models include ResNet, VGG, and Inception.
-
Multimodal models: These models are designed to process and understand both natural language and visual data, allowing them to perform tasks like text-to-image synthesis, image captioning, and visual question answering.
Examples of popular multimodal models include DALL-E 2, Flamingo, and Florence.
Natural language processing is a field of artificial intelligence that helps computers understand, interpret and manipulate human language.
What Can Foundation Models Do?
Foundation models, though pre-trained, continue to learn from data inputs or prompts during inference, allowing them to generate comprehensive outputs. These models excel in a variety of tasks, including language processing, visual comprehension, code generation, and human-centered engagement.
-
Semantic Search - Foundation models are instrumental in enabling semantic search. These models leverage advanced techniques to understand the intent and context behind user queries, allowing for more accurate and relevant search results compared to traditional keyword-based approaches.
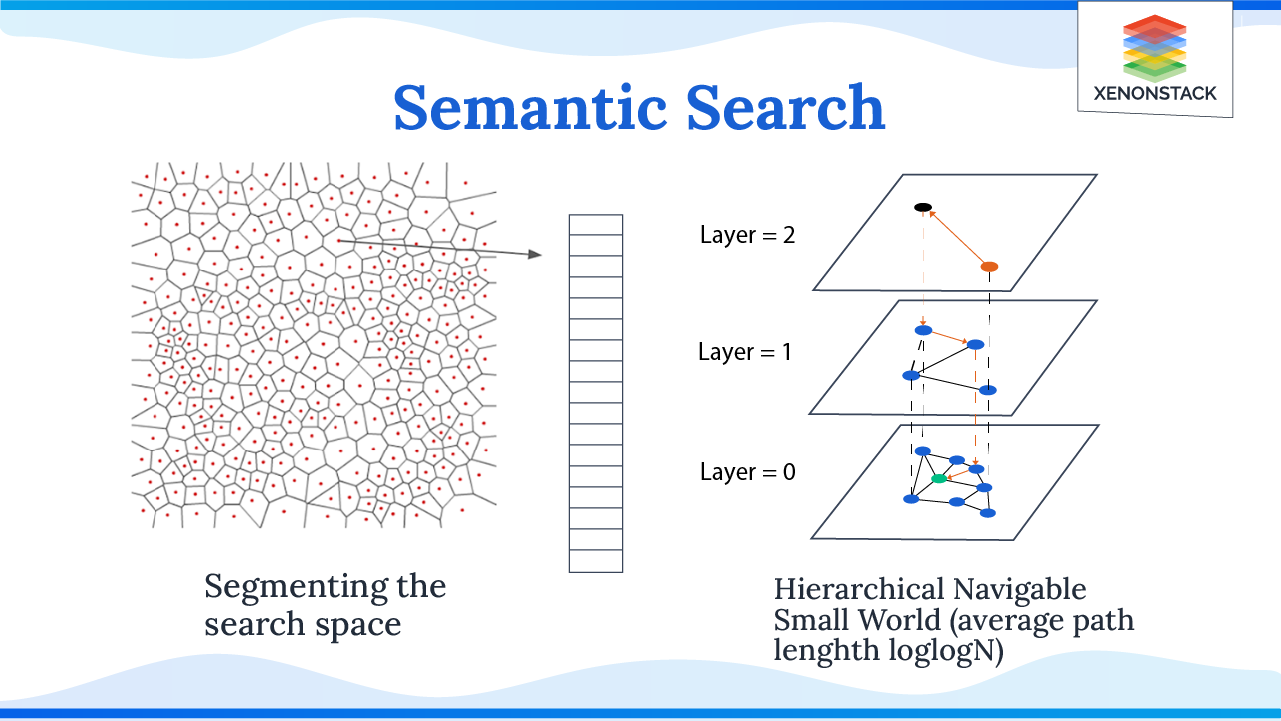
-
Language Processing: Foundation models can answer natural language questions, generate articles or scripts, and translate languages using NLP technologies.
-
Visual Comprehension: These models excel in computer vision, enabling image and object identification for applications like autonomous driving and robotics. They can also generate images from text and perform photo/video editing.
-
Code Generation: FMs can generate code in multiple programming languages from natural language inputs and can even help evaluate and debug code.
-
Human-Centered Engagement: Foundation models support decision-making by analyzing data, with potential applications in clinical diagnoses, decision support systems, and analytics.
-
Speech to Text: They can transcribe speech and provide video captions in multiple languages.
Foundation models also allow fine-tuning to create specialized AI applications, making them highly adaptable across industries.
Limitations of Foundation Models
-
Dataset Bias: Foundation models are trained on large-scale datasets that may contain biases present in the data. These biases can be reflected in the model's outputs, potentially leading to unfair or biased results.
-
Lack of Domain Specificity: Foundation models are trained on diverse data sources, which can limit their performance in specific domains or industries.
-
Interpretability Challenges: It can be difficult to understand and explain the inner workings of these models, making it challenging to trust their decision-making process and identify potential errors or biases.
-
High Computational Requirements: Training and utilizing foundation models often require significant computational resources, including powerful hardware and extensive memory.
-
Lack of Contextual Understanding: While foundation models have impressive language generation capabilities, they may still struggle with nuanced understanding of context, humor, sarcasm, or cultural references.
Future Directions of Foundation Models
Continual Advancements
Continual advancements in foundation models are expected in terms of model size, training methods, applications, interpretability, and security, leading to more powerful, efficient, and widely applicable AI systems with innovative applications.
Multimodal Capabilities
Future foundation models are expected to incorporate multimodal learning, enabling them to process and understand not only text but also images, audio, and video. This will open new opportunities for applications such as image captioning, video summarization, and speech recognition.
Collaboration and Community Development
The collaboration between researchers, developers, and the open-source community will play a crucial role in driving the future development and improvement of foundation models. Community efforts will foster innovation, knowledge sharing, and the democratization of AI technology.



























