
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Embarking on the Journey of Natural Language Processing
Natural Language Processing involves the ability of machines to understand and derive meaning from human languages.
Machines can understand human language. It could be in the form of speech/text. It uses ML (Machine Learning) to meet the objective of Artificial Intelligence. The ultimate goal is to bridge how people communicate and what computers can understand.
If we mathematically represent it, it contains the following terms:
- NLP: Natural Language Processing oversees processes such as decisions and actions.
- NLU: NLU (Natural Language Understanding) understands the meaning of the text.
- NLG: NLG (Natural Language Generation) creates the human language text from the structured data that the system generates to answer.
A subset technique of Artificial Intelligence which is used to narrow the communication gap between the Computer and Human. Click to explore about, Evolution and Future of NLP
Why do we need Natural Language Processing?
Specific jobs, such as Automated Speech and Automated Text Writing, can be completed in less time using this technology. As much data (text) is available, let's take advantage of the computer's untiring willingness and ability to execute multiple algorithms to complete tasks quickly.
Example :
01110000 01101100 01010100 01110110 01100101 01110010 01100001
As we have difficulty reading the above binary compared to reading a human language, computers have difficulty understanding human speech that may contain variability of spoken word, language words, dialects, mispronunciation, speech impediments, etc.
What are the Major Challenges of Using Natural Language Processing?
- Meaningful Words: Text may contain Homographs, such as a single spelling of a word that can have several meanings, and Homonyms, two words that sound similar yet have distinct meanings. Moreover, a complete sentence may have several grammatical syntax, desired message intent, and semantic purposes. It makes NLP extremely difficult. On the other hand, humans have a clear grip on the context of each word used and thus comprehend it, but it is difficult for machines.
- Parts of Speech and Phrase Structure: Language issues are not just words but become complicated in phrase and sentence structure. A sentence may contain various parts of speech with different roles. When everything comes together, new challenges arise, such as grammatical conventions and word dependency on each other.
- Deal with Complex data: Technology has changed our world and everyday life by creating unique tools and resources. There has been a tremendous increase in the amount of data we generate, upload, or utilize through all these cycles. It isn't easy and gets more complex to deal with this abundant data. Studying this data manually is not duck soup. Analyzing the context behind the text and then analyzing it to gather or extract something valuable from it requires a lot of manual labor. It needs human intervention, whether routing calls to that particular team in IVR or writing a summary or a brief description after going through long texts and papers. What if we make computers smart enough to understand human language, solve this problem, and convert this hard work into brilliant work? NLP can be used.
It is essential to consider all the challenges before building an NLP system to take corrective measures to reduce such issues.
Unlocking the Power of Natural Language Processing
Intelligent assistants like Siri and Alexa are now pervasive and can assist in almost all purposes in daily life.
The concept of how they work is not easy but understandable, which is Automatic language detection. The instructions are given in speech. Get our job done based on what we said. It enables the machine to understand your words and the context behind them. Machine learning algorithms are used here to process, "understand," and respond to written and spoken human language.
Natural language processing is a field of artificial intelligence that helps computers understand, interpret, and manipulate human language. It draws on various fields, including computer science and computer languages, to bridge the gap between human communication and computer literacy. It makes the process of breaking language into such an understandable and valuable format that it is easy to understand for both computer programs and individuals.
It Is important because it helps resolve language ambiguities and adds functional numerical structure to the data for many down-to-earth applications, such as speech recognition or text statistics. Its essential functions include tokens and segregation, lemmatization/stemming, partial marking, language acquisition, and semantic relationship identification.
NLP is becoming a need of every sector nowadays, and it should be a part of every industry whether it is public sector or private sector. Click to explore about, Natural Language Processing in Government
Unlocking the Power of Natural Language Processing
Text preprocessing is the first and most crucial step in building a model. Some basic steps that are performed are as follows:
- Sentence Tokenization: Splitting of sentences in the paragraph.
- Word Tokenization: Splitting words in a sentence.
- Lower Case conversion: Converting upper case into lower case.
- Removing Punctuations: In this phase, punctuation will be removed.
- Stop Words Removal: Commonly used words like a, an, the, etc., are called stopwords, and they should be removed before applying NLP as they don't help in distinguishing.
- Stemming or Lemmatization: Stemming is a process of transforming a word to its root form.
One of these two is done while preparing data for NLP. Mostly, lemmatization is preferred because lemmatization does a morphological analysis of the words.

Key Considerations for Natural Language Processing
The best practices are listed below:
Establish Good Team
It will decide the resources and skills a project needs and who is responsible for training, testing, and updating the model. An enterprise use case requires a team of 2-5 people. 1-2 people with data science skills can understand business goals. They will work on data, models, and output. Another half of the team will be subject matter experts representing the business.
Scope Selection
A user-centered design approach is required for successful virtual agents. Learning as much as possible about your target end-users and how they'll want or need to communicate with your business through a conversational platform is critical.
What circumstances will drive users to engage with a conversational solution? What queries or requests will the solution be requested to answer? The answers to these questions will determine how your classifier is trained.
Define Intent
The intent is a goal in the user's mind when writing a text or speaking something. It is essential to understand user and group examples accordingly.
In most underperforming models, the most prevalent underlying issue is intents that are either too wide or too particular (or a combination of the two). The "proper" level of specificity to cover is not always precise. There is an unavoidable degree of topic overlap in some domains. Consider intents in the verb/action part of a statement in general.
Discarding Stop Words
Stopwords are the most regularly occurring words in a text that give no valuable information. There, this, where, and others are examples of stopwords.
Assess Volume and Distribution
The Watson Assistant documentation advises at least five examples per intent, while domain-specific solutions perform better at 15–20 standards for many enterprises.
A significant difference in the number of training examples per intent can cause serious issues. Some plans can get by with just a few examples, while others may need more. It can be difficult and time-consuming to strike the correct balance. The requirement for more instances within specific intents is frequently driven by term overlap.
Keep your volume distribution within a specified range when training your initial model to establish a baseline performance reading. As a starting point, aim for an average of 15 examples per intent, but allow no fewer than seven and no more than 25 per intent.
After you've completed your first performance experiment, make any necessary adjustments based on the precision of each intent. Over-trained intentions are more likely to produce false positives, whereas under-trained dreams are likelier to have false negatives.
Start Small, Iterate, and Incorporate
A solution that does five things well will typically provide more excellent business value than a solution that does 100 things poorly. Begin with small. Iterate on your ideas. Expect a few reshuffles in intent categorization. Dialogue nodes may need to be altered as a result of this. As a result, before you start constructing further sophisticated rules to manage your inputs, focus on putting your essential ground truth in a stable performance condition.
Once AI solutions are exposed to real-world encounters, they can only improve. Make a plan to go over your logs. Incorporate sample examples and other significant learnings about how your users engage with the product into your next enhancement cycle.
What are the best tools for NLP?
- Natural Language Toolkit (NLTK): It supports almost every component, including categorization, tokenization, stemming, tagging, parsing, and semantic reasoning. There are often multiple implementations for each, allowing one to pick the particular algorithm that needs to be utilized. It also supports a wide range of languages. However, it displays all data as strings.
- SpaCy: In most cases, SpaCy is faster than NLTK but has only one implementation for each component. It represents data as an object, simply the interface to build applications. It can also integrate with several other tools and frameworks. It has a simple interface. But it does not support as many languages as SpaCy can.
- TextBlob: It is great for smaller projects, and if someone has just started with the technology, this is a perfect tool. It is an extension of NLTK, so many of NLTK's functionalities can be accessed in this.
- PyTorch-NLP: PyTorch-NLP has just been around for over a year, yet it already has a beautiful community. It's a fantastic tool for quick prototyping. It is primarily designed for researchers but may also be utilized for prototypes and early production workloads.
- Compromise: Compromise isn't the most advanced tool in the toolbox. It does not have the most potent algorithms or the most comprehensive system. But it is a fast tool with a lot of functionality and the ability to work on the client side. Overall, the developers compromised functionality and accuracy by focusing on a tiny package with more particular functionality that benefits from the user understanding more of the context around the usage.
- Nlp.js: Nlp.js is built on numerous other NLP tools, such as Franc and Brain.js. Many aspects of NLP, including classification, sentiment analysis, stemming, named entity identification, and natural language creation, are accessible through it. It also supports a variety of languages. It is a tool with a simple UI that connects to several other excellent programs.
- OpenNLP: It is hosted by the Apache Foundation and can be easily integrated with other Apache projects, like Apache Flink, Apache NiFi, and Apache Spark. It covers all its standard processing components. It allows users to use it as a command line or within the application as a library. It supports multiple languages. It is ready for production workloads using Java.
NLP processes large amounts of human language data. It is an end to end process between the system and humans. Click to explore about, Differences Between NLP, NLU, and NLG?
Use Cases of Natural Language Processing

Real-world applications :
Automatic Text Summarization
Automatic text summarization is shortening long texts or paragraphs and making a summary that conveys the intended message. Two main types of resume can be done:
- Extractive summary: In this method, summarization will be done based on the combination of meaningful sentences, which will be extracted directly from the original text.
- Abstractive Summary: This method is more advanced than the extractive as the output will be a new text. The aim here is to understand the general meaning of sentences, interpret the context, and generate new sentences based on the overall meaning.
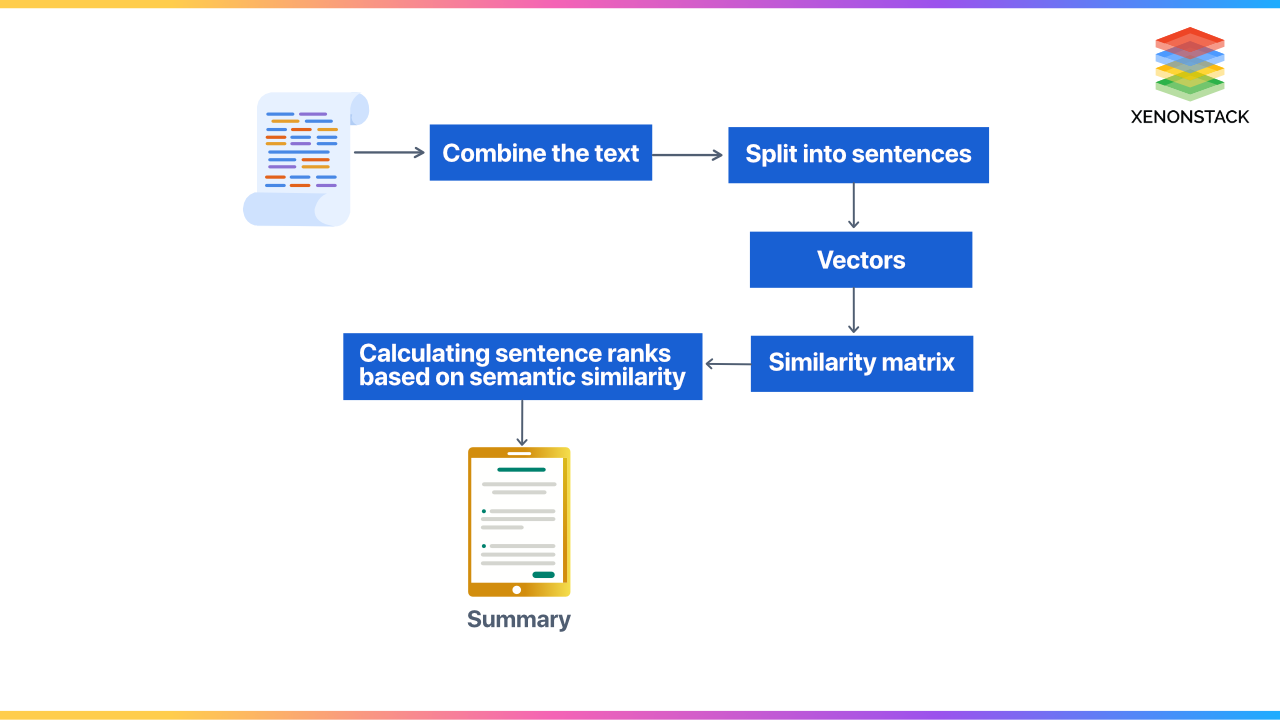
To do text summarization, the following are the steps that one needs to follow:
- Cleaning the text from filling words
- Tokenization: Making the sentences shorter
- A similarity matrix is created that represents relations between different tokens
- Calculating sentence ranks based on semantic similarity
- The summary generation selects Sentences with top positions (abstractive or extractive).
Sentiment Analysis
The Sentiment Analysis is of various types, a few of which are described below:
Sentiment Analysis in Social Media
It allows for uncovering hidden data patterns and insights from the data of social media channels. Sentiment analysis can analyze language or text used in social media posts, reviews, and responses and extract users' emotions and attitudes that could be used for several purposes. One is for companies to deliver things according to users' likes.
Sentiment Analysis of Product Reviews
This processing technique, known as sentiment analysis, can uncover the underlying emotional tone of a piece of text. It offers diverse studies that can identify positive or negative emotions within a sentence, customer reviews, textual judgments, voice analysis, and more. Valuable user experience data can be gathered by collecting product reviews from various sources such as review sites, forums, app stores, and eCommerce platforms.
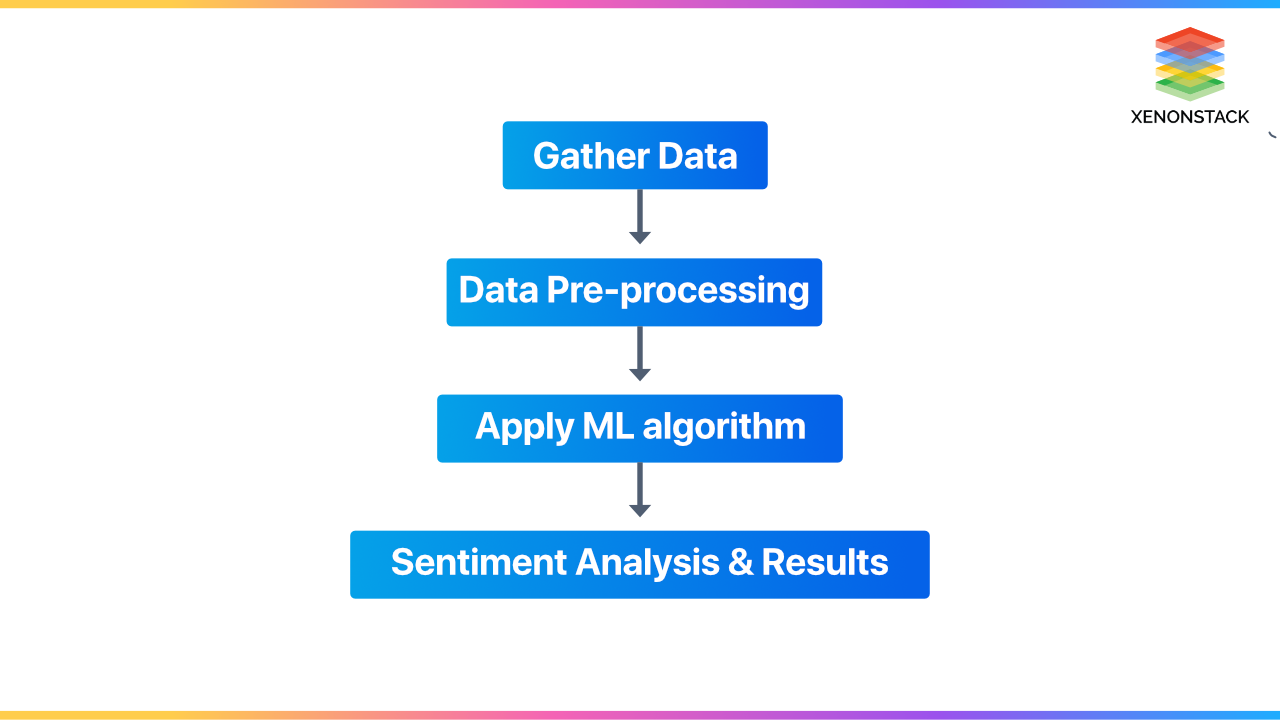
Machine learning algorithms follow the following steps:
- Convert data into structured form.
- The next step is to feed the data to the ML model.
- And then, sentiment analysis is done on it.
With the increasing market competition, sentiment analysis has become the need of time. Even established brands actively use this process to improve consumer knowledge. Whether you have a new or famous brand, you should use sentiment analysis in the ways mentioned above to improve user experience and stay ahead of competitors constantly.
Translator
To translate text from one language to another. It is more than just replacing the words. For effective translation, translators need to capture the meaning and tone of the input language accurately and then translate it to text with the same purpose and desired impact in the output language.
Spam Detection
NLP models can be used for text editing to detect spam-related words, sentences, and emotions in emails, text messages, and social media messaging applications.
Following are the steps that should be followed for spam detection :
- Data preprocessing includes removing stopwords and punctuation, converting text into lowercase, etc.
- Tokenization: Sampling text into smaller sentences and paragraphs.
- Part-of-speech (PoS) tagging: We can type a word to its corresponding part of a speech based on its context.
Then, this processed data will be fed to a classification algorithm (e.g., random forest, KNN, decision tree) to classify the data into spam or ham.
Conclusion to lavaregaing Comprehensive Guide to NLP
The working of NLP revolves around the text(language) and speech that refers to words in their raw form without considering the communication medium. There are some challenges in the current NLP process, but the effect of some of those challenges can be reduced with best practices, and the remaining challenges will be addressed shortly.
- Discover more about Azure Text Analytics and Natural Language Processing
- Read about Enterprise AI Chatbot Platform and Solutions



























