
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
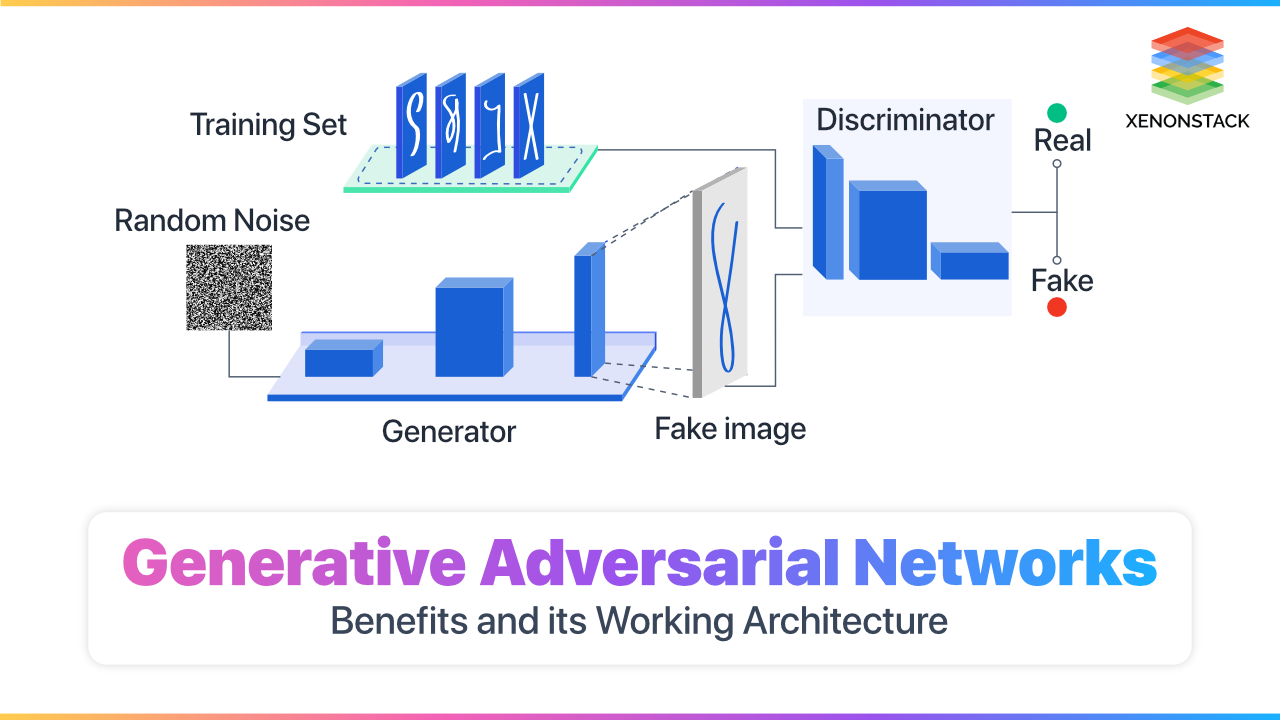
What is a generative adversarial network?
GAN (Generative Adversarial Networks) came into existence in 2014, so it is true that this technology is in its initial stages, but it is gaining very much popularity due to its generative as well as discriminatory power. This technology is considered a child of the generative model family. It is a division of unsupervised learning, which makes it a handful because it can also handle unsupervised learning, which is itself a big plus.
Basically, it is a combination of two sub-models. The first sub-model has a task to generate data samples, and the second sub-model does the task of receiving these data samples and do discriminating between training data and these data samples, which results in the accurately distinguished data.
An extra edge to choose a specific framework for a particular task from different frameworks available. Click to explore about, Open Neural Network Exchange
How do Generative Adversarial Networks work?
The concept is simple here one part generates new data, and the other part has the responsibility to validate these new instances with the help of old data, which is passed to the model. It can be visualized with the help of the example of a fake money creator (Generator) and a cop (Discriminator). The fake money creator generates fake money, and the cop has a task to identify the fake money. The beauty of this model is both models train themselves, and both try to enhance themselves. The following steps provide a brief detail of the process in a more technical way :
1. The generator imports an indiscriminate number of data samples and returns an example of data.2. This generated example of data is fed to the discriminator with actual data.
3. Now, the concept of probability comes into play here. The discriminator has the task of providing a probability score (between 0 and 1 where 0 signifies fake and 1 signifies valid instance).
4. So broadly speaking, there are two continuous vice-versa procedures run inside the GAN under which the discriminator shares a responsive loop with the real images to explore the ground truth (by determining which data instance is fake and which is real). On the other hand, the generator shares a responsive loop with the discriminator to determine the results of the discriminator without giving any concern to the truth.
Benefits of Generative Adversarial Networks
There are some points which make GAN different from other Image handling models and which can be considered as the benefits -
1. GAN can predict the corresponding new frame in a video.2. In the case of Image handling, it can also give a boost to the resolution of an Image.
3. If there is a necessity of Image to Image interpretation, for this purpose GAN model can be used. It means a firmly new image can be generated from an old image with the help of a GAN model.
4. With the help of the GAN model text to text-to-image generation is also possible, which means providing the description in the form of text to the GAN model, and it can generate a pragmatic photo of the specification.
Why adopting a Generative Adversarial Network is important?
The reasons why a generative model, specifically a GAN model, is important are -
1. It can signify and change the probability distribution, which has higher dimensionality.2. It can also be treated as a neural network example which also covers the basics of reinforcement learning.
3. It can also handle missing data and can make predictions on missing data which also signifies a support to the concept of semi-supervised learning.
4. It can work with different modal outputs.
5. Last but least, If there is a task related to the generation of the data. GAN is one of the models to go with.
How to adopt a Generative Adversarial Network?
So the basic steps that should be used to train Generative Adversarial Networks -
i. The basic step of any Deep Learning/Machine Learning is to understand the objectives and define them as problems.ii. The next step is to construct the architecture of a GAN neural network. Here the nature of the discriminator and Generator is decided, for example, whether it should be like a Convolution Neural Network or it should be similar to multi-layer perceptrons. This decision will totally depend on the nature of the problem.
iii. Choose the number for the epochs. These epochs will be used to train the discriminator. The number can be anything between 1 and infinity. The generator will generate the fake data, and the discriminator will be trained on this fake output.
iv. Repeat the process in a vice-versa manner, which means the generator should be trained on the output of the discriminator.
v. Select a number for another loop process, and in this looping process all steps from 3 to 5 will be repeated.
vi. Validate the fake generated data. If it seems to be nearly similar to the original data, the training should be stopped.
What are the best practices of a Generative Adversarial Network?
There are some tips to follow to export the best results from a GAN model -
1. Before training the generator part, the discriminator part should be trained. This step will set up a bright gradient before starting the whole process.
2. Generator as well as discriminator are both equally important parts of the GAN. They should be equally good so that an equilibrium between these models can be established. It takes a long due of time to train GAN models.
3. In the age of powerful GPUs, it can take hours to train themselves with the help of a GPU, so in the case of a CPU, it can take days. That is why it is better to use a GPU to train a GAN model.
4. During the training of the Generator part, the values of the discriminator part should be kept constant and in the same manner, the value of the generator part should be kept constant while training a discriminator.
Various Categories of GAN Models
Vanilla GAN
Basic setup with simple Generator and Discriminator as multi-layer perceptrons, using gradient descent for optimization.
Conditional GAN (CGAN)
Integrates additional 'y' parameters in the Generator for generating corresponding data, alongside labels input for Discriminator distinction.
Deep Convolutional GAN (DCGAN)
Utilizes ConvNets replacing perceptrons, devoid of max pooling, employing convolutional strides, and non-fully connected layers.
Laplacian Pyramid GAN (LAPGAN)
Employs multiple Generators/Discriminators in Laplacian Pyramid levels for high-quality images through down-sampling, up-scaling, and noise addition.
Super Resolution GAN (SRGAN)
Implements deep neural networks and adversarial networks to enhance details in higher-resolution image generation from low-resolution inputs.
Architecture of Generative Adversarial Networks (GANs)
With all the different sub-modules and highly complex architecture, at the end of the day GAN is a neural network by heart, so tools (such as WEKA) that are used to compose a deep learning architecture can also be used to architect a GAN model. Languages such as Python, R etc., can also be used for architectural GAN model. As stated above it is a deep learning type of model which is why the frameworks which are suitable for framing the deep learning model can also be used to architect the GAN model. Some of the examples of this framework are -
1. Tensorflow2. Caffe
3. Torch/PyTorch
4. MXNet
5. Keras
6. Chainer
Generative Adversarial Network Architecture
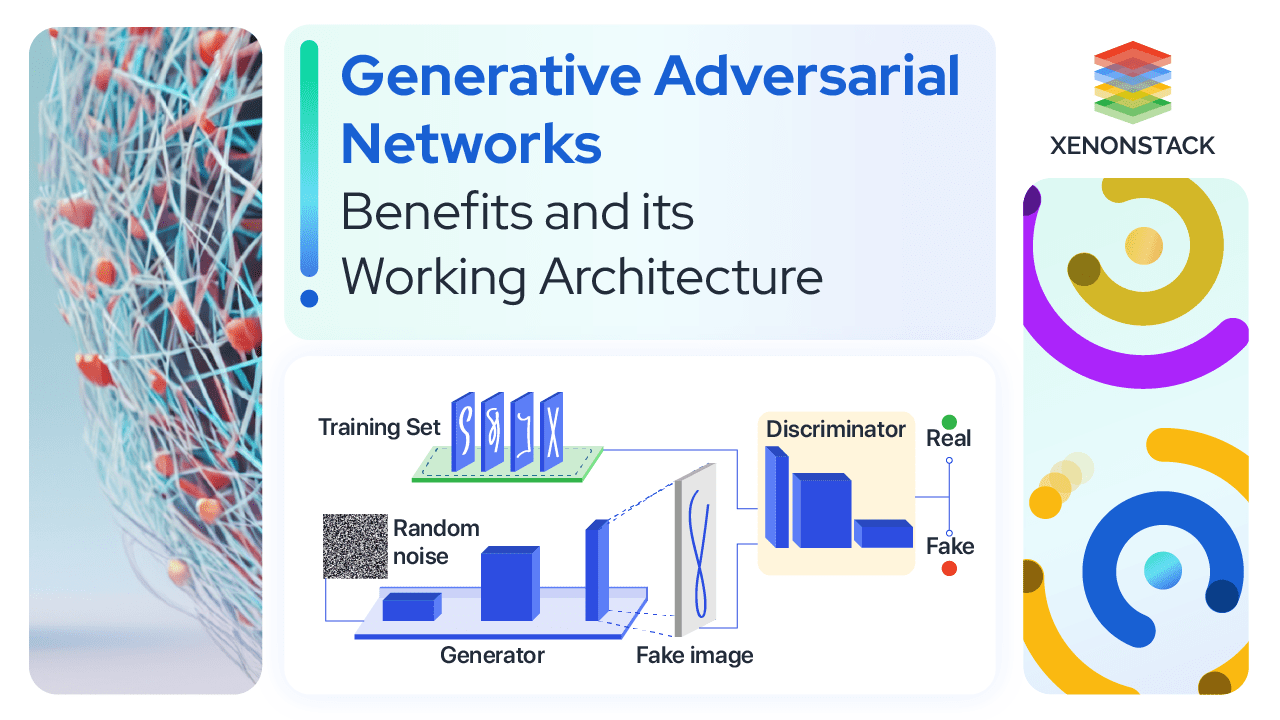
Generative Adversarial Networks (GANs) are deep learning architectures involving two neural networks - a generator and a discriminator - working competently to generate accurate data.
The generator network takes in a random input, such as a noise vector. It produces output data, such as images or audio samples, that attempt to mimic the training data distribution. The discriminator network then evaluates whether the generated data is real or fake and provides feedback to the generator to improve its output.
The architecture of a GAN is typically composed of the following components:
- Generator: The generator network inputs a random noise vector and generates a new data instance. The noise vector is typically drawn from a normal distribution. The generator can be any neural network, but it is usually a deconvolutional neural network (DCGAN) that learns to generate images.
- Discriminator: The discriminator network takes an input data instance and outputs a probability that the instance is actual. The discriminator can also be any neural network, but it is usually a convolutional neural network (CNN) that learns to classify images as real or fake.
- Loss function: The loss function for GANs combines two terms: the generator loss and the discriminator loss. The generator loss measures how well the generator can fool the discriminator. The discriminator loss measures how well the discriminator can distinguish between real and fake data.
- Training Process: The training process for GANs involves alternating between updating the generator and the discriminator. In each iteration, the generator generates a batch of fake data, which is then combined with a batch of real data to form a training set for the discriminator. The discriminator is trained on this combined dataset and is then used to classify a new batch of real and fake data. The generator is then updated based on the discriminator's feedback, and the process repeats.
- Evaluation: GANs are evaluated based on the quality of the generated data. This is typically done by measuring how well the generated data matches the statistics of the actual data. Other metrics, such as visual inspection and user feedback, can also be used to evaluate the quality of the generated data.
Applications of Generative Adversarial Networks (GAN)
GANs have been applied to various fields, and in this blog, we will explore some of the different applications of GANs.
Image and Video Synthesis
GANs have been extensively used for image and video synthesis. They can generate realistic images of faces, objects, and even landscapes. These images can be used for various purposes, such as art, advertising, or video game development. GANs can also be used for video synthesis, generating new frames that follow the same pattern as the real video.
Pros of Image and Video Synthesis
- GANs can generate high-quality images and videos that are often indistinguishable from real ones.
- GANs can be trained on a relatively small amount of data and can still produce high-quality results.
- GANs can be used to generate diverse and novel images and videos.
Cons of Image and Video Synthesis
- GANs can be challenging to train and require much computing power.
- GANs can suffer from mode collapse, where the generator produces a limited set of outputs and fails to capture the full range of possibilities.
Style Transfer
Style transfer is applying one image's style to another. GANs can perform style transfer by training a network to generate an image with the content of one image and the style of another. This technique has been used to generate images in the style of famous artists, such as Van Gogh or Picasso.
Pros of Style Transfer
- Style transfer can be used for artistic or practical purposes, such as in the fashion industry.
- Style transfer can be used to create new works of art that are visually interesting and unique.
- GAN-based style transfer can be performed in real-time, making it useful for interactive applications.
Cons of Style Transfer
- Style transfer can sometimes produce unrealistic or unappealing results.
- Style transfer requires much computational power, making performing in real-time on low-power devices difficult.
Data Augmentation
Data augmentation is the process of generating new samples from an existing dataset to increase size. GANs can be used for data augmentation by generating new samples similar to the real samples but different enough to provide additional training data. This technique can be helpful in situations with limited data available for training a deep learning model.
Pros of Data Augmentation
- Data augmentation can improve the performance of other AI models by providing them with more training data.
- GAN-based data augmentation can generate realistic and diverse data similar to the original data.
- GAN-based data augmentation can be performed quickly and efficiently.
Cons of Data Augmentation
- Data augmentation can sometimes produce unrealistic or unrepresentative data, which can negatively impact the performance of other AI models.
- GAN-based data augmentation requires a large amount of computing power, making it difficult to perform on low-power devices.
Image Restoration
GANs can also be used for image restoration, generating a high-quality version of a low-quality image. This technique is proper when the original image is of low quality, such as in medical or satellite imaging. GANs can also remove noise from images and enhance image resolution.
Benefits of Image Restoration
- Anomaly detection can identify rare or unusual data points of interest.
- GAN-based anomaly detection can be performed quickly and efficiently.
- GAN-based anomaly detection can be used in real-time applications like fraud detection.
Text-to-Image Generation
GANs can also be used for generating images based on textual descriptions. This technique can be helpful when a visual representation of a text description is needed, such as designing products or creating visual aids for the visually impaired.
Benefits of Text-to-Image Generation
- Text-to-image synthesis can generate images of products that do not exist in the real world, allowing companies to showcase their products uniquely and creatively.
- It can also generate images of rare or expensive products that are difficult to photograph.
Limitations of Text-to-Image Generation
- Text-to-image synthesis is challenging, as it requires the generator to understand the meaning and context of the text.
- It also suffers from mode collapse, where the generator produces a limited range of images.
- In conclusion, GANs have various applications in various fields, such as art, advertising, gaming, and data analysis. As research continues, GANs will likely be applied to even more fields.

A Comprehensive Approach
To understand more about unsupervised learning machine learning task that includes automatically identifying and reading patterns in input data for producing new outputs, we advise taking the following steps -- Learn more about Capsule Networks' Best Practices and Frameworks
- Read more about Generative AI for Infrastructure Management


























