
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Agentic AI transforms how enterprises approach text-to-image generation by enabling autonomous, adaptive, and scalable workflows. Unlike static AI models, Agentic AI empowers intelligent agents to collaborate, self-learn, and optimise visual creation processes in real time. When integrated with the Databricks Lakehouse Platform, organisations can unlock enterprise-grade text-to-image capabilities that combine creativity with governance, scalability, and performance.
Traditional generative AI solutions often struggle with limitations such as infrastructure complexity, fragmented data pipelines, and a lack of orchestration across multiple systems. Agentic AI on Databricks solves these challenges by leveraging autonomous agents to manage the entire lifecycle—data ingestion and model training to inference and optimisation—within a unified Lakehouse environment. This reduces operational overhead, accelerates iteration cycles, and ensures reliable, high-quality image outputs that align with enterprise standards.
The impact of this synergy spans industries such as media, e-commerce, design, healthcare, and manufacturing, where visual content plays a critical role. Businesses can generate personalised product imagery, create marketing assets at scale, develop medical imaging simulations, or design synthetic datasets for AI training. By combining Databricks’ unified data and AI platform with Agentic AI orchestration, enterprises streamline creative workflows and ensure compliance, trust, and adaptability in their AI-driven initiatives. This makes text-to-image generation with Agentic AI on Databricks a powerful enabler for innovation and competitive advantage.
The Role of Agentic AI in Text-to-Image
Text-to-image generation is a complex process that transforms natural language descriptions into realistic visuals. Traditional Generative AI approaches rely on pre-trained models but face scalability and adaptability challenges. Agentic AI enhances this by orchestrating autonomous agents collaborating, adapting, and optimising workflows on the Databricks Lakehouse Platform.
Instead of being a single static model, Agentic AI breaks down the process into specialised roles: data ingestion agents, model training agents, inference agents, and governance agents. This orchestration enables enterprises to build scalable, compliant, and adaptive text-to-image pipelines.
Why Databricks for Text-to-Image Workflows
The Databricks Lakehouse Platform provides the ideal foundation for deploying Agentic AI workflows. It unifies data engineering, machine learning, and analytics within a single ecosystem, ensuring reliable data pipelines for AI models.
Key benefits of using Databricks for text-to-image generation:
-
Unified data layer: Structured and unstructured data can be managed in one place.
-
Scalable compute: Optimised infrastructure for training large-scale generative models.
-
Model governance: Built-in compliance, monitoring, and lineage tracking.
-
Collaboration: Data scientists, ML engineers, and business teams collaborate seamlessly.
This combination ensures enterprises can operationalise Agentic AI without infrastructure bottlenecks or compliance risks.

How Agentic AI Enhances Text-to-Image
Unlike static AI models, Agentic AI agents adapt in real-time to changing contexts. For text-to-image generation, this means higher accuracy, relevance, and reliability.
Core Capabilities of Agentic AI in Text-to-Image
-
Autonomous Orchestration – Agents coordinate tasks across data ingestion, model training, and inference pipelines.
-
Continuous Learning – Feedback loops improve image quality with each iteration.
-
Contextual Awareness – Agents align generated visuals with enterprise-specific semantics.
-
Scalable Operations – Handle high-volume, multi-language, multi-domain data.
-
Compliance Built-in – Ensure responsible AI with bias detection, content safety, and regulatory alignment.
Text-to-Image Workflow on Databricks with Agentic AI
The workflow integrates multiple layers:
-
Data Preparation – Ingest and clean text and image datasets.
-
Feature Engineering – Extract semantic features from text prompts.
-
Model Training – Use GANs, diffusion models, or transformers orchestrated by Agentic AI.
-
Evaluation – Autonomous agents score images for accuracy, realism, and compliance.
-
Deployment – Serve models at scale with Databricks MLflow and Lakehouse.
-
Feedback & Optimisation – Reinforcement signals improve subsequent generations.
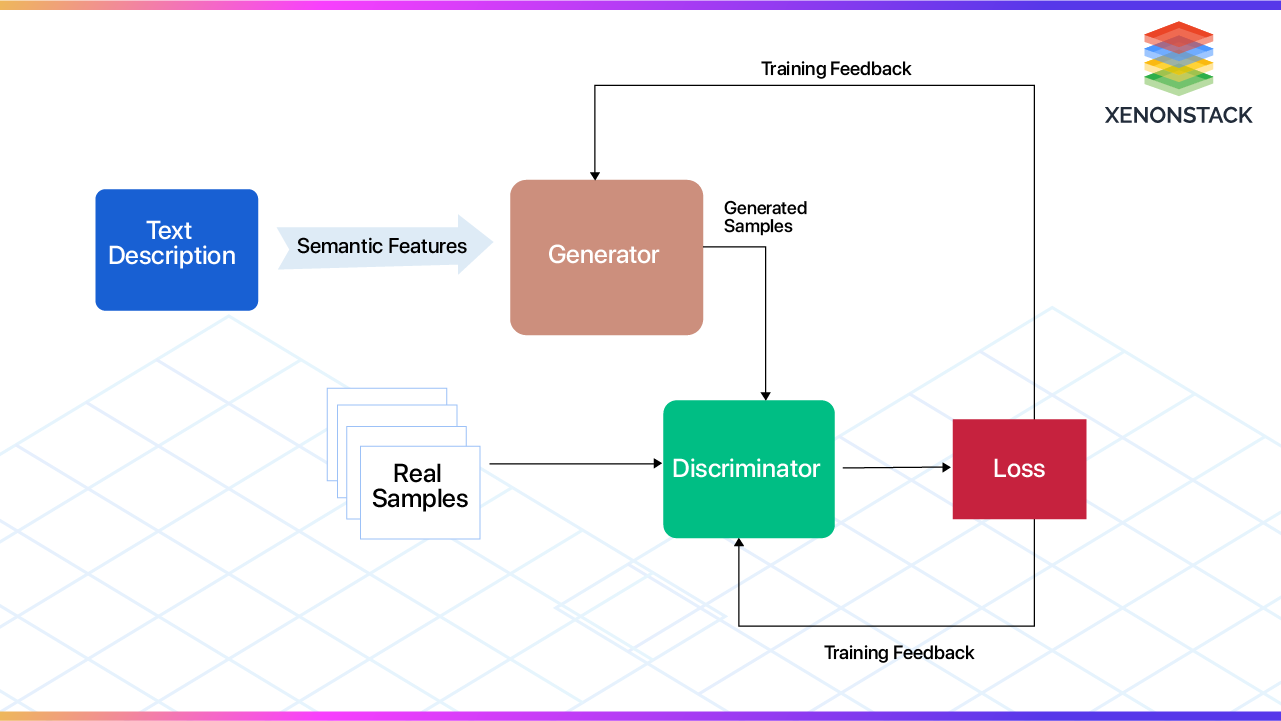
Role of GANs in Text-to-Image
The image you shared (GAN architecture) illustrates the foundation of text-to-image models.
-
Generator: Creates synthetic images from the semantic features of text descriptions.
-
Discriminator: Evaluates whether generated images are real or fake compared to actual samples.
-
Loss Function: Provides training feedback to refine outputs.
With Agentic AI, multiple agents can monitor and tune different stages of this GAN training cycle, ensuring better accuracy and faster convergence.
Industry Use Cases
Media and Entertainment
In the media and entertainment sector, Agentic AI on Databricks revolutionises the production of creative assets. Text-to-image generation can automate storyboarding, concept art, and visual effects, drastically reducing the time required for manual illustration. Autonomous agents manage data ingestion from scripts or creative briefs, while orchestration ensures consistency between storylines and visuals. Studios and content creators can scale production, explore multiple visual styles in real time, and maintain creative alignment across teams without heavy manual intervention. This not only accelerates production timelines but also reduces overall creative costs.
E-Commerce and Retail
For e-commerce platforms, visual content is a critical driver of customer engagement and conversion. With Agentic AI-powered text-to-image pipelines on Databricks, retailers can automatically generate personalised product images, marketing creatives, and catalogue visuals at scale. Imagine a customer searching for a “modern red sofa in a small living room”—AI agents can instantly generate realistic visuals tailored to the description, improving personalisation. Retailers benefit from faster campaign launches, reduced dependence on photographers, and the ability to localise content across different regions and audiences.
Healthcare
Healthcare organisations increasingly adopt text-to-image workflows to build synthetic datasets that enhance diagnostic models. Agentic AI agents on Databricks generate medical imaging simulations based on textual descriptions of symptoms, conditions, or anomalies. This approach preserves patient privacy while creating realistic datasets for training AI diagnostic tools. For instance, generating synthetic MRI scans or X-ray images allows medical researchers to improve algorithm accuracy, address data scarcity, and accelerate innovation in precision medicine. These capabilities are critical in regulated industries where compliance, security, and data privacy are paramount.
Manufacturing and Design
In manufacturing, design visualisation is pivotal in accelerating product development cycles. By combining Agentic AI with Databricks, companies can transform textual design specifications into prototypes and visual mockups in real time. Engineers and designers can describe features in text, and AI agents instantly generate visual concepts for review. Beyond design, synthetic image generation helps manufacturers train defect detection models by simulating product flaws or anomalies. This enables predictive quality control, reducing production waste and improving efficiency across supply chains.
Education and Training
The education sector benefits from AI-driven content generation by making learning experiences more engaging and interactive. With Agentic AI on Databricks, institutions can create customised visual training materials, interactive illustrations, and simulations from textual descriptions provided by educators. For example, a biology teacher could describe a “3D illustration of a cell structure,” and the AI system would generate detailed, accurate visuals. This democratizes access to high-quality educational content while supporting multilingual and localised learning experiences, making education more inclusive and effective.

Benefits for Enterprises
Enterprises gain measurable impact from Agentic AI-driven text-to-image on Databricks:
-
Faster innovation – Accelerated image generation pipelines reduce time-to-market.
-
Cost efficiency – Autonomous orchestration lowers infrastructure and manpower costs.
-
Improved compliance – In-built governance ensures responsible AI adoption.
-
Enhanced creativity – Teams scale visual production without sacrificing quality.
-
Decision intelligence – AI-driven insights improve marketing, design, and R&D strategies.
Security, Compliance, and Trust
When deploying text-to-image models, enterprises must address:
-
Bias Mitigation – Agents detect and minimise harmful or biased outputs.
-
Content Safety – Automated filtering prevents inappropriate imagery.
-
Data Privacy – Databricks ensures compliance with GDPR, HIPAA, and enterprise policies.
-
Auditability – Every generated asset is tracked for transparency and accountability.
Comparing Traditional vs. Agentic AI Approaches
| Aspect | Traditional Generative AI | Agentic AI on Databricks |
|---|---|---|
| Workflow Management | Manual, fragmented pipelines | Autonomous orchestration with adaptive agents |
| Scalability | Limited by infrastructure | Elastic scaling with Databricks Lakehouse |
| Governance | Basic model monitoring | Advanced compliance, bias detection |
| Adaptability | Static model performance | Real-time contextual adaptation |
| Enterprise Readiness | Experimental, siloed | Production-grade, decision-centric |
Measuring Business Impact
To evaluate the success of Agentic AI text-to-image initiatives, enterprises can measure:
-
Time-to-generation: Faster output cycles.
-
Quality scores: Visual realism and semantic accuracy.
-
Operational cost savings: Reduced infrastructure and labour overhead.
-
Adoption rates: Increased cross-team usage of generated visuals.
-
Revenue growth: Faster campaign launches, better product visualisation, higher customer engagement.
Future of Text-to-Image with Agentic AI
The future lies in compound AI systems, where multiple specialised agents collaborate across multi-modal tasks. For text-to-image, this means combining:
-
Language Agents – Refine textual input for precision.
-
Vision Agents – Optimise image rendering quality.
-
Compliance Agents – Enforce responsible AI standards.
-
Optimisation Agents – Improve cost-performance balance.
With Databricks as the foundation, enterprises can build next-generation creative pipelines that blend automation, governance, and innovation.
Conclusion: The Future of Text-to-Image with Agentic AI
Agentic AI for text-to-image generation on Databricks enables enterprises to create scalable, secure, and intelligent workflows for visual content automation. By leveraging the Lakehouse architecture, organisations achieve faster innovation, reduced costs, and improved governance. This synergy is not just about generating images—it’s about transforming enterprise creativity and decision-making with intelligent, autonomous agents.
Enterprises that adopt this approach will gain a competitive edge, where AI-generated visuals are accurate and scalable but also trustworthy, compliant, and strategically aligned with business goals.



























