
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Mlops for TinyML
Nowadays, in devices like AI cameras, AI washing machines, and AI electrical gadgets, Machine Learning is utilized to make sense of noisy sensor data. The problem with embedded devices is that they are small and operate on battery power. Machine Learning models require a significant amount of computing power. It can't be used to make models on devices that run on batteries. Tiny Machine Learning (tinyML) is used in this case. tinyML is a branch of machine learning that focuses on creating and implementing machine learning models on low-power, small-footprint microcontrollers such as Arduino.
MLOps is all about advocating for automation and monitoring at all the above steps. Click to explore about, MLOps Processes and its Best Practices
The neural network model can run on any board in tinyML with less than 1mW of power. It indicates that a battery-powered coin item will last a year. As a result, the gadget is small enough to fit into any environment and function for long periods without requiring human input.
Why do we need TinyML?
tinyML allows machine learning models to be run on tiny microcontrollers. There are a variety of devices, including Raspberry Pi and ESP32. These are fantastic devices, but even the tiniest Pi consumes hundreds of milliwatts, comparable to the main CPU. It requires a battery compared to a smartphone to keep one going for even a few days, making untethered experiences challenging to achieve. Because tinyML consumes less than one milliwatt of power, one must look to embedded devices for our hardware platforms. tinyML, which uses extremely little power and can execute machine learning algorithms, will be operated on such devices.
tinyML is distinguished by:
- its compact and low-cost devices (microcontrollers)
very low power usage - memory capacity is limited
- low lag time (almost immediate) integrated machine learning algorithms analysis.
A process where developers combine their changes back to the main branch. Click to explore about, Continuous Integration vs Continuous Deployment
What are the Applications of TinyML?
Specific applications that are anticipated to become accessible in the next years:
Mobility
By using tinyML to sensors that collect real-time traffic data through effective routing, companies like Swim. AI employs tinyML to stream data to increase passenger safety and cut congestion and pollution.
Factory of the Future
tinyML can help manufacturers avoid downtime due to equipment failure by allowing real-time choices. It can notify workers when preventative maintenance is required based on the state of the equipment.
Retail
TinyML can prevent things from running out of stock by monitoring shelves in-store and giving quick warnings as item numbers fall.
Agriculture
Animal ailments put farmers in danger of losing a lot of money. Data from cattle wearables that track vital signs such as heart rate, blood pressure, and temperature can help anticipate disease outbreaks and epidemics.
How TinyML Works?
Embedded tinyML algorithms use the following ways to work within the considerable resource limits imposed by tinyML:
Rather than model training, just inference of a pre-trained model is used.
For example, quantization minimizes the memory needed to hold numeric quantities by converting four-byte floating-point numbers to eight-bit integers (1 byte each). Knowledge distillation assists in discovering and remembering just the most significant characteristics of a model.
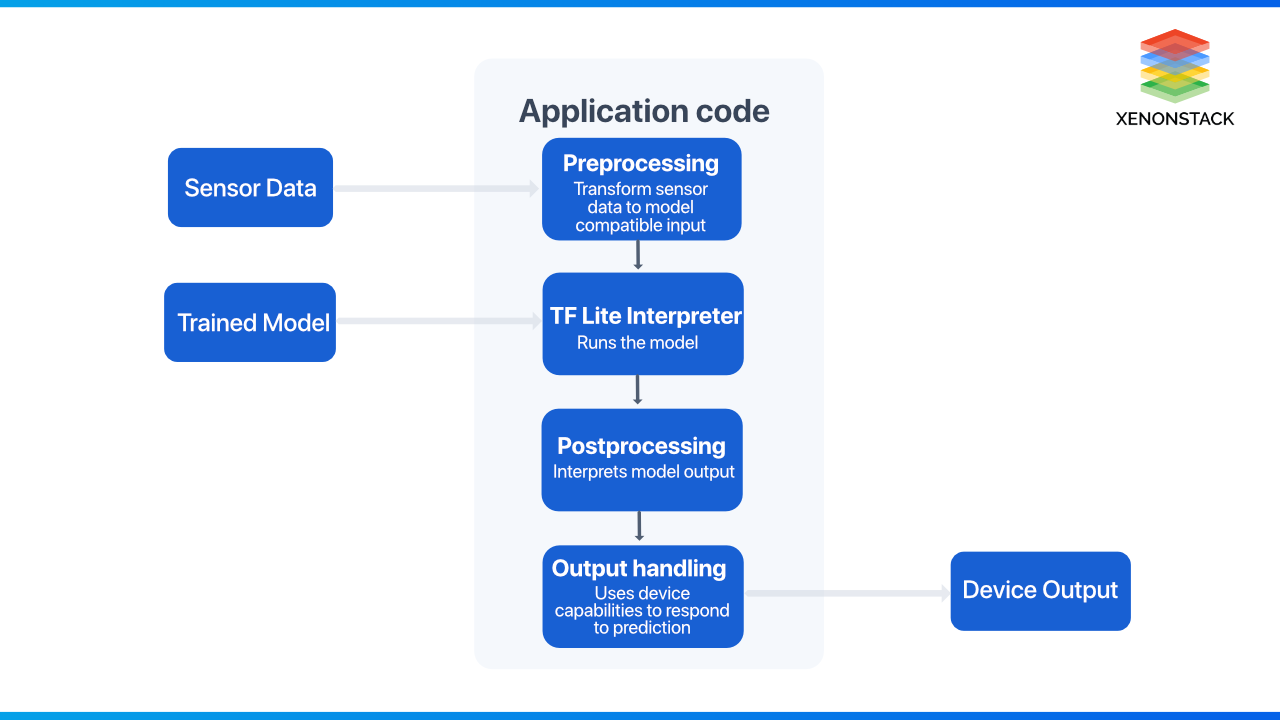
Some of these approaches may reduce model accuracy. For example, pruning and quantization neural networks limit the granularity with which a network can capture interactions and infer results. As a result, in tinyML, there is a necessary trade-off between model size and accuracy, and implementing these techniques is an essential aspect of tinyML system design.
The market for MLOps solutions is expected to reach $4 billion by 2025. Click to explore about, MLOps: What You Need To Know.
How to Implement TinyML?
A few machine learning frameworks support tinyML applications. These are the following:
TensorFlow Lite
While tinyML is still a young and experimental area, TensorFlow Lite Micro is one of the most widely used frameworks, which means one will benefit from a lot of community knowledge and help in projects.
Edge Impulse
Edge Impulse is a platform designed exclusively for + development. Edge Impulse is undoubtedly the easiest way for anybody to collect data, train a model, and deploy it on a microcontroller.
OpenMv
Another tinyML development platform, this time focusing on computer vision applications, is OpenMV. This covers object detection and picture categorization using machine learning on any image or video.
What are the Applications of TinyML?
Applications of TinyML are listed below:
-
Agriculture Sector: To identify illnesses in plants by taking a photo of them.
-
Industries: To identify machine issues ahead of time
-
Healthcare Industry: To prevent illnesses like dengue fever and malaria from spreading.
-
Aquatic Life Conservation: To Monitor the whales during strikes in busy shipping lanes.
What Software do we need for TinyML?
Most developers utilize TensorFlow and Keras to create and train deep learning networks. A TensorFlow model is a set of instructions instructing an interpreter on turning data into an output. One can load this trained model into memory and run it via an interpreter when to utilize it. Fortunately, TensorFlow has an interpreter that allows models to be executed on these small, low-power devices. TensorFlow Lite for Microcontrollers is a variation of TensorFlow Lite that was built to run on embedded devices with only a few tens of kilobytes of RAM. One can use TensorFlow Lite for the microcontroller's C++ library to load the model to the device and generate predictions. The model is then fed this altered data and subsequently utilized to produce predictions.
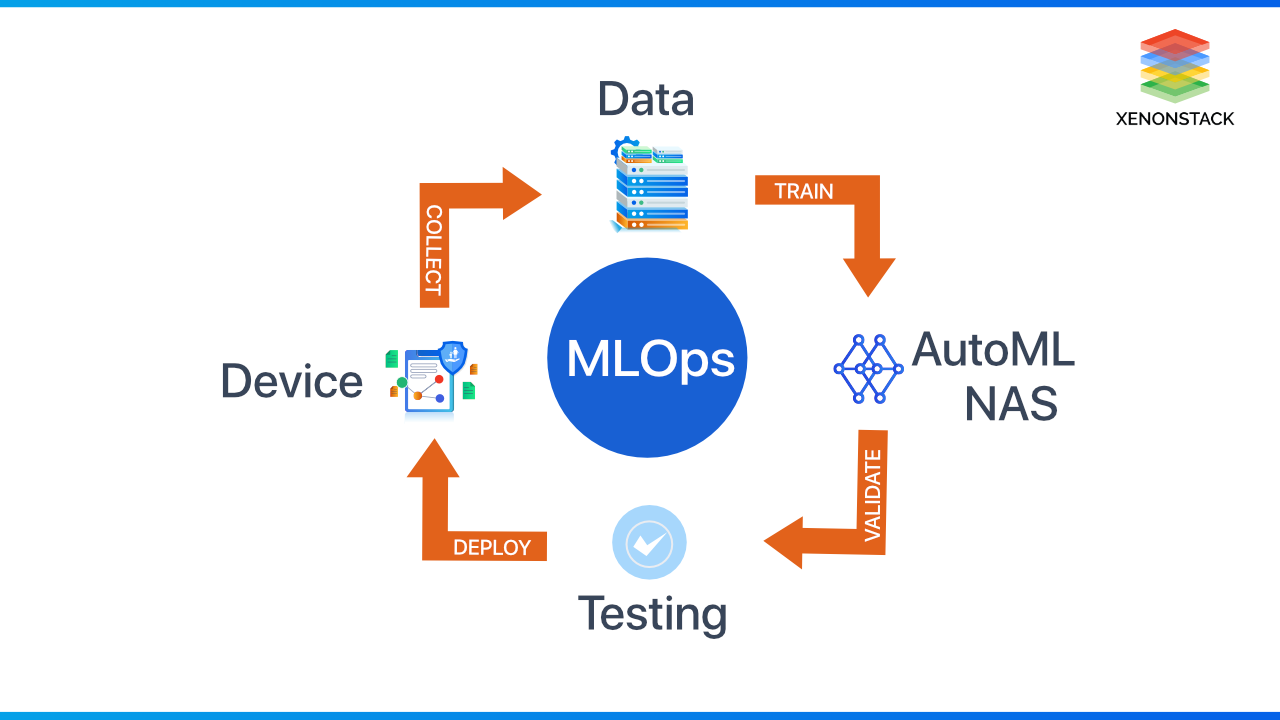
Scaling TinyML through MLOPs
Applied ML engineers must be able to handle production deployments. To design, monitor, and modify a tinyML application, use "ML operations" (MLOps). MLOps automates the whole operation. From the standpoint of entire MLOps platforms, they handle and process data, train machine learning models, version them, and assess, compare, and deploy them. Hundreds of thousands of gadgets might be part of the ecosystem. The above approach introduces the advantages of an automatic ML workflow, which include managing the overwhelming complexity of ML deployments, reducing the burden of maintaining in-house ML knowledge, being more scientific, easing long-term maintenance, and improving the model's performance in the field.
Furthermore, tinyML as a service (tinyMLaaS) enables production environments to easily manage and integrate heterogeneous tinyML devices. A highly fragmented ecosystem may develop because embedded tiny ML devices, from the ML compilers through the operating system and ML hardware, are tailored to achieve ultra-low-power energy efficiency. When the hardware changes, fragmentation affects the mobility of a precompiled ML inference model. A new "as-a-service" abstraction is needed to enjoy the efficiency benefits of hardware heterogeneity while managing the fragmented ecosystem. To produce the suitable constructed inference model, a software abstraction layer gathers information about the target device, such as the CPU type, RAM and ROM sizes, accessible peripherals, and underlying software.
This produced inference model is then automatically downloaded to the specified device, and the procedure is repeated for all additional devices. The model must then be recompiled for each device, increasing deployment complexity. tinyMLaaS poses privacy and security problems for the model and the data since it permits firmware-over-the-air (FOTA) and software-over-the-air (SOTA) upgrades.
TinyML is making its way into the mix in a world increasingly driven by IoT solutions. While there are large-scale machine learning applications, their usefulness is restricted. Smaller-scale applications are frequently required. A web request might take a long time to deliver data to a huge server, which is subsequently processed by a machine learning algorithm and returned. Instead, using machine learning applications on edge devices could be a better option.
- Discover more about MLOps Platform
- Explore the Top 7 Layers of MLOps Security



























