
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Kubernetes - A Container Orchestration Platform
In today's rapidly evolving digital landscape, the demand for cloud computing is skyrocketing. Whether it's a small startup or a large enterprise, organizations are striving to ensure that their resources and data are accessible anytime, anywhere. However, this level of availability comes at a cost. The traditional approach of installing physical machines everywhere and managing data across multiple locations is not only expensive but also inefficient.
Fortunately, the advent of cloud technology has revolutionized the way businesses operate. With cloud computing, organizations can seamlessly access and utilize resources without any geographical limitations. Major cloud providers like AWS, Google, and Microsoft Azure have paved the way for this transformation. Along with the cloud, other concepts such as containers have emerged as game-changers in the industry.
PostgreSQL is a powerful, open-source Relational Database Management System. Click to explore about our, PostgreSQL Deployment in Kubernetes
This is why the cloud came to light. With the cloud, everything was readily available and could be used by any business, small or big, without worrying about the things mentioned above. The major cloud providers AWS, Google, and Microsoft Azure. A few more concepts came with the cloud, such as images, containers, etc. Let's talk about containers. What are these? So, in simple words, reliable in any computing environment.
Yes, Containers provide us with many things, but they also need to be managed and linked to the outside world for other processes such as distribution, scheduling & load balancing. This is done by a container orchestration tool like Kubernetes. So, when we talk about containers, KUBERNETES comes attached. Maybe I'm wrong, but within the past few years, it has made its place in this cloud world as a container orchestration tool. It is built by google as per their experience in using containers in production. And Google has made sure that it is the best in its field.
What is Kubernetes Architecture?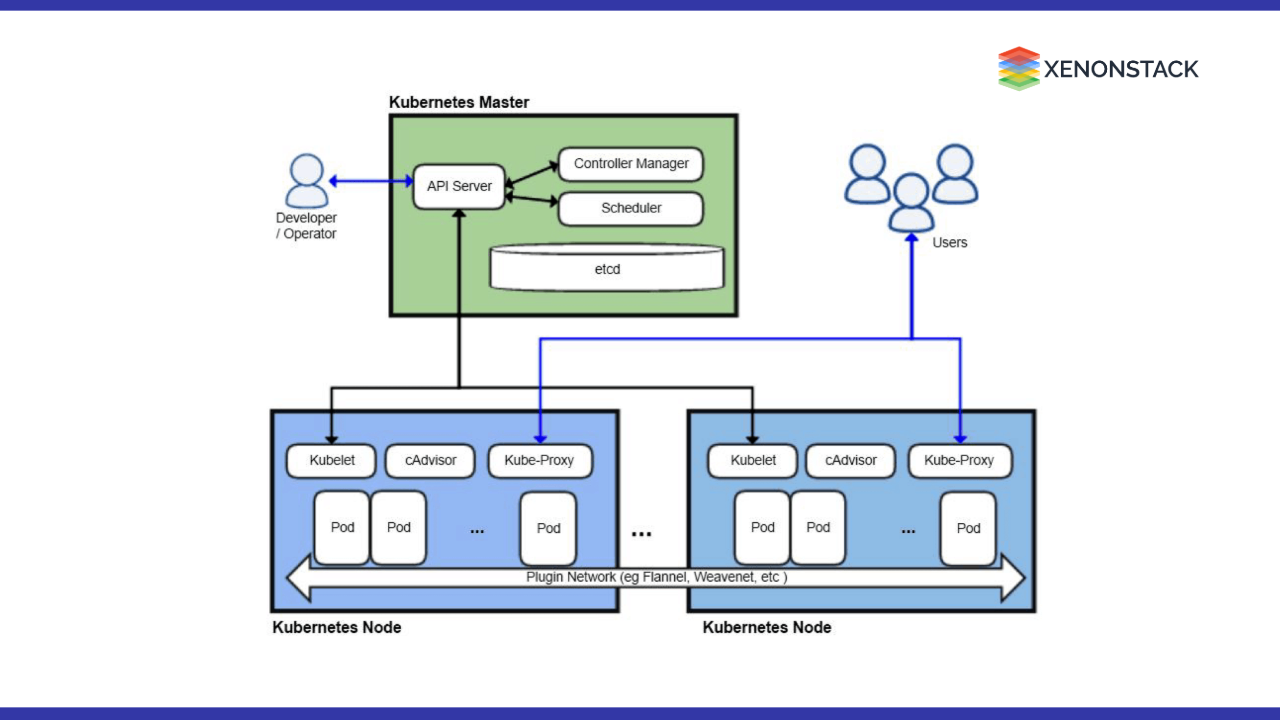
Kubernetes features a flexible architecture that facilitates service discovery within a cluster while maintaining loose coupling. A Kubernetes cluster consists of a set of control planes and computing nodes. The primary function of the control plane is to manage the entire cluster, provide access to the API, and handle the scheduling of compute nodes based on the desired configurations. The compute nodes execute container runtimes like Docker and include a communication agent known as kubelet, which interacts with the control plane. These nodes can be comprised of physical servers or virtual machines (VMs) in either on-premises or cloud settings.
Kubernetes Architecture Diagram:
-
The Kubernetes architecture diagram above illustrates one master node and multiple worker nodes.
-
The master node communicates with the worker nodes through the Kube API server, facilitating the interaction with kubelet.
-
Each worker node can host one or more pods, which may contain one or multiple containers.
-
Containers can be deployed using an image or can also be deployed externally by the user.
Core Components of Kubernetes Architecture
Kubernetes is a robust open-source platform designed to automate the deployment, scaling, and management of containerized applications. Its architecture operates on a client-server model and consists of a control plane and worker nodes (data plane), both of which play essential roles in managing the application lifecycle within a cluster.
Core Components
A Kubernetes cluster comprises several key components that collaborate to orchestrate and manage applications effectively:
1. Control Plane Components
The control plane is tasked with overseeing the overall state of the cluster. Its key components include:
-
kube-apiserver: This central component exposes the Kubernetes API and serves as the access point for all communications within the cluster. It validates and processes API requests from clients, such as kubectl.
-
etcd: A distributed key-value store that maintains all cluster data, including configuration settings and state information. It functions as the "brain" of the cluster, ensuring consistency and availability.
-
kube-scheduler: Responsible for assigning pods to worker nodes based on resource availability and scheduling policies, this component helps to optimize the utilization of cluster resources.
-
kube-controller-manager: Manages various controllers that maintain the desired state of the cluster, ensuring that the specified number of pod replicas are running.
-
cloud-controller-manager (optional): This component integrates with cloud providers to manage cloud-specific resources like load balancers and storage volumes.
2. Node Components
Each worker node runs a set of components that are crucial for executing applications:
-
kubelet: An agent that communicates with the control plane to ensure that containers are running according to the pod definitions. It monitors the health of these containers and reports back to the control plane.
-
kube-proxy: Manages network rules on each node, enabling communication between services and pods by routing requests to the appropriate containers.
-
Container Runtime: This is the software responsible for running containers on each node. Common container runtimes include Docker and containerd.
3. Addons
Kubernetes supports various addons that enhance its functionality:
-
CoreDNS: Provides DNS services to facilitate service discovery within the cluster.
-
Dashboard: A web-based user interface that allows for visual management of cluster resources.
-
Monitoring Tools: Such as Prometheus, which collect metrics, and logging solutions that enable centralized log management.
What are the basic concepts of Kubernetes?
The below mentioned are the basics kubernetes concepts :
Nodes
Its Nodes are the worker nodes in the cluster. Its worker node can be a virtual machine or bare metal server. Node has all the required services to run any kind of pods. Node is also managed by the master node of the cluster. Following are the few services of Nodes
- Docker
- Kubelet
- Kube-Proxy
- Fluentd
Docker Containers
A container is a standalone, executable package of a piece of software that includes everything like code, run time, libraries, configuration.
-
Supports both Linux and Windows-based apps
-
Independent of the underlying infrastructure.
Docker and CoreOS are the main leaders in containers race.
Pods
Pods are the smallest unit of its architecture. It can have more than 1 containers in a single pod. A pod is modelled as a group of Docker containers with shared namespaces and shared volumes.
Example:- pod.yml
Kubernetes Deployment
A Deployment is JSON or YAML file in which we declare Pods and Replica Set definitions. We just need to describe the desired state in a Deployment object, and the Deployment controller will change the actual state to the desired state at a controlled rate for you. We can
- Create new resources
- Update existing resources
Example:- deployment.yml
Managed Kubernetes Service YAML/JSON
A Kubernetes Service definition is also defined in YAML or JSON format. It creates a logical set of pods and creates policies for each set of pods that what type of ports and what type of IP address will be assigned. The Service identifies set of target Pods by using Label Selector.
Example: - service.yml
Replication Controller
A Replication Controller is a controller who ensures that a specified number of pod “replicas” should be in running state.
- Pods should be running
- Pods should be in desired replica count.
- Manage pods on all worker nodes of the Managed Kubernetes cluster.
Example :- rc.yml
Labels
Labels are key/value pairs. It can be added any kubernetes objects, such as pods, service, deployments. Labels are very simple to use in the configuration file. Below mentioned code snippet of labels Because labels provide meaningful and relevant information to operations as well as developers teams. Labels are very helpful when we want to roll update/restore application in a specific environment only. Labels can work as filter values for its objects. Labels can be attached to kubernetes objects at any time and can also be modified at any time. Non-identifying information should be recorded using annotations.
Container Registry
Container Registry is a private or public online storage that stores all container images and let us distribute them.There are so many container registries in the market.
Microservices Application
Kubernetes is a collection of APIs which interacts with computer, network and storage. There are so many ways to interact with the Managed Kubernetes cluster.
- API
- Dashboard
- CLI
Direct Kubernetes API is available to do all tasks on the cluster from deployment to maintenance of anything inside the cluster. Kubernetes Dashboard is simple and intuitive for daily tasks. We can also manage our cluster from the dashboard.
Kubernetes CLI is also known as kubectl. It is written in GoLang. It is the most used tool to interact with either local or remote kubernetes cluster.
Continuous Delivery for Application
Below below-mentioned deployment guides can be used to most of the popular language application on kubernetes.
- Continuous Delivery for Python Application on Kubernetes
- Continuous Delivery for NodeJS on Kubernetes
- Continuous Delivery for GoLang on Kubernetes
- Continuous Delivery for Java Applciation on Kubernetes
- Continuous Delivery for Scala Application on Kubernetes
- Continuous Delivery for ReactJS on Kubernetes
- Continuous Delivery for Kotlin on Kubernetes
- Continuous Delivery for .Net on Kubernetes
- Continuous Delivery for Ruby on Rails on Kubernetes

What are the types of Kubernetes Architecture?
Managed Kubernetes Cluster operates in master and worker architecture. In which its master gets all management tasks and dispatch to appropriate Kubernetes worker node based on given constraints.
- Master Node
- Worker Node
Below we have created two sections so that you can understand better what are the components of its architecture and where we exactly using them.
1. Master Node Architecture
Kube API Server
Kubernetes API server is the center of each and every point of contact to its cluster. From authentication, authorization, and other operations to its cluster. API Server store all information in the etc database which is a distributed data store.
Setting up Etcd Cluster
Etcd is a database that stores data in the form of key-values. It also supports Distributed Architecture and High availability with a strong consistency model. Etcd is developed by CoreOS and written in GoLang. Its components stores all kind of information in etcd like metrics, configurations and other metadata about pods, service, and deployment of the kubernetes cluster.
kube-controller-manager
The kube-controller-manager is a component of Kubernetes Cluster which manages replication and scaling of pods. It always tries to make its system in the desired state by using its API server. There are other controllers also in kubernetes system like
-
Replication controller
-
Endpoints controller
-
Namespace controller
-
Service accounts controller
-
DaemonSet Controller
-
Job Controller
kube-scheduler
The kube-scheduler is another main component of Kubernetes architecture. The Kube Scheduler check availability, performance, and capacity of its worker nodes and make plans for creating/destroying of new pods within the cluster so that cluster remains stable from all aspects like performance, capacity, and availability for new pods. It analyses cluster and reports back to API Server to store all metrics related to cluster resource utilisation, availability, and performance. It also schedules pods to specified nodes according to submitted manifest for the pod.
2. Worker Node Architecture
kubelet
The Kubernetes kubelet is a worker node component of its architecture responsible for node level pod management. API server put HTTP requests on kubelet API to executes pods definition from the manifest file on worker nodes and also make sure containers are running and healthy. Kubelet talks directly with container runtimes like docker or RKT.
kube-proxy
The kube-proxy is networking component of the its Architecture. It runs on each and every node of the Kubernetes Cluster.
- It handles DNS entry for service and pods.
- It provides the hostname, IP address to pods.
- It also forwards traffic from Cluster/Service IP address to specified set of pods.
- Alter IPtables on all nodes so that different pods can talk to each other or outside world.
Docker
Docker is an open source container run time developed by docker. To Build, Run, and Share containerized applications. Docker is focused on running a single application in one container and container as an atomic unit of the building block.
- Lightweight
- Open-Source
- Most Popular
rkt, a security-minded, standards-based container engine - CoreOS
rkt is another container runtime for the containerized application. Rocket is developed by CoreOS and have more focus towards security and follow open standards for building Rocket runtime.
- Open-Source
- Pod-native approach
- Pluggable execution environment
Managed Kubernetes Supervisor
Its supervisor is a lightweight process management system that runs kubelet and container engine in running state.
Logging with Fluentd
Fluentd is an open-source data collector for Kubernetes cluster logs.
Spinnaker is a multi-cloud continuous delivery platform that automates the deployment of software changes. It enables organizations to manage application deployments, provides centralized control and visibility through a dashboard, and enforces enterprise policies. Implementing Spinnaker with Kubernetes for Continuous Delivery
Enterprise Solutions & Production Grade Cluster
Below is the defined Enterprise Solutions & Production Grade Cluster:
Workloads API GA in Kubernetes 1.9
Kubernetes 1.9 introduced General Availability (GA) of the apps/v1 Workloads API, which is now enabled by default. The Apps Workloads API groups the DaemonSet, Deployment, ReplicaSet, and StatefulSet APIs together to form the foundation for long-running stateless and stateful workloads in it. Deployment and ReplicaSet, two of the most commonly used objects in it, are now stabilized after more than a year of real-world use and feedback.
Windows Support (Beta) For Kubernetes 1.9
Kubernetes 1.9 introduces SIG-Windows, Support for running Windows workloads.
Storage Enhancements in Kubernetes 1.9
Kubernetes 1.9 introduces an alpha implementation of the Container Storage Interface (CSI), which will make installing new volume plugins as easy as deploying a pod, and enable third-party storage providers to develop their solutions without the need to add to the core codebase.
Kubernetes Approach: Simplifying the Containers Management
Kubernetes is an open-source container for managing full stack operations and containers. Discover how XenonStack's Managed Kubernetes Consulting Solutions For Enterprises and Startups can help them for Migrating to Cloud-Native Application Architectures means re-platforming, re-hosting, recoding, rearchitecting, re-engineering, interoperability, of the legacy Software application for current business needs.
Application Modernization services enable the migration of monolithic applications to new Microservices architecture. Deploy, Manager and Monitor your Big Data Stack Infrastructure on it. Run large scale multi-tenant Hadoop Clusters and Spark Jobs on it with proper Resource utilization and Security.



























