
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
PostgreSQL is a powerful, open-source Relational Database Management System. Any organization or any individual does not control PostgreSQL. Its source code is available free of charge. PostgreSQL has earned a strong reputation for its reliability, data integrity, and correctness.
-
Runs on all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, macOS, Solaris, Tru64), and Windows.
-
Being Fully ACID compliant, it has full support for foreign keys, joins, views, triggers, and stored procedures (in multiple languages).
-
Includes most SQL:2008 data types, including INTEGER, NUMERIC, BOOLEAN, CHAR, VARCHAR, DATE, INTERVAL, and TIMESTAMP.
-
Supports the storage of binary large objects, including pictures, sounds, or video.
-
It has native programming interfaces for C/C++, Java, .Net, Perl, Python, Ruby, Tcl, ODBC, among others, and exceptional documentation.
This article gives an overview of How PostgreSQL Deployment works on Kubernetes with Blue Green Strategy. Let's understand what is Blue-Green Deployment Strategy first.
Blue-Green Deployment Database
Blue-Green Deployment Strategy is a special strategy that reduces the risk and minimizes downtime. It uses two production environments, Blue and Green. Only one of these environments is alive at the moment, and deployment is done on the inactive one. For example, if Green is a live environment, deployment to the Blue (inactive) environment occurs, and a switchover occurs after verification, which renders the Blue environment as the live environment and the Green environment inactive. Let's go ahead to know how we make use of this strategy in deploying PostgreSQL on Kubernetes.How use PostgreSQL on Kubernetes?
Following are the Prerequisites for PostgreSQL Deployment on Kubernetes.
- Kubernetes Cluster
- GlusterFS Cluster
Step 1 - Create a PostgreSQL Container Image with Docker
Create a file name “Dockerfile” for PostgreSQL. This image contains our custom config dockerfile, which will look like this:FROM ubuntu: latest
MAINTAINER XenonStack
RUN apt - key adv--keyserver hkp: //p80.pool.sks-keyservers.net:80 --recv-keys B97B0AFCAA1A47F044F244A07FCC7D46ACCC4CF8
RUN echo "deb http://apt.postgresql.org/pub/repos/apt/ xenial-pgdg main" > /etc/apt / sources.list.d / pgdg.list
RUN apt - get update && apt - get install - y python - software - properties software - properties - common postgresql - 9.6 postgresql - client - 9.6 postgresql - contrib - 9.6
RUN / etc / init.d / postgresql start && \
psql--command "CREATE USER root WITH SUPERUSER PASSWORD 'xenonstack';" && \
createdb - O root xenonstack
RUN echo "host all all 0.0.0.0/0 md5" >> /etc/postgresql / 9.6 / main / pg_hba.conf
RUN echo "listen_addresses='*'" >> /etc/postgresql / 9.6 / main / postgresql.conf
# Expose the PostgreSQL port
EXPOSE 5432
# Add VOLUMEs to allow backup of databases
VOLUME["/var/lib/postgresql"]
# Set the
default command to run when starting the container
CMD["/usr/lib/postgresql/9.6/bin/postgres", "-D", "/var/lib/postgresql", "-c", "config_file=/etc/postgresql/9.6/main/postgresql.conf"]
Step 2 - Build PostgreSQL Docker Image
$ docker build - t dr.xenonstack.com: 5050 / postgres: v9 .6
Step 3 - Create a Storage Volume (Using GlusterFS)
Using the below-mentioned command creates a volume in GlusterFS for PostgreSQL and start it. As we don’t want to lose our PostgreSQL Database data just because a Gluster server dies in the cluster, so we put replica 2 or more for higher availability of data.$ gluster volume create postgres - disk replica 2 transport tcp k8 - master: /mnt/brick
1 / postgres - disk k8 - 1: /mnt/brick
1 / postgres - disk
$ gluster volume start postgres - disk
$ gluster volume info postgres - disk
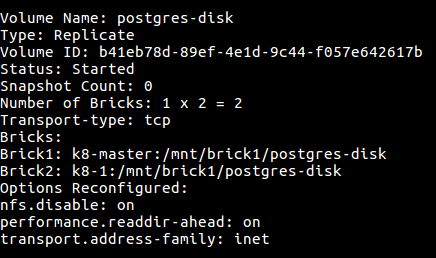
Step 4 - Deploy PostgreSQL with Docker on Kubernetes
Deploying PostgreSQL on Kubernetes has the following prerequisites:- Docker Image: We have created a Docker Image for Postgres in Step 2
- Persistent Shared Storage Volume: We have created a Persistent Shared Storage Volume in Step 3
- Deployment & Service Files: Next, we will create Deployment & Service Files
apiVersion: extensions / v1beta1
kind: Deployment
metadata:
name: postgres
namespace: production
spec:
replicas: 1
template:
metadata:
labels:
k8s - app: postgres
spec:
containers:
-name: postgres
image: dr.xenonstack.com: 5050 / postgres: v9 .6
imagePullPolicy: "IfNotPresent"
ports:
-containerPort: 5432
env:
-name: POSTGRES_USER
value: postgres - name: POSTGRES_PASSWORD
value: superpostgres - name: PGDATA
value: /var/lib / postgresql / data / pgdata
volumeMounts:
-mountPath: /var/lib / postgresql / data
name: postgredb
volumes:
-name: postgredb
glusterfs:
endpoints: glusterfs - cluster
path: postgres - disk
readOnly: false
apiVersion: v1
kind: Service
metadata:
labels:
k8s - app: postgres
name: postgres
namespace: production
spec:
type: NodePort
ports:
-port: 5432
selector:
k8s - app: postgres$ kubectl create - f deployment.yml
$ kubectl create - f service.yml
You have now successfully Deployed PostgreSQL on Kubernetes.
Summarizing PostgreSQL Deployment
PostgreSQL on Kubernetes helped to utilize resources even better than virtual machines and provide isolation from other apps deployed on the same machine.Interested in reading about Deploying Kotlin Application on Docker and Kubernetes?
At XenonStack, we have specialized professionals who can help you start with Microservices Architecture, NoSQL, and SQL Database like PostgreSQL On Docker & Kubernetes. Reach Us for Development, Deployment, and Consulting for MicroServices, Kubernetes, and Docker Technology Solutions.
What's Next?
- Read about Kubernetes Architecture and its Components | A Quick Guide
- Get in Touch with us for Kubernetes Consulting Services and Solutions
- Explore further Kubernetes Deployment
- Know more about Kubernetes security best practices




























