
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is On-Prem Agentic AI Infrastracutre ?
On-Prem Agentic AI Infrastructure refers to deploying intelligent, autonomous AI agents within an organization’s local data centers or private cloud, rather than relying on public cloud platforms. This setup allows companies to maintain full control over their data, ensure compliance with regulatory standards, and reduce latency for time-sensitive operations.
Agentic AI in this context involves AI agents capable of performing complex tasks, making decisions, and continuously learning within enterprise environments. These agents are supported by robust on-prem infrastructure, including GPUs, high-performance computing clusters, local storage, and AI frameworks like TensorFlow or PyTorch.
Example: A manufacturing company uses on-prem Agentic AI to monitor factory equipment in real-time. Autonomous agents analyze sensor data locally, predict equipment failures, and trigger maintenance workflows—all without sending sensitive data to the cloud. This ensures data privacy, fast response times, and seamless integration with existing operational systems.
Why On-Prem Agentic AI Infrastructure Now?
As AI evolves into more intelligent, autonomous systems, enterprises are shifting focus toward agentic AI—self-governing, reasoning-based agents capable of decision-making and collaboration. Enabling these agents securely and reliably demands an infrastructure shift from traditional cloud deployments to on-premises architectures.
For organizations in highly regulated sectors, where data privacy, governance, and system control are paramount, on-prem agentic AI infrastructure is not just a technical upgrade—it’s a strategic imperative.
Understanding Agentic AI and Its Demands
Agentic AI goes beyond static models. These systems involve multiple agents that can:
-
Understand context
-
Communicate and collaborate
-
Make real-time decisions
-
Adapt dynamically to evolving scenarios
To support such capabilities, enterprises need infrastructure that is scalable, secure, interoperable, and controllable capabilities that public cloud often can’t deliver in isolation.
What Makes an AI Infrastructure “Agentic”?
An agentic AI infrastructure is purpose-built to support the full lifecycle of intelligent agents—from training and deployment to collaboration and continual learning. The core components typically include:
 Fig 1: Building a Robust And Secure Agentic AI Infrastructure
Fig 1: Building a Robust And Secure Agentic AI Infrastructure
-
ModelOps + AgentOps: Managing both traditional models and intelligent agents across lifecycles
-
Secure Compute Environments: Isolated, GPU-optimized environments with strong access control
-
Unified Data Pipelines: Real-time and batch pipelines that deliver contextual data to agents
-
Policy-Based Governance: Compliance, lineage, auditability, and control at scale
-
Observability: Real-time health checks, behavioural logs, and performance metrics of agents

Benefits of On-Prem Deployment for Agentic Systems
Deploying agentic systems on-premises unlocks several enterprise-grade advantages:
-
Enhanced Privacy and Compliance
Keep sensitive data within organizational boundaries and comply with industry-specific regulations (e.g., HIPAA, GDPR, FISMA).
-
Total Operational Control
Full visibility and control over model behavior, updates, and agent actions.
-
Custom Optimization
Tailor infrastructure to specific workloads—whether real-time AI, vision systems, or high-volume batch processing. -
Reduced Latency and Network Risk
Ideal for edge scenarios or mission-critical processes where real-time responses are essential.
Core Capabilities for Enabling On-Prem Agentic AI
To support enterprise-grade agentic AI, the following capabilities must be in place:
- Composable Infrastructure: Modern workloads require modular, containerized environments. Kubernetes is the backbone here—providing orchestration, scaling, and resilience.
Data Fabric and Intelligent ETL: Data must flow securely and intelligently between systems. Pipelines need to handle batch, real-time, and event-based processing—ensuring agents are fed the right context, at the right time.
Model and Agent Lifecycle Management: It’s not just about deploying a model. Agentic systems require constant monitoring, updates, and behavior tracking. Frameworks like ModelOps and AgentOps are essential for this purpose.
AI Security and Trust: AI supply chains must be protected—model provenance, adversarial testing, and runtime access control are vital. Governance must span from code to inference.
DevSecOps for AI: Version control, rollback, integration testing, and sandboxing should be standard for deploying agents and models alike.
Enabling On-Prem Agentic AI Infrastructure
To enable On-Prem Agentic AI Infrastructure successfully, an organization needs to implement a well-structured, flexible, and scalable architecture that ensures seamless integration between multiple AI models, autonomous agents, and real-time decision-making processes. This involves a combination of AI models, data pipelines, security measures, and Model Context Protocol (MCP) for context management.
Steps to Enable On-Prem Agentic AI Infrastructure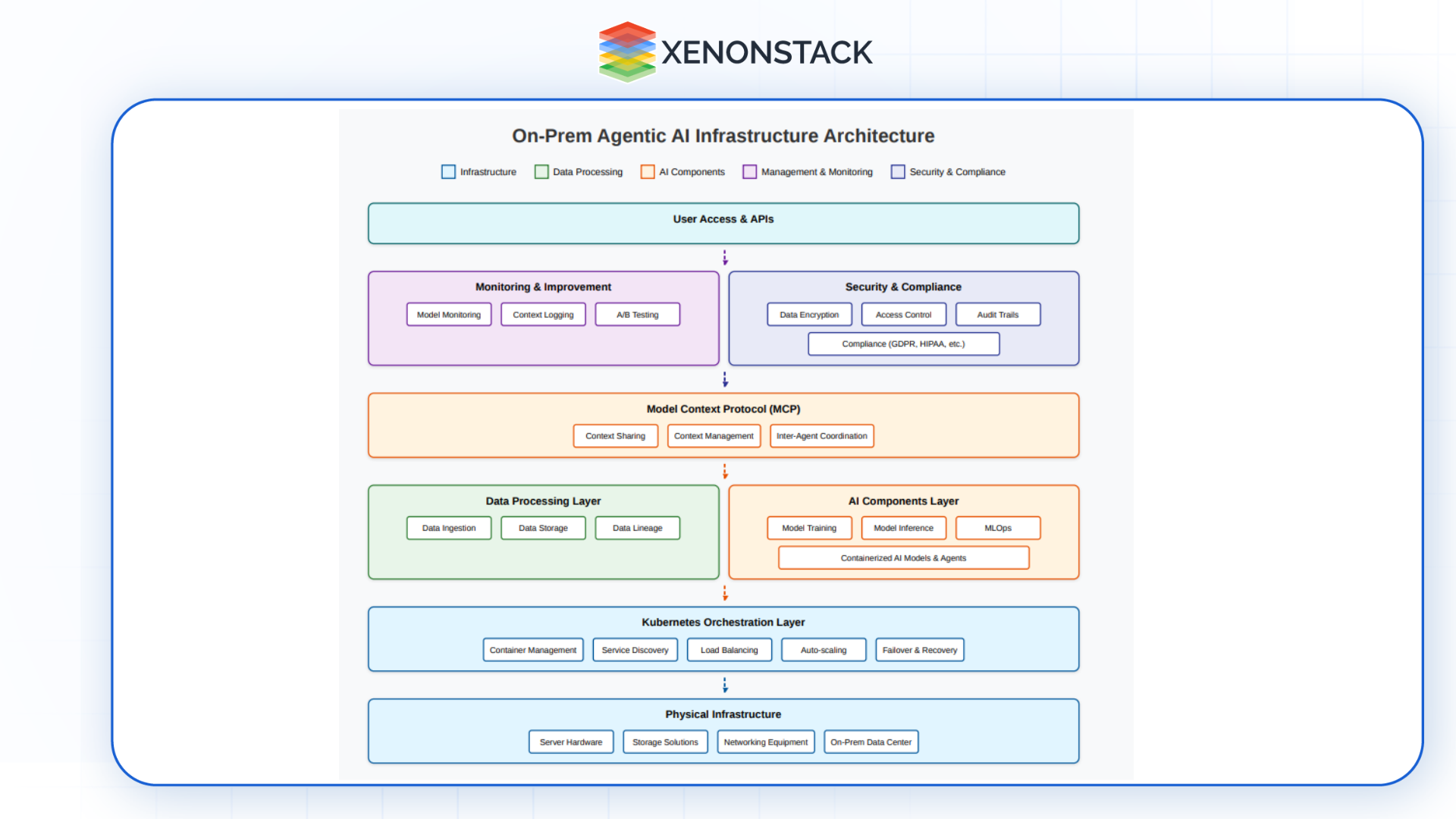
Fig 2: Steps to Enable On-Prem Agentic AI Infrastructure
1. Assess Requirements and Define Goals
Start by defining the goals and understanding the requirements of your AI system:
-
Business needs: What are the specific problems you're solving with AI agents (e.g., customer service automation, process optimization)?
-
Computational power: What is the scale of the AI workload, and what kind of processing power is required for your models?
-
Data requirements: What type and amount of data will your system be processing (e.g., structured, unstructured, real-time)?
-
Security: Ensure compliance with relevant regulations (e.g., GDPR, HIPAA) for sensitive data handling.
2. Infrastructure Setup
This stage involves establishing the foundational infrastructure required to support the agentic AI environment:
-
Select Hardware: Choose appropriate on-premises servers, storage solutions, and networking equipment that provide sufficient computing power and storage capacity.
-
Establish Networking: Configure the network architecture, ensuring secure communication between the various components (AI models, agents, and users) while maintaining performance.
-
Kubernetes Setup: Deploy Kubernetes for container orchestration. Kubernetes will manage the scalability, deployment, and reliability of your AI models, ensuring optimal performance and flexibility.
3. Integrate MCP (Model Context Protocol)
Incorporating MCP is essential for ensuring that your AI models and autonomous agents work in a context-aware environment:
-
Context Sharing: MCP facilitates communication between models and agents by passing relevant context (e.g., user preferences, environmental data, historical information) at runtime. This ensures that each agent can act in alignment with the shared understanding of the system state.
-
Model Context Management: Context-aware decision-making is critical for complex AI systems. MCP provides a unified protocol for managing and sharing model contexts across agents, allowing them to adjust their decisions dynamically.
-
Inter-Agent Coordination: Multiple autonomous agents interacting with each other can use MCP to maintain a consistent environment. For instance, one agent's decision might depend on another agent's current state, and MCP ensures this information is transmitted in real time.
4. Design and Deploy AI Models
-
Model Training: Train your AI models using historical and real-time data. These models should be designed to handle tasks like natural language processing, anomaly detection, or decision optimization based on the specific use case.
-
Model Inference: Post-training, deploy models for real-time inference, where they make predictions or take actions. Use MCP to ensure that the context of the real-time data is passed to the models during inference, optimizing decision-making.
-
Model Lifecycle Management: Implement MLOps (Machine Learning Operations) and ModelOps to streamline the deployment, monitoring, and continuous improvement of your models. This includes regular updates, retraining, and rollback mechanisms.
5. Create and Manage Data Pipelines
Data is the lifeblood of agentic AI systems. You need robust, real-time data pipelines to process incoming data and provide it to your models:
-
Data Ingestion: Set up a robust data ingestion system that pulls data from various sources (IoT devices, user interactions, external APIs) and preprocesses it for analysis. Use tools like ETL (Extract, Transform, Load) for seamless data movement.
-
Data Storage: Use secure on-premise data storage solutions, ensuring that data is stored efficiently and can be accessed quickly by the models. Data security protocols should be in place to protect sensitive information.
-
Data Lineage: Implement data lineage services to track the flow of data through the system, which is crucial for compliance and transparency, especially in regulated industries.

6. AI Model and Agent Deployment
- Containerization: Package your AI models and agents as containers (e.g., using Docker) to ensure consistency and ease of deployment across various environments.
- Deployment with Kubernetes: Use Kubernetes for container orchestration. This allows you to scale models and agents dynamically and manage their deployment lifecycle effectively.
- Model Context: Integrate MCP into your deployment pipeline, ensuring that the context for each model and agent is preserved and communicated effectively during the inference and decision-making phases.
7. Real-Time Monitoring and Continuous Feedback
Once your agentic AI system is deployed, it’s essential to have continuous monitoring and feedback loops:
- Model Performance Monitoring: Continuously track the performance of models and agents. Use logging and alerting mechanisms to notify administrators about any issues.
- Context Logging: Ensure that MCP is actively tracking changes in the context throughout the agent's decision-making process. This helps in understanding the reasoning behind agent actions and improves transparency.
- Resiliency & Failover: Implement failover and recovery mechanisms to ensure high availability and system resiliency. Use Kubernetes to manage these processes automatically.
8. Continuous Improvement
- Model Retraining: Based on the feedback and performance data, periodically retrain your models to improve their accuracy. The MCP protocol can help ensure that newly trained models maintain contextual awareness.
- A/B Testing: Conduct A/B testing for different models and agents to ensure that they are performing optimally.
- Update Models: As your business environment evolves, update the models to handle new challenges or adapt to changing data inputs.
9. Security and Compliance Measures
Since your agentic AI system is on-premises, security is paramount:
- Data Encryption: Encrypt all sensitive data at rest and in transit to protect against unauthorized access.
- Access Control: Use role-based access controls (RBAC) to restrict access to sensitive data and models.
- Audit Trails: Implement an audit trail for every action taken by agents and models. This ensures accountability and helps with troubleshooting and regulatory compliance.
10. Final Deployment and Ongoing Support
- User Access: Once the AI infrastructure is live, ensure that all users and stakeholders can access the system securely through APIs and dashboards.
- Support Framework: Establish an ongoing support and maintenance framework to ensure smooth operations. This includes regular updates, patches, and system optimizations.
Glimpses of Enabling Platforms: NexaStack and Akira AI
Solutions like NexaStack, a unified inference platform, and Akira AI, a unified agentic AI platform, illustrate how modern infrastructure stacks are evolving to support on-prem intelligence.
-
NexaStack integrates Kubernetes-native management with AI observability and performance optimization for inference at scale.
-
Akira AI helps orchestrate multiple AI agents across tasks, workflows, and domains—enabling distributed intelligence in secure environments.
While not the only options, these platforms reflect modern enterprises' direction: composable, interoperable, and secure AI ecosystems.
Resilience and Scalability at the Edge
1. On-Prem ≠ Limitation
-
Deploying Agentic AI on-premises doesn’t restrict scalability.
-
Modern infrastructure strategies enable distributed, powerful deployments—even outside cloud environments.
-
Edge sites (like smart factories, remote facilities, and R&D labs) can be brought into the AI ecosystem.
2. Scalability Across Distributed Environments
-
Agentic AI workloads can be extended across:
-
Edge Locations: IoT-rich sites, energy grids, or remote industrial facilities.
-
Factories: For use in predictive maintenance, quality checks, or automation.
-
Private Data Centers: For organizations prioritizing data control, security, and compliance.
-
-
This distribution ensures that intelligence operates closer to the data source, reducing latency and bandwidth costs.
3. Uptime and Resilience as Core Pillars
-
Edge deployments face challenges like unstable connectivity, limited compute, and downtime risks.
-
To counter these, infrastructure should include:
-
Redundant nodes or failover mechanisms.
-
Local fallback agents in case of network failure.
-
Self-healing systems that recover from hardware/software faults.
-
4. Kubernetes Operators & HA Clusters
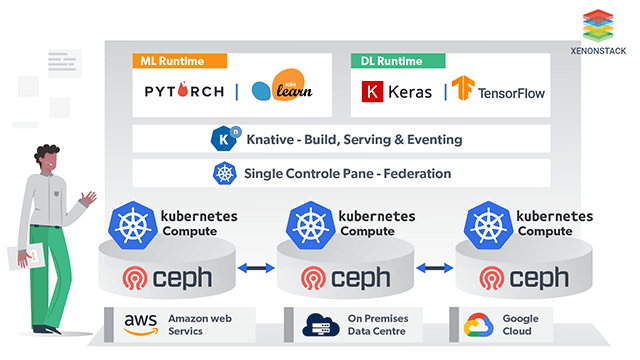
Fig 3: Kubernetes Operators
-
Kubernetes operators are used to automate the deployment, monitoring, scaling, and healing of AI services and agents.
-
High-Availability (HA) clusters spread workloads across nodes:
-
If one fails, others take over without disruption.
-
Load balancing ensures even performance under varying loads.
-
-
Operators also handle edge-specific tasks like updating models or restarting failed pods without manual intervention.
5. Consistent Performance Under Load
-
Agentic systems are often resource-intensive due to:
-
Multiple concurrent agents
-
Real-time decision-making
-
Continuous data ingestion
-
-
Infrastructure should auto-scale based on demand (e.g., spinning up more containers during peak hours).
- Pre-trained models can be cached locally for fast inference, reducing cloud dependencies.
Why It Matters
Mission-critical applications (manufacturing, energy, healthcare) can't afford downtime.
On-prem edge AI needs to mirror cloud-scale capabilities without compromising control or reliability
Final Thoughts on ON-Prem Agentic AI Infrastructure
On-prem agentic AI infrastructure is not just about where AI runs—it’s about how it runs, who controls it, and whether it can adapt securely to enterprise needs. As organizations embrace AI autonomy, the foundation they build today will determine the success of intelligent operations tomorrow.
By integrating modular architecture, secure operations, and continuous governance, enterprises can unlock the next generation of AI—built for trust, performance, and impact.



























