
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Apache Pulsar
Apache Pulsar is a multi-tenant, high-performance server-to-server messaging system. Yahoo developed it. In late 2016, it was the first open-source project. Now, it is incubating under the Apache Software Foundation (ASF).
Pulsar works on the pub-sub pattern, where there is a Producer and a Consumer, also called the subscribers. The topic is the core of the pub-sub model, where producers publish their messages on a given Pulsar topic, and consumers subscribe to a problem to get news from that topic and send an acknowledgement.
Enable real-time decision making, clickstream analytics, fraud detection, Personalised User Experience and recommendations. Explore Our Services, Streaming and Real-Time Analytics solutions
Once a subscription has been acknowledged, the Pulsar will retain all the messages. One Consumer acknowledged that it had been processed only after that message was deleted.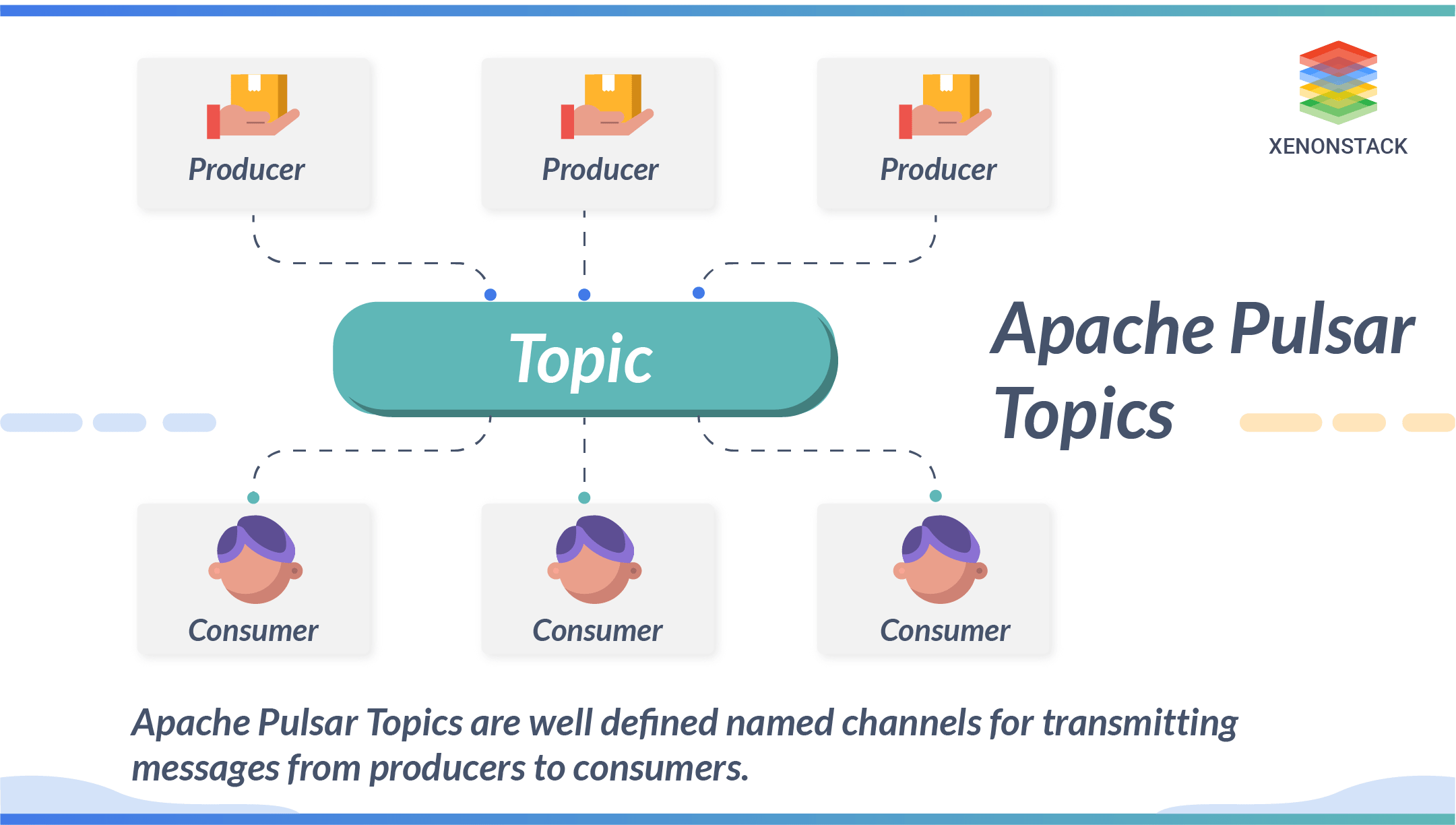 Apache Pulsar Topics are well-defined channels for transmitting messages from producers to consumers. Topic names are well-defined URLs.
Apache Pulsar Topics are well-defined channels for transmitting messages from producers to consumers. Topic names are well-defined URLs.
Namespaces: They are logical nomenclature within a tenant. A tenant can create multiple namespaces via the admin API. A namespace allows the application to create and manage a hierarchy of topics. A number of issues can be created under the namespace.
Apache Pulsar Subscription Modes
A subscription is a named rule for the configuration that determines the delivery of the messages to the consumer. There are three subscription modes in Apache PulsarExclusive
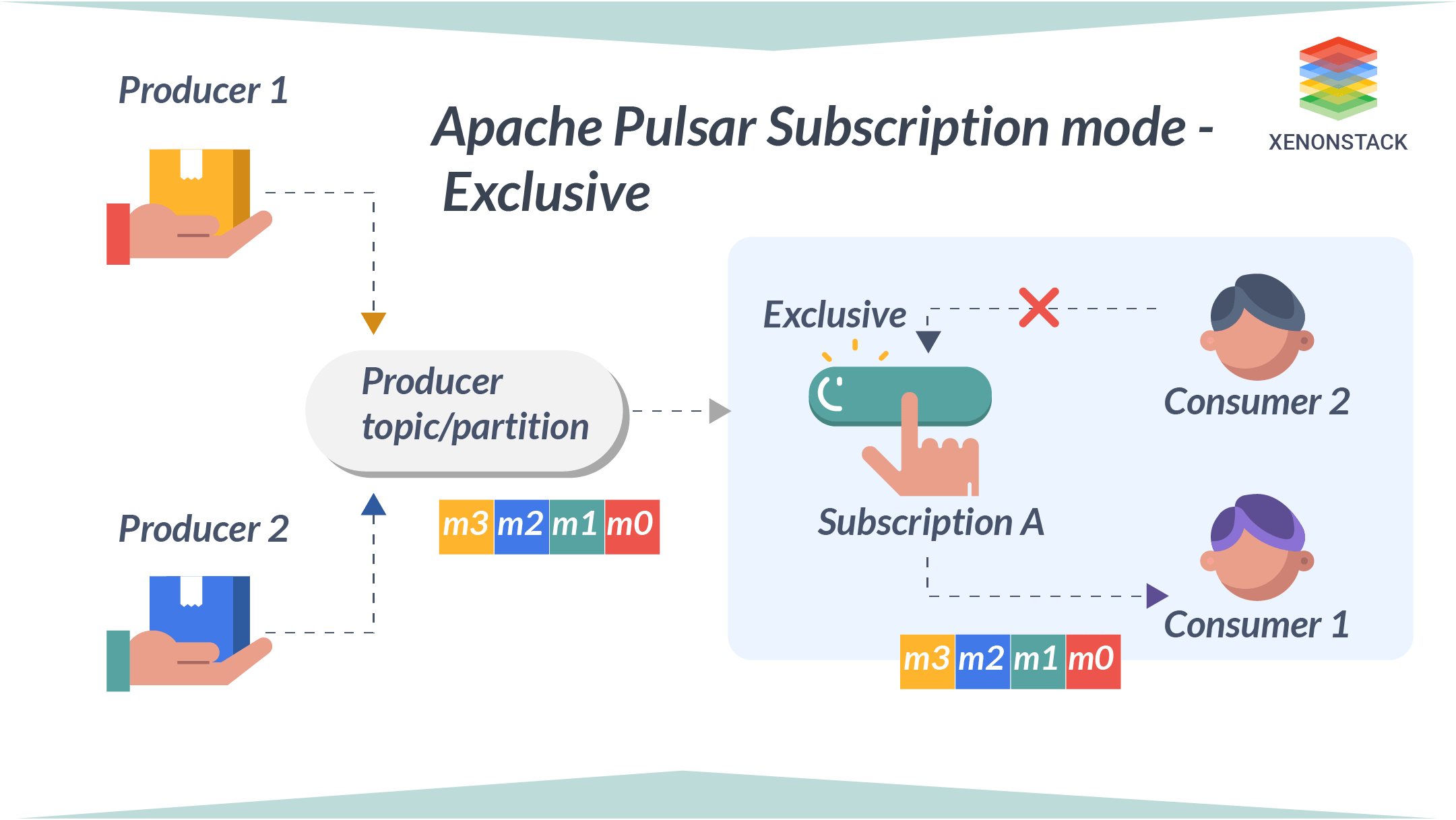
In Exclusive mode, only a single consumer is allowed to attach to the subscription. If more than one consumer attempts to subscribe to a topic using the same subscription, then the consumer receives an error. The exclusive mode is the default subscription model.
Failover
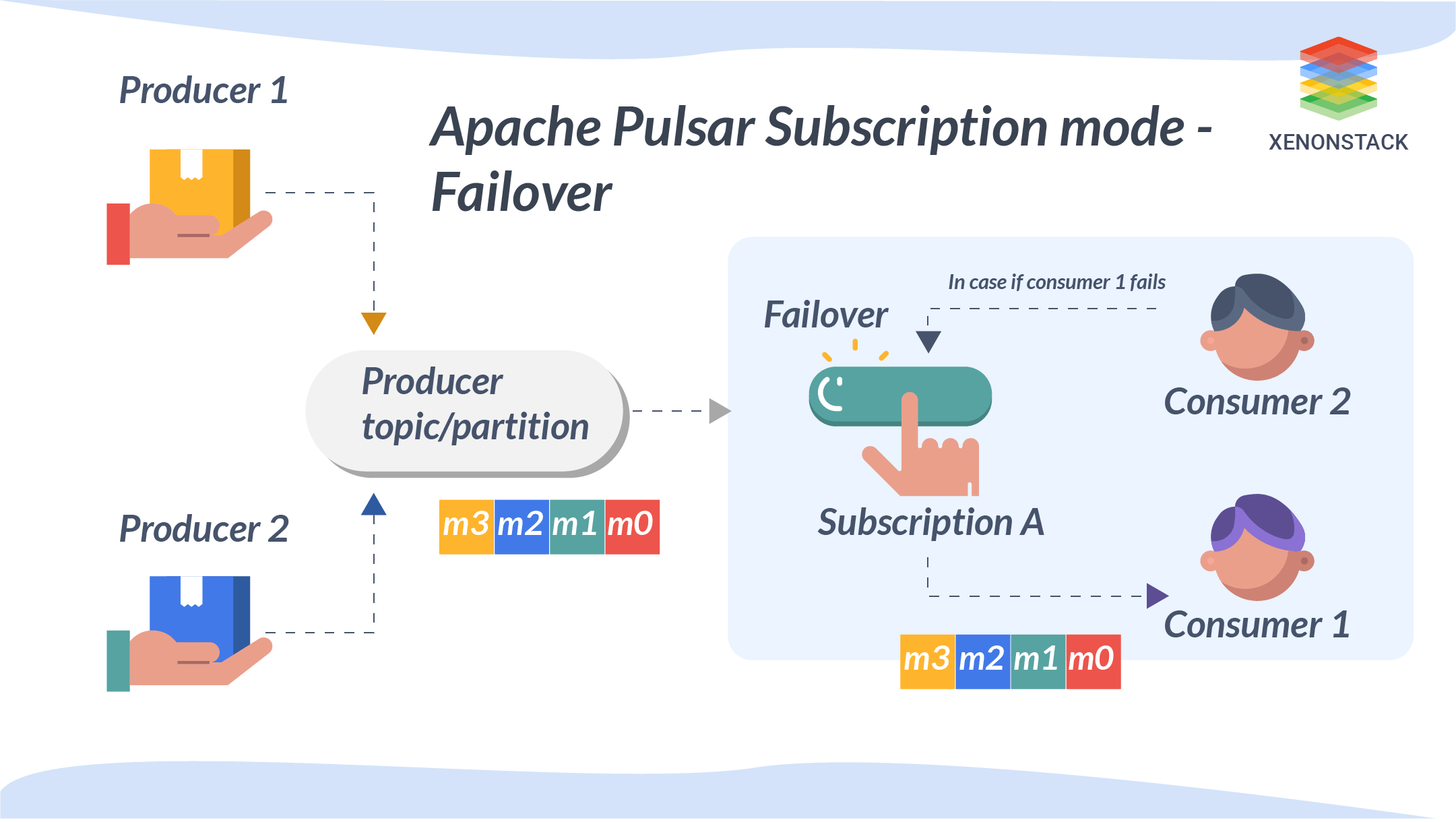
In failover, multiple consumers are attached to the same topic. These consumers are sorted lexically with names, and the first consumer is the master consumer, who gets all the messages. When a master consumer gets disconnected, the next consumers will get the words.
Shared
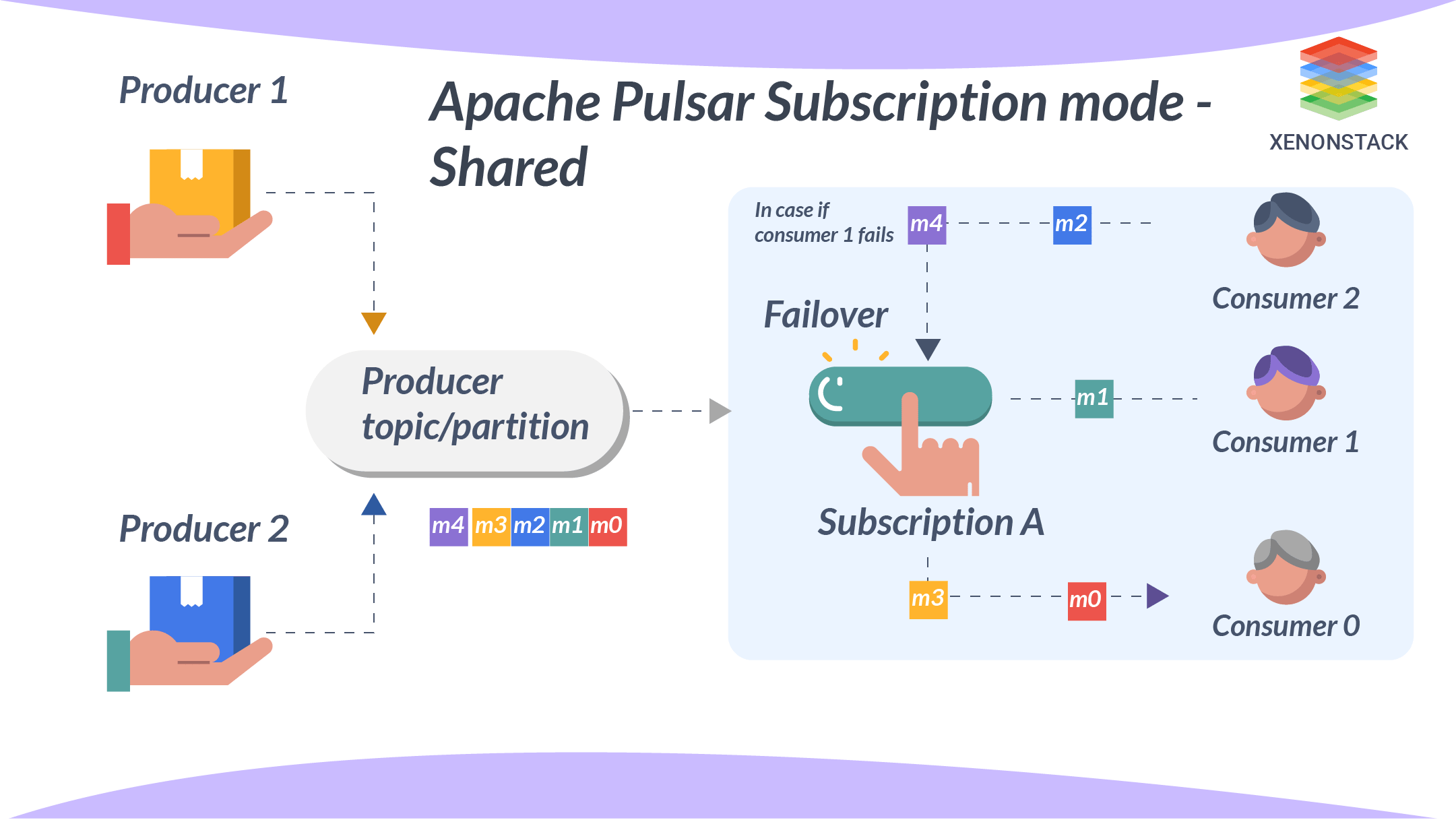 Shared and round-robin mode, in which a message is delivered only to that consumer in a round-robin manner. When that user is disconnected, the messages sent and not acknowledged by that consumer will be re-scheduled to other consumers. Limitations of shared mode-
Shared and round-robin mode, in which a message is delivered only to that consumer in a round-robin manner. When that user is disconnected, the messages sent and not acknowledged by that consumer will be re-scheduled to other consumers. Limitations of shared mode-
- Message ordering is not guaranteed.
- You can’t use cumulative acknowledgement with shared mode.
The process used for analyzing the huge amount of data at the moment it is used or produced. Click to explore about our, Real Time Data Streaming Tools
Routing Modes
The routing modes determine which partition to which topic a message will be subscribed. There are three types of routing methods. Routing is necessary when using partitioned questions to publish.
Round Robin Partition
If no key is provided to the producer, it will publish messages across all the partitions available in a round-robin way to achieve maximum throughput. Round-robin is not done per individual message but set to the same boundary of batching delay, which ensures effective batching. If a key is specified on the message, the partitioned producer will hash the key and assign all the messages to the particular partition. This is the default mode.
Single Partition
If no key is provided, the producer randomly picks a single partition and publishes all the messages in that particular partition. If the key is specified for the message, the partitioned producer will hash the key and assign the letter to the barrier.
Custom Partition
The user can create a custom routing mode using the java client and implementing the MessageRouter interface. Custom routing will be called for a particular partition for a specific message.Apache Pulsar Architecture
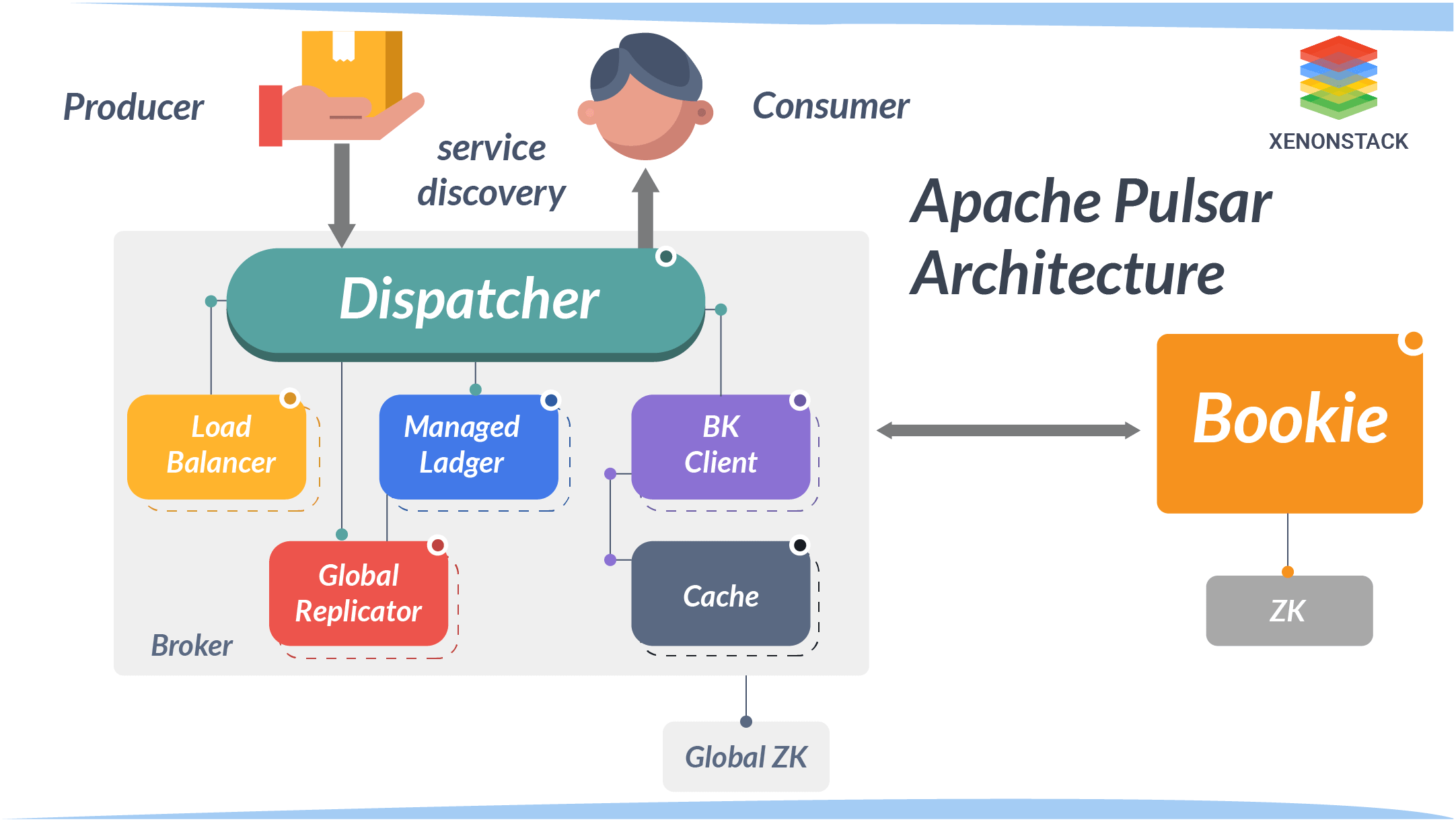 The pulsar cluster consists of different parts: In pulsar, there may be one more broker’s handle. It load balances incoming messages from producers, dispatches messages to consumers, communicates with the pulsar configuration store to handle various coordination tasks, and stores messages in BookKeeper instances.
The pulsar cluster consists of different parts: In pulsar, there may be one more broker’s handle. It load balances incoming messages from producers, dispatches messages to consumers, communicates with the pulsar configuration store to handle various coordination tasks, and stores messages in BookKeeper instances.
-
BookKeeper cluster consisting of one or more bookies to handle persistent storage of messages.
-
ZooKeeper cluster calls the configuration store to handle coordination tasks that involve multiple groups.
Brokers
The broker is a stateless component that handles an HTTP server and the Dispatcher. An HTTP server exposes a Rest API for administrative tasks and topic lookup for producers and consumers. A dispatcher is an async TCP server that uses a custom binary protocol for all data transfers.
Clusters
A Pulsar instance usually consists of one or more Pulsar clusters, one or more brokers, a zookeeper quorum used for cluster-level configuration and coordination, and an ensemble of bookies used for persistent message storage.
Metadata store
Pulsar uses apache zookeeper to store the metadata storage, cluster config and coordination.Persistent storage
Pulsar provides surety of message delivery. If a message reaches a Pulsar broker successfully, it will be delivered to the target that’s intended for it.Pulsar Clients
Pulsar has client API’s with the languages Java, Go, Python and C++. The client API encapsulates and optimizes pulsar’s client-broker communication protocol. It also exposes a simple and intuitive API for use by the applications. The current official Pulsar client libraries support transparent reconnection, and connection failover to brokers, queuing of messages until acknowledged by the broker, and these also consists of heuristics such as connection retries with backoff.Client setup phase
When an application wants to create a producer/consumer, the pulsar client library will initiate a setup phase that is composed of two setups:- The client will attempt to determine the owner of the topic by sending an HTTP lookup request to the broker. The application could reach to an active broker which in return by looking at the cached metadata of zookeeper will let the user know about the serving topic or assign it to the least loaded broker in case nobody is serving it.
- Once the client library has the broker address, it will create a TCP connection (or reuse an existing connection from the pool) and authenticate it. Within this connection, binary commands are exchanged between the broker and the client using the custom protocol. At this point, the client sends a command to create a consumer or producer to the broker, which complies after the user validates the authorization policy.
One of the best features of Apache Spark optimization is it helps with In-memory data computations. Click to explore about our, Apache Spark Optimization Techniques
Geo-Replication
Apache Pulsar’s Geo-replication enables messages to be produced in one geolocation and consumed in another.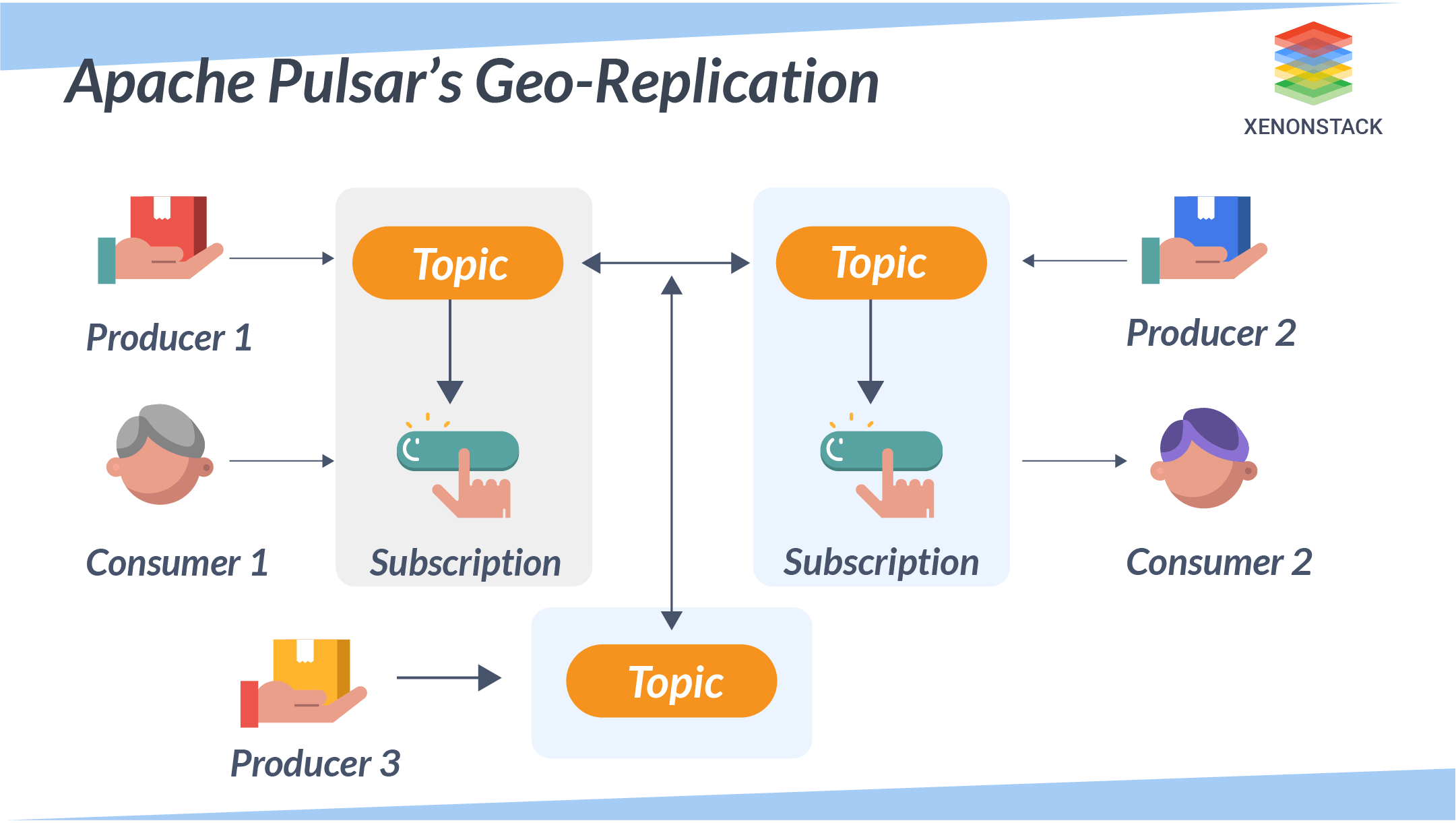
In the above diagram, whenever producers P1, P2, and P3 publish a message on the given topic T1 on Clusters A, B, and C, all those messages are instantly replicated across clusters. Once replicated, this allows consumers C1 & C2 to consume the messages from their respective groups. Without geo-replication, C1 and C2 consumers cannot consume messages published by P3 producers.
Multi-Tenancy
Pulsar was created from the group up as a multi-tenant system. Apache supports multi-tenancy. It is spread across a cluster, and each can have its own authentication and authorization scheme applied. The cluster is also the administrative unit at which storage, message Ttl, and isolation policies can be managed.
Tenants
To each tenant in a particular pulsar instance, you can assign the following:
- An authorization scheme.
- The set of the cluster to which the tenant’s configuration applies.
The Dataset is a data structure in Spark SQL which is strongly typed, Object-oriented and is a map to a relational schema.Click to explore about our, RDD in Apache Spark Advantages
Authentication and Authorization
Pulsar supports the authentication mechanism, which can be configured at the broker, and it also supports authorization to identify the client and its access rights on topics and tenants.Tiered Storage
Pulsar’s architecture allows topic backlogs to grow very large. This creates a rich set of situations over time. To alleviate this cost, use Tiered Storage. The Tiered Storage move older messages in the backlog can be moved from BookKeeper to cheaper storage. Which means clients can access older backlogs.
Schema Registry
Type safety is paramount in communication between the producer and the consumer in it. For safety in messaging, pulsar adopted two basic approaches:Client-side approach
In this approach, message producers and consumers are responsible for serializing and deserializing messages (which consist of raw bytes) and “knowing” which types are being transmitted via which topics.Server-side approach
In this approach, producers and consumers inform the system of which data types can be transmitted via the topic. With this approach, the messaging system enforces type safety and ensures that producers and consumers remain in sync.
How do schemas work?
Pulsar schema is applied and enforced at the topic level. Producers and consumers upload schemas to Pulsar. Pulsar schema consists of :- Name: The name is the topic to which the schema is applied.
- Payload: binary representation of the schema.
- User-defined properties as a string/string map
- JSON
- Protobuf
- Avro
- string (used for UTF-8-encoded lines)
A distributed file system. Store all types of files in the Hadoop file system.Click to explore about our, Data Serialization in Apache Hadoop
What are the Pros and Cons?
The pros and cons of Apache Pulsar are described below:
Pros
-
Feature-rich – persistent/nonpersistent topics
-
Multi-tenancy
-
More flexible client API- including CompletableFutures, fluent interface
-
Java clients have no date for Java docs.
Cons
-
The community base is small.
-
The reader can’t read the last message in the topic [need to skim through all the words]
-
Higher operational complexity – ZooKeeper + Broker nodes + BookKeeper + all clustered.
-
Java client components are thread-safe – the consumer can acknowledge messages from different threads.
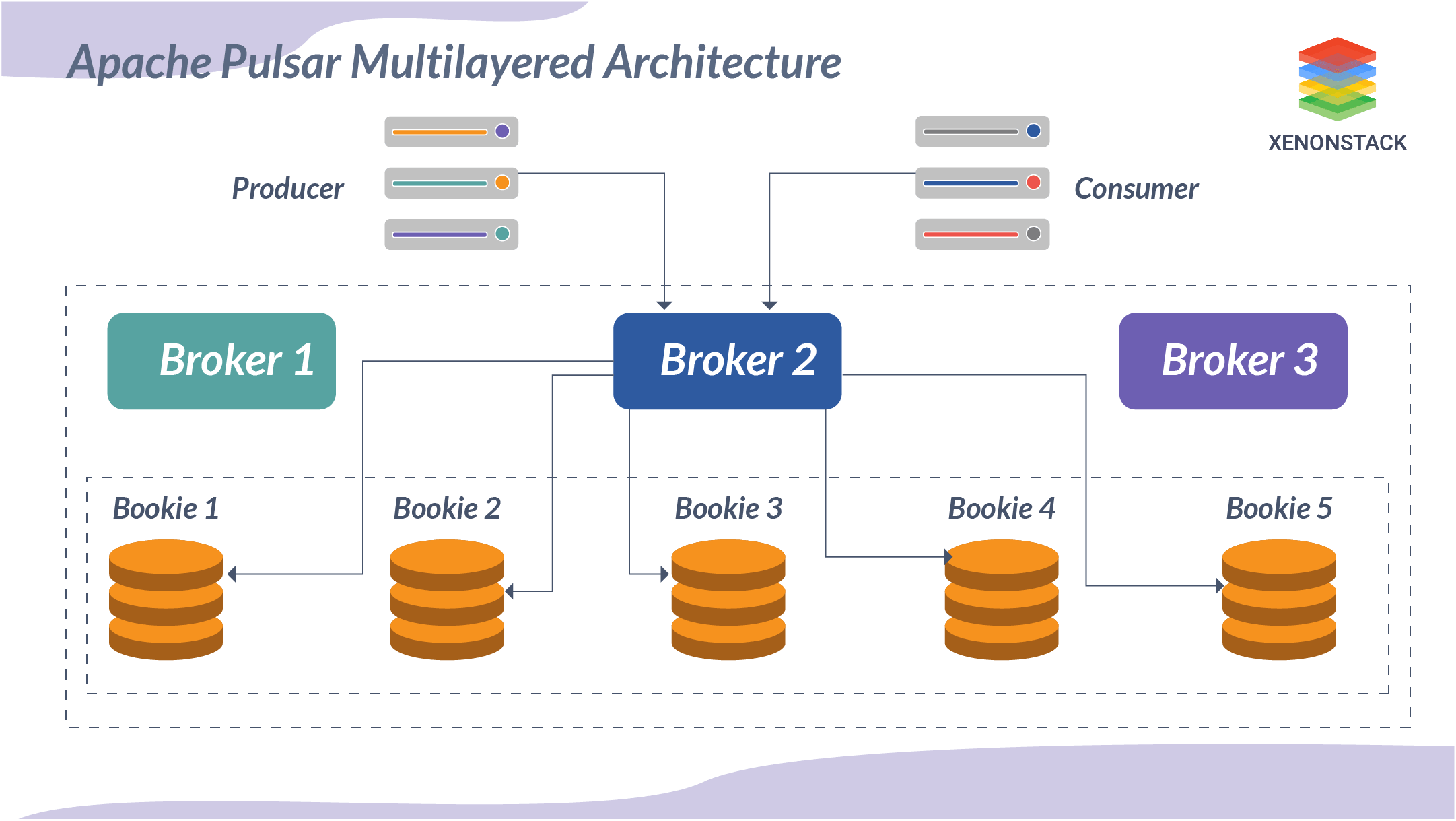
Apache Pulsar Multi-Layered Architecture
How Apache Pulsar is Better than Kafka
-
Pulsar has shown notable improvements in both latency and throughput compared to Kafka. Pulsar is approximately 2.5 times faster and has 40% less lag than Kafka.
-
In many scenarios, Kafka has shown that it doesn’t work well when there are thousands of topics and partitions, even if the data is not massive. Fortunately, the pulsar is designed to serve hundreds of thousands of items in a cluster deployed.
-
Kafka stores data and logs in dedicated files and directories (Broker), which creates trouble when scaling (files are loaded to disk periodically). In contrast, scaling is effortless in the case of the Pulsar, as Pulsar has stateless brokers, which means scaling is not rocket science. Pulsar uses bookies to store data.
-
Kafka brokers are designed to work together in a single region in the network provided, so it is not easy to work with multi-datacentre architecture. Pulsar offers geo-replication, in which users can easily replicate their data synchronously or asynchronously among any number of clusters.
-
Multi-tenancy is a feature that can be very useful as it provides different types of defined tenants that are specific to the needs of a particular client or organization. In layman's language, it’s like describing a set of properties so that each property satisfies the needs of a specific group of clients/consumers using it.
Although it looks like Kafka lags behind Pulsar, Kip (Kafka improvement proposals) covers almost all of these drawbacks in its discussion, and users can hope to see the changes in the upcoming versions of Kafka.
-
Kafka To Pulsar—A user can easily migrate to Pulsar from Kafka as Pulsar natively supports working directly with Kafka data through connectors provided, or one can import Kafka application data to Pulsar quite easily.
-
Pulsar SQL uses Presto to query the old messages kept in backlog (Apache BookKeeper).

Apache Pulsar is a powerful stream-processing platform that can learn from previously existing systems. Its layered architecture is complemented by a number of great out-of-the-box features like multi-tenancy, zero rebalancing downtime,geo-replication, proxy and durability, and TLS-based authentication/authorization. Compared to other platforms, Pulsar can give you the ultimate tools with more capabilities.


























