
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)

What is Apache Hudi?
Apache Hudi Stands for Hadoop Upserts and Incrementals to manage the Storage of large analytical datasets on HDFS. The primary purpose of Hudi is to decrease the data latency during ingestion with high efficiency. Hudi, developed by Uber, is open source, and the analytical datasets on HDFS serve out via two types of tables, Read Optimized Table and Near-Real-Time Table.
A multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters. Click to explore about, What is Apache Spark?
The primary purpose of reading an Optimized Table is to provide the query performance through columnar Storage. On the other hand, the Near-Real-Time table provides queries in Real-Time (a combination of Row-based Storage and Columnar Storage).
Apache Hudi is an Open Source Spark library for operations on Hadoop like the update, inserting, and deleting. It also allows users to pull only changed data improving the query efficiency. It further scales horizontally like any job and stores datasets directly on HDFS.
Key Difference Between Delta Lake, Iceberg, and Hudi
Here are some differences:
Concurrency
Delta Lake, Iceberg, and Hudi support atomic-level data consistency and isolation, ensuring that multiple users and tools can simultaneously work safely with the same data set. Apache Iceberg provides multiplexed updates and deletes for data stored in tables and columns.
Partition evolution
Partition evolution allows updating the partitioning scheme without overwriting all previous data. Iceberg is the only table format that supports partition evolution.
File formats
Delta Lake and Hudi use parquet files for data storage. Iceberg supports three types of data: Parquet, Avro, and ORC.
Apache Hudi Vs. Apache Kudu
Apache Kudu is quite similar to Hudi; Apache Kudu is also used for Real-Time analytics on Petabytes of data and support for upsets. The primary key difference between Apache Kudu and Hudi is that Kudu attempts to serve as a data store for OLTP(Online Transaction Processing) workloads but the other hand, but Hudi does not; it only supports OLAP (Online Analytical Processing).
Apache Kudu does not support incremental pulling, but Hudi supports incremental pulling. There is another main key difference: Hudi is wholly based on the Hadoop-compatible file system such as HDFS, S3, or Ceph, and Hudi also doesn't have a storage server. But on the other hand, Apache Kudu has Storage servers that further talk to each other via RAFT. Hudi depends on Apache Spark for heavy lifting so that Hudi can be scaled easily, just like other spark jobs.

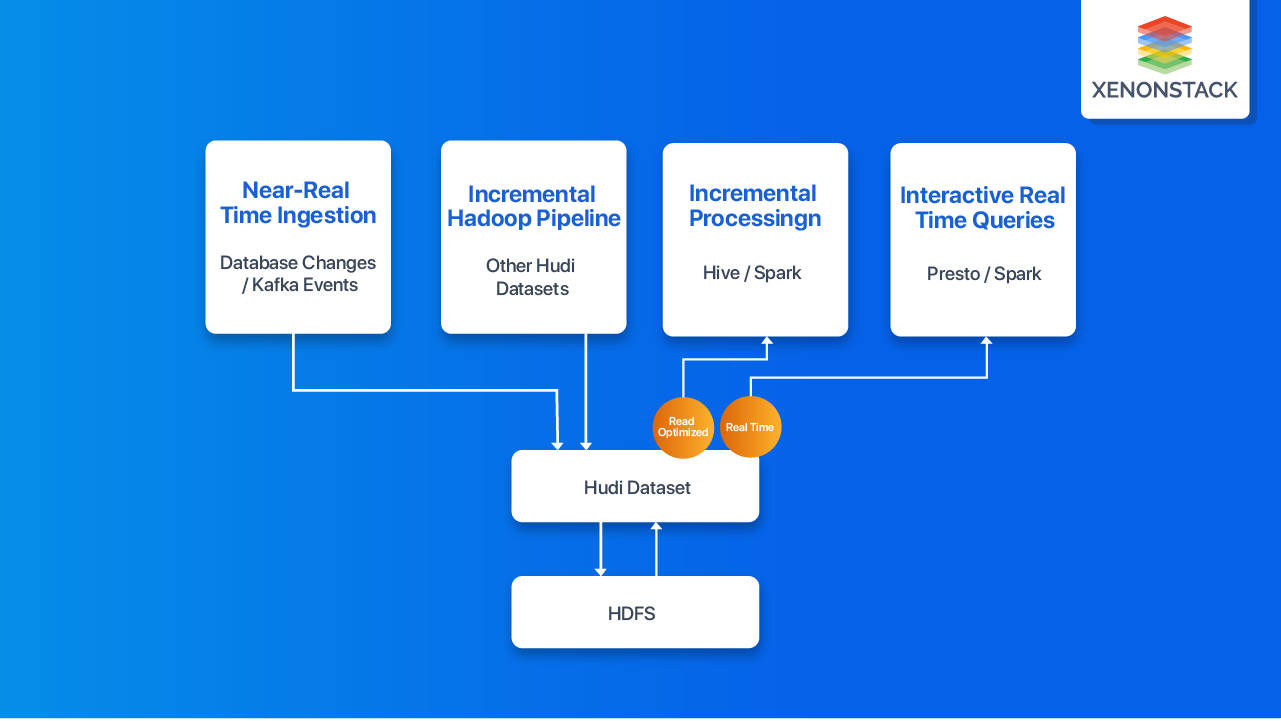
What is Apache Hudi Architecture
Hudi provides the following primitives over datasets on HDFS -
- Upsert
- Incremental consumption
Apache Hudi maintains the timeline of all activity performed on the dataset to provide instantaneous views of the dataset. Hudi organizes datasets into a directory structure under a basepath similar to Hive tables. Dataset is broken up into partitions; folders contain files for that partition.
Partitio, what uniquely identifies each partition is Apache Hudi Architecture? n path relative to the base path. Each partition record is distributed into multiple files. Each file has a unique file id and the commit that produced the file. In case of updates, multiple files share the same file id but are written at different commits.
Storage Type - it only deals with how data is stored.
- Copy on write.
- Purely Columnar.
- Create a new version of the files.
- Merge On Reading.
- Near-Real-Time.
Views - On the other hand, Views deal with how data is read.
Read Optimized View - Input Format picks only Compacted Columnar Files.
- Parquet Query Performance.
- ~30 mins latency for ~500GB.
- Target existing Hive tables.
Real-Time View
- Hybrid of row & columnar data.
- ~1-5 mins latency.
- Brings Near-Real-Time Tables.
Log View
- A stream of changes to the dataset.
- Enables Incremental Pull.
The Spark application comprises a Driver program that runs the primary function and is responsible for various parallel operations on the given cluster. Click to explore the Guide to RDD in Apache Spark.
Spark application is made-up of a Driver program which runs the primary function and is responsible for various parallel operations on the given cluster. Click to explore about, Guide to RDD in Apache Spark
Apache Hudi Storage consists of distinct parts
-
Metadata - It maintains the metadata of all activity performed on the dataset as a timeline, which allows instantaneous views of the dataset stored under a metadata directory in the basepath. The types of actions in the timeline.
-
Commits - A single commit capture information about an atomic write of a batch of records into a dataset. A monotonically increases timestamp identifies the Commits, denoting the start of the write operation.
-
Cleans - Clean the older versions of files in the dataset that will no longer be used in a running query.
-
Compactions - It is the foundation action to accommodate differential information structures.
-
Index - It maintains an index to quickly map an incoming record key to a file if the record key is already present.
- Index implementation is pluggable
- Bloom filter in each data file footer
It's preferred as the default option since there is no dependency on any external system. Index and data are always consistent with one another.
Apache HBase- Efficient for a small batch of keys. It's likely to shave off a few seconds during index tagging.
Data - Hudi stores ingested data in two different storage formats. The actual formats used are pluggable but require the following characteristics -
- Read-Optimized columnar storage format (ROFormat). The default is Apache Parquet.
- Write-Optimized row-based storage format ( WOFormat). The default is Apache Avro.
Big Data Architecture helps design the Data Pipeline with the various requirements of either the Batch Processing System. Click to explore about, Guide to Big Data Architecture
Why Apache Hudi is Important for Applications?
Hudi solves the following limitations -
-
Scalability limit in HDFS.
-
Need for faster data delivery in Hadoop.
-
There is no direct support for updates and deletions of existing data.
-
Fast ETL and modeling.
-
To retrieve all the records updated, regardless of whether these updates are new records added to recent date partitions or updates to older data, Hudi allows the user the last checkpoint timestamp. This process also disables executing a query that scans the entire source table.
How to Adopt Hudi for Data Pipelines with Apache Spark?
Download Hudi
$ mvn clean install -DskipTests -DskipITs
$ mvn clean install -DskipTests -DskipITs -Dhive11
Version Compatibility
Hudi requires Java 8 installation. Hudi works with Spark-2.x versions.| Hadoop | Hive | Spark | Instructions to Build Hoodie |
| Apache Hadoop-2.8.4 | Apache Hive-2.3.3 | spark-2.[1-3].x | Use “mvn clean install -DskipTests” |
| Apache Hadoop-2.7.3 | Apache Hive-1.2.1 | spark-2.[1-3].x | Use “mvn clean install -DskipTests” |
Generate a Hudi Dataset
Setting the Environment Variableexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre/
export HIVE_HOME=/var/hadoop/setup/apache-hive-1.1.0-cdh5.7.2-bin
export HADOOP_HOME=/var/hadoop/setup/hadoop-2.6.0-cdh5.7.2
export HADOOP_INSTALL=/var/hadoop/setup/hadoop-2.6.0-cdh5.7.2
export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop
export SPARK_HOME=/var/hadoop/setup/spark-2.3.1-bin-hadoop2.7
export SPARK_INSTALL=$SPARK_HOME
export SPARK_CONF_DIR=$SPARK_HOME/conf
export PATH=$JAVA_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$SPARK_INSTALL/bin:$PATH
Supported API'S
Use the DataSource API to quickly start reading or writing Hudi datasets in a few lines of code. Use the RDD API to perform more involved actions and a Hudi dataset.
What are the Best Practices of Apache Hudi?
Use a new type of HoodieRecordPayload and keep the previous persisted one as the output of combineAndGetUpdateValue(...). However, the commit time of the previous persisted one updated to the latest, which makes the downstream incremental ETL count this record twice. A left join data frame with all the persisted data by key and insert the records whose persisted_data.
The key is null. The concern is not sure bloomIndex /metadata has taken full advantage. Put a new flag field in the HoodieRecord reading from HoodieRecordPayload metadata to indicate if a copyOldRecord is needed during writing. Pass down a flag during data frame options to enforce this entire job will be copied Old Record.
What are the benefits of Apache Hudi?
-
Scalability limitation in HDFS.
-
Fast data delivery in Hadoop.
-
For updates and deletes of existing data, there is no Direct support.
-
Fast ETL and modeling.


























