
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
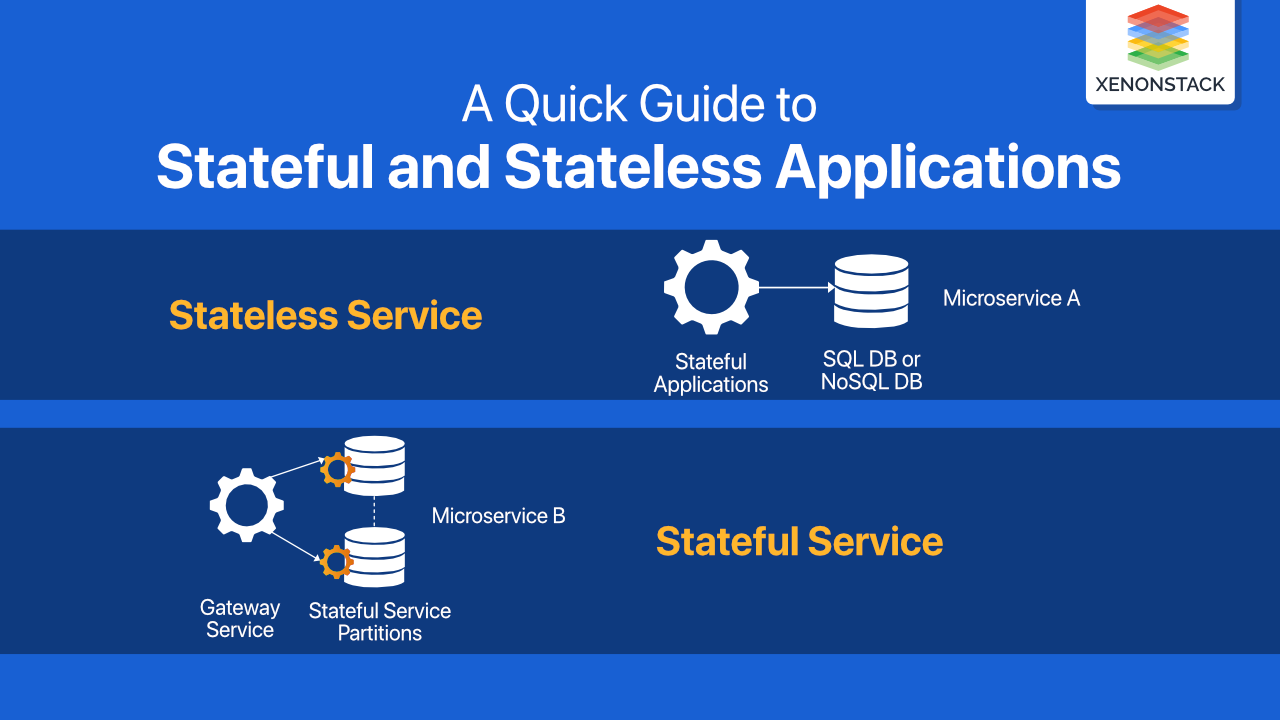
Overview of Stateful and Stateless Applications
Stateful and stateless applications play distinct roles in modern software architecture. Stateful applications maintain application state across requests, supporting use cases like session management and database management. In contrast, stateless applications do not retain state, offering simpler, more scalable designs. When deploying stateful and stateless applications in Kubernetes, best practices such as load balancing for stateless apps and ensuring fault tolerance are crucial. Emphasizing microservices architecture and cloud-native applications enables better performance optimization and enhances the user experience in both stateful and stateless environments.
What are Stateful and Stateless Applications?
Understanding the concept is the foundation upon which most architectures and designs are based — concepts like RESTful design principles are built on these foundations, so having a solid logical framework is critical. Let us dive in.
Stateless Application
A stateless application does not save or reference information about previous operations. Each time, it carries out each operation from scratch, just like the first time, and provides functionality to use print, CDN (Content Delivery Network), or Web Servers to process every short-term request. For example, if someone is searching for a question in a search engine and presses the Enter button, the operation does not retain the previous context. If the search operation gets interrupted or closed for some reason, the user has to start a new one, as there is no saved data or session data storage for the previous request. Session management is not needed in this case as there is no state for managing applications.
Stateful Application
A stateful application remembers specific details of a user, such as profile, preferences, and user actions. This information is considered the ‘state’ of a system. For example, your shopping cart while using any website in the cloud-native applications. Each time you select an item and add it to your cart, it accumulates with the items added previously, and eventually, you can navigate to the checkout page without losing any data. Application state management is crucial here to ensure the stateful application in Kubernetes can manage and maintain this data properly, especially when scaling or dealing with distributed databases.

Stateful and Stateless Sessions: What Sets Them Apart
Both stateful applications and stateless applications store application state management from client requests on the server itself, using that state to process further requests. A stateful application uses a database for session data storage but keeps session information on the server itself. When a user sends a login request, it enables login to be true, and the user is authenticated. On the second request, the user can view their dashboard.
Stateful applications do not need to make a second call to the database as the session information is stored on the server itself, making it faster and more efficient. This enhances performance optimization for applications. Stateful and stateless applications Kubernetes highlight the importance of handling session management efficiently in a microservices architecture.
-
If there’s a load balancer and two servers behind it running the same stateful application, the first login request might go to Server 1, but the second request might go to Server 2.
-
Since only Server 1 has enabled the login to be true, the user won't be authenticated when redirected to Server 2. This issue impacts the scalability of applications and is a challenge for the horizontal scaling of stateful applications.
This limitation highlights server complexity and challenges in fault tolerance in applications.
In contrast, stateless applications do not store session data on the server, and each request is treated independently, making them more suitable for horizontal scaling and load balancing for stateless apps. In cloud-native applications, understanding stateless vs stateful applications and their role in distributed databases and caching mechanisms is crucial for building scalable systems.

Managing Stateful and Stateless Containers for Scalability
While stateless applications work in different ways, they don’t store any state on the server. They use DB to store all the info. DB is stateful, i.e., it has persistent storage attached to it.
-
User Authentication and Token Management: In a typical scenario, a user requests login with their credentials, and any of the servers behind the load balancer (LB) process the request, generate an authentication token, store it in the database, and return the token to the client on the front end.
-
Token Validation and Stateless Request Processing: For subsequent requests, the client sends the token along with the request. No matter which server processes the request, it will validate the token by matching it with the information stored in the database and grant the user access accordingly.
-
Independence of Requests in Stateless Applications: Each request in a stateless application is independent and has no connection to previous or future requests, which is a key characteristic of RESTful design principles.
-
Horizontal Scaling in Stateless Applications: While stateless applications incur the overhead of making a call to the database for each request, they excel at horizontal scaling. This scalability is crucial for modern applications, which may need to handle millions of users efficiently.
-
State Management in Modern and Legacy Applications: Both modern and legacy applications share a common trait: the decision to store state or not. Whether dealing with monolithic or microservices architectures, this decision depends on the application’s needs. Some applications require state storage, while others do not need to manage state.
Stateful vs Stateless Applications: Key Differences Unveiled
Both are omnipresent in IT shops. However, modern software is being architected in a stateless manner since scaling is an essential factor in today's world. The eight main differences are below:
|
Aspect |
Stateful Application |
Stateless Application |
|
State of Working |
Reacts based on the current state and remembers previous interactions |
Acts independently and doesn’t remember past requests (stateless vs stateful application) |
|
Stored Data |
Data is stored in the backend to identify users as always-connected clients (database management for stateful apps) |
Data is stored in a database to verify users or clients as needed (session management) |
|
Reaction toward Clients |
Server considers the client a "dumb machine" and manages the state (stateful application in kubernetes) |
Server treats the client as an intelligent machine, relying on the client to manage state |
|
Requests |
Requests depend on the server-side state and may require complex session data storage |
Requests are self-contained and handled in two distinct phases: “request” and “response” (scalability of applications) |
|
Generated State |
State is generated during interaction and stored on the server (typically with session management) |
State is generated during interaction but stored client-side, like in cookies (session management) |
|
State Stored |
The server stores the application state management for future requests |
The client stores the state, making it stateless in practice |
|
Cookie Stores |
On the server side, authentication data is stored in databases or temporary session data (fault tolerance in applications) |
Cookies store authentication data on the client side for state maintenance (load balancing for stateless apps) |
|
User Base |
Typically seen in monolithic architectures, less dynamic with limited scalability |
Fits well in microservices architecture, facilitating scalability of applications and allowing easier communication via RESTful design principles |
Why Stateless Applications Matter for Modern Development
Stateful apps are excellent for minimal use cases, but they have some issues. First, when the user references a state on the server, the user opens a lot of incomplete sessions, and transactions happen.
In a stateful system, the state is calculated by the client. How long should the system leave the connection open? How do we verify on the server side that the client crashed or disconnected from the session? How are the actions of the user tracked while maintaining document changes and doing rollbacks?
Issues with Stateful Applications
Most consumers/clients respond to the server in intelligent, dynamic ways, thus maintaining a server state independent of the client, assuming the client is merely a “dumb” client. This approach can be wasteful, leading to server complexity and inefficiencies in session management.
The Need for Statelessness in Modern Applications
Statelessness is a fundamental aspect of modern applications – every day, users interact with a variety of stateless services and applications. These applications use HTTP to connect in a stateless way, utilizing messages that are rendered and work independently within the isolation of each other and the client state.
Example of Stateless Services
Facebook continually uses a stateless service. When the server requests a list of recent messages using the Facebook API, it issues a GET request with a token and date. The response is independent of any server state, and everything is stored on the client’s machine in the form of a cache. Similarly, invoking a POST command passes a complex body with authorization/authentication data in the header without considering the server state.
RESTful Design Principles
There is no relationship between the previous, current, and next request in a stateless application. In stateless applications, the client does not wait for synchronization from the server. There is no process completion concept in serverless architecture for big data, which makes it faster. REST is a mainstream way of designing, architecting, and developing modern APIs, and Representational State Transfer (REST) is inherently stateless.
Moving to microservices and containers helps enterprises seeking to move past legacy technologies, but challenges still remain.
How Stateless Applications Work and Drive Efficiency
Stateless Architecture means the app is dependent only on third-party storage because it doesn’t store any kind of state in memory or on its disk. All data it needs or requires must be fetched from some other stateful service (like a database) or present in the CRUD request.
-
Step 1: Requests are load-balanced to any replica of a stateless service because it has all data stored somewhere else, usually in a database with persistent storage.
-
Step 2: When the volume of concurrent users grows in stateful applications, more servers run the added applications, and the load is distributed evenly between those servers using a load balancer. However, since each server ‘remembers’ each logged-in user’s state, it becomes necessary to configure this load balancer in ‘sticky mode.’
-
Step 3: While distributing the load across servers, the load balancer is required to send each user’s request to the same server that responded to their previous request in stateful systems to process the request correctly. This defeats the purpose of load balancing because the load is not distributed in a true Round-Robin fashion.
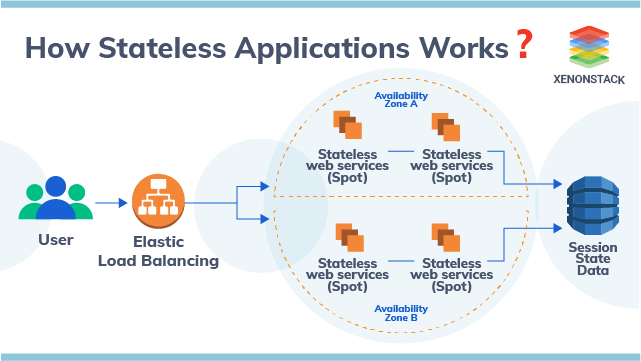
Fig 1: The Working of Stateless Application
-
Step 4: In stateless applications, the server-side logic is coded in such a way that it does not depend on the ‘previously stored state’ of the client, ensuring there’s no need to remember past interactions.
-
Step 5: The state information is sent along with each request to the server, allowing the server to proceed with servicing the request. The load balancer doesn’t need to worry about routing requests to the same server and truly uniform load balancing is achieved.
-
Step 6: The load balancer sends traffic to any server, and requests are serviced well since the client sends a token or other necessary information with each request. JSON Web Token (JWT) is widely used to create stateless applications.
Key Benefits of Adopting Stateless Application Architecture
The following are the major advantages of the stateless application:
-
Eliminates Session Overhead: One of the main benefits is the removal of the overhead associated with creating and managing sessions, which simplifies application state management.
-
Horizontal Scalability: Stateless applications can scale horizontally to accommodate the growing demands of modern users. Since the application does not store state locally, it is easier to add new instances as needed.
-
Dynamic Instance Management: Stateless applications allow new instances of an application to be added or removed on demand, providing greater flexibility and efficiency in managing workloads.
-
Consistency Across Applications: By not relying on session data, statelessness ensures consistency across various applications, making it easier to manage and integrate different systems.
-
Enhanced Maintainability: Statelessness makes an application easier to maintain, as there is no need to track or store state, reducing server complexity and improving overall system performance.
-
Reduced Memory Usage on the Server Side: Since stateless applications do not store session data on the server, memory usage is minimized, leading to improved resource utilization.
-
Eliminates Session Expiry Issues: Stateless applications avoid problems related to session expiry, which can be difficult to test and troubleshoot in stateful applications. As there are no sessions to expire, these applications do not suffer from such issues.
-
Improved User Experience: From the user’s perspective, statelessness allows resources to be linkable. For example, if a page is stateless, sharing a link to the page ensures that different users view the same content without relying on server-side session data.
Explore more about Microservices with Golang – A Complete Solution to building scalable, efficient, and maintainable systems.
Steps to Successfully Adopt Stateless Application Design
The following are the 5 steps to adopt stateless applications:Adapt and Develop New Applications
Adopting stateless applications can be a daunting task at first since it’s a new paradigm. However, with the right mindset and information, new applications can be adapted and developed without keeping any state. Use authentication and authorization to connect to the server, eliminating the need to store session data on the server.
Develop Applications using Microservices
In this step, containerization will be used for deployment purposes. Containers are best at running stateless workloads. When managing several containers, consider switching to cloud orchestration and management tools such as Kubernetes to run a large number of containers efficiently.
Containerized Microservices Applications
Find the best location to run container security from a resource perspective and maintain the application's High Availability (HA). This ensures the application remains reliable and secure while running at scale.
Attach Storage to Stateless Ephemeral
Storage attached to stateless applications is ephemeral. Organizations must start with stateless containers, as they are more easily adapted to this type of architecture, which is separate from monolithic applications and allows for independent scaling.
Apply REST Philosophy
The backend should follow RESTful design principles for building applications. The REST philosophy dictates that the state should not be maintained on the server side, with only minimal use of cookies or local storage on the client side.
Best Practices for Maintaining Stateless Applications
Here are nine simple practices for properly maintaining stateless applications:
- Avoid Sessions: Try to avoid using sessions at all costs. Sessions add unnecessary complexity and provide minimal value.
- Difficulty in Reproducing Bugs: Using sessions makes it difficult to reproduce bugs since session data is stored on the server side.
- Hard to Fix Session-Related Bugs: Since everything is stored on the server, fixing session-related bugs becomes more complicated.
- Scaling Issues with Sessions: Sessions cannot be scaled effectively. As the load on the application increases, distributing the load across servers becomes harder when using sessions.
- Replicating Sessions Across Servers: If using sessions, replicating them across all servers becomes necessary. This increases complexity and makes the system prone to errors. Avoid sessions for smoother scalability.
- Sessions Are Only Useful for Specific Use Cases: Sessions are useful for particular use cases, such as FTP (File Transfer Protocol).
- Stateful Sessions Add Overhead: For use cases like shared Dropbox, stateful sessions add unnecessary overhead. Stateless solutions are the ideal approach.
- Replicating Session Functionality with Cookies: Session functionality can be replicated using cookies and caching on the client side, which makes the system simpler and more scalable.
- Leverage Stateless Design for Scalability: Emphasize statelessness for easy scaling and better management, especially in distributed systems.
Best Tools for Building Stateless Applications Effectively
Here are the best stateless application tools:
Modern Programming Languages
Languages like Python and Golang are ideal for developing stateless applications due to their efficiency and scalability.
Containers and Orchestration
For deployment purposes, Docker and Kubernetes are widely used to manage and scale stateless workloads.
Service Discovery
Tools like Kube Proxy and Etcd are essential for service discovery in distributed systems.
API Gateway
An API Gateway helps connect various services from outside, ensuring smooth communication between the client and the backend.
Service Mesh
LinkerD and Istio are popular tools for implementing a service mesh around all stateless applications, enhancing communication, security, and monitoring.
Embracing Stateless Design for Future Success
Most IT companies that build microservices are already creating stateless applications using REST API design. Understanding this concept is fundamental, as it forms the foundation for modern architecture, including RESTful design principles. A solid grasp of the advantages of stateless over stateful applications is essential for developing applications that can meet the massive demands of today’s users.




