
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Data Preparation
Data preparation plays a vital role in AI systems. AI systems predict based on historical data. Therefore it is compulsory to use correct, biased free data to get a fair result. To get optimum output from a system, it needs a big amount of data. It is easy to get big data in today's world, but most of that data is unstructured. It is difficult to get structured, correct, and biased free data that the system can understand. Before modeling, we need to perform data processing to make this data suitable for the machine to understand. It prepares data in a format that machines can easily use. In this document, first, we will discuss the features that the Xenonstack data preparation system contains and the needs of these features and then discuss how it works. It contains EDA, dataset description standardization, data summarization, and explainable feature engineering.
Data Preparation Process
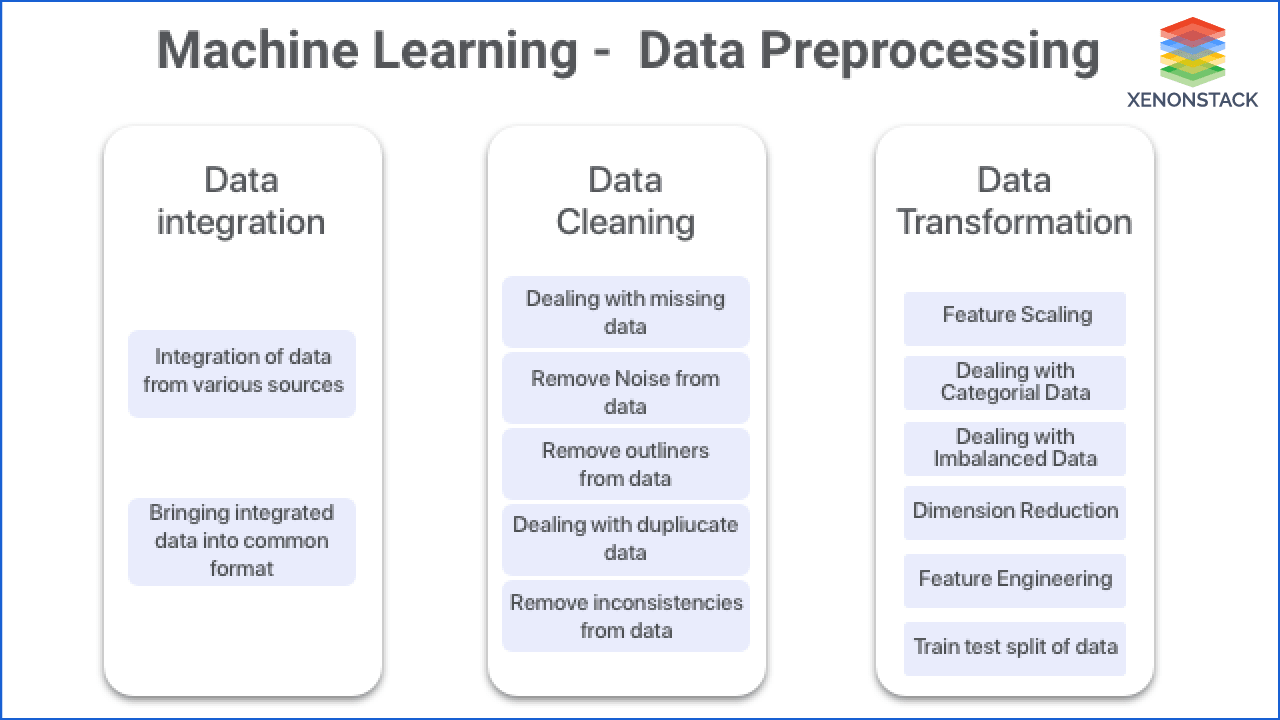
Data preparation step contain the following features:
Exploratory Data Analysis
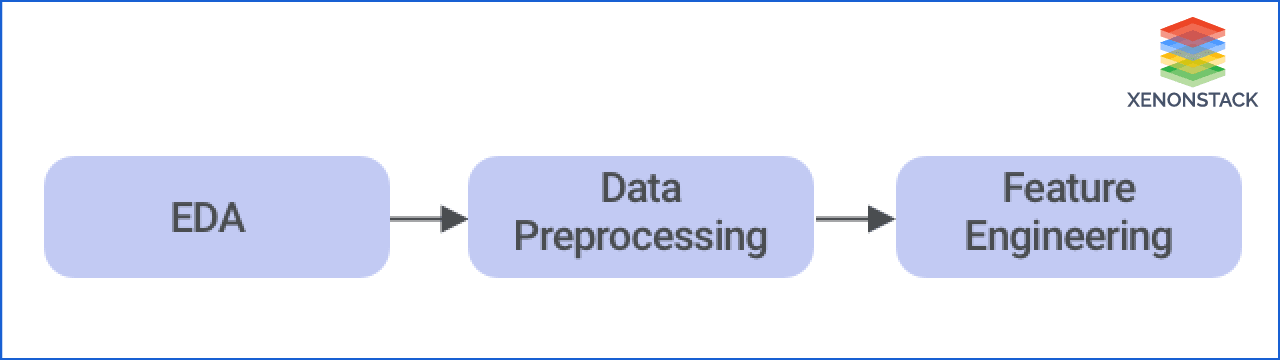
EDA (Exploratory Data Analysis): As we discussed, the data can be in raw form, and we have to convert it into the machine-understandable format. But before preparing data, we should understand the data that is provided to the system. First, we have to find flaws in data so that the system can work accordingly.
- It helps to understand the features and characteristics of data.
- Relationship between data.
- Characteristics of data.
- Check and validate missing values, anomalies, outliers, scale, human errors, etc.
- To find hidden patterns.
Data Processing
Data processing contains several subtasks. Let's discuss it.
Missing values: It can be possible that some of the values are missing in the data. It is necessary to deal with these missing values before using data in models. There are several techniques to deal with those values according to the percentage of values missed in the dataset.
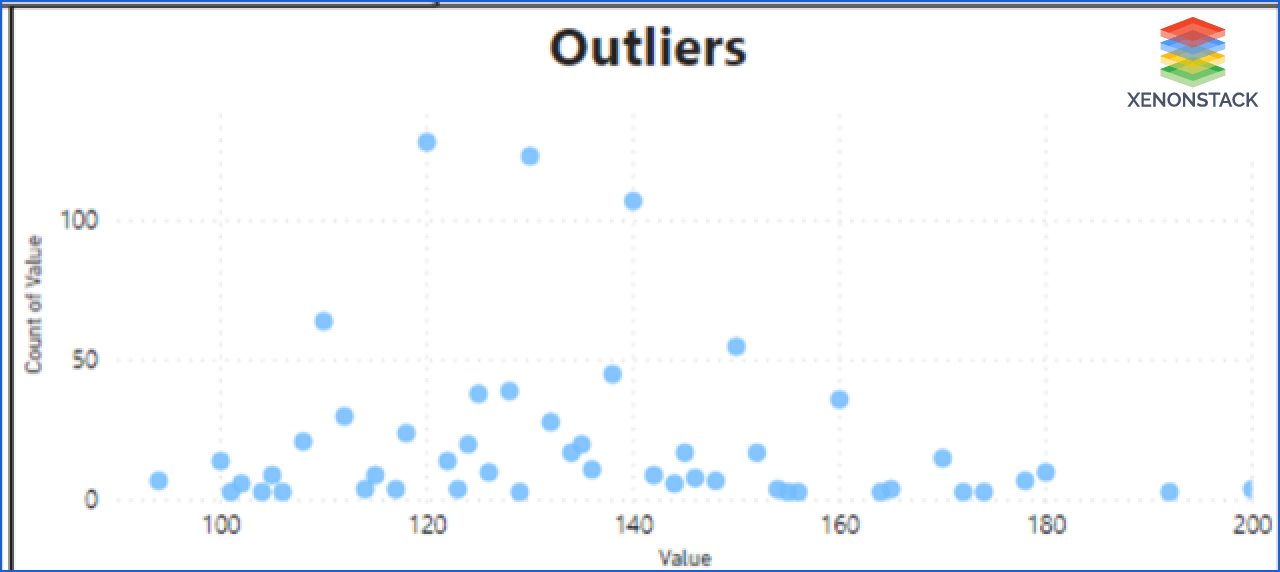
Outliers: Outliers are something that does not belong to the values. It can spoil and mislead the training process. Therefore it's necessary to detect and remove the outliers.
Redundant data: It can be possible that the uploaded dataset contains redundant or identical rows or data. This can generate bias in the system. Therefore it is necessary to remove those redundant data to get a fair result. Therefore it is necessary to remove those data.
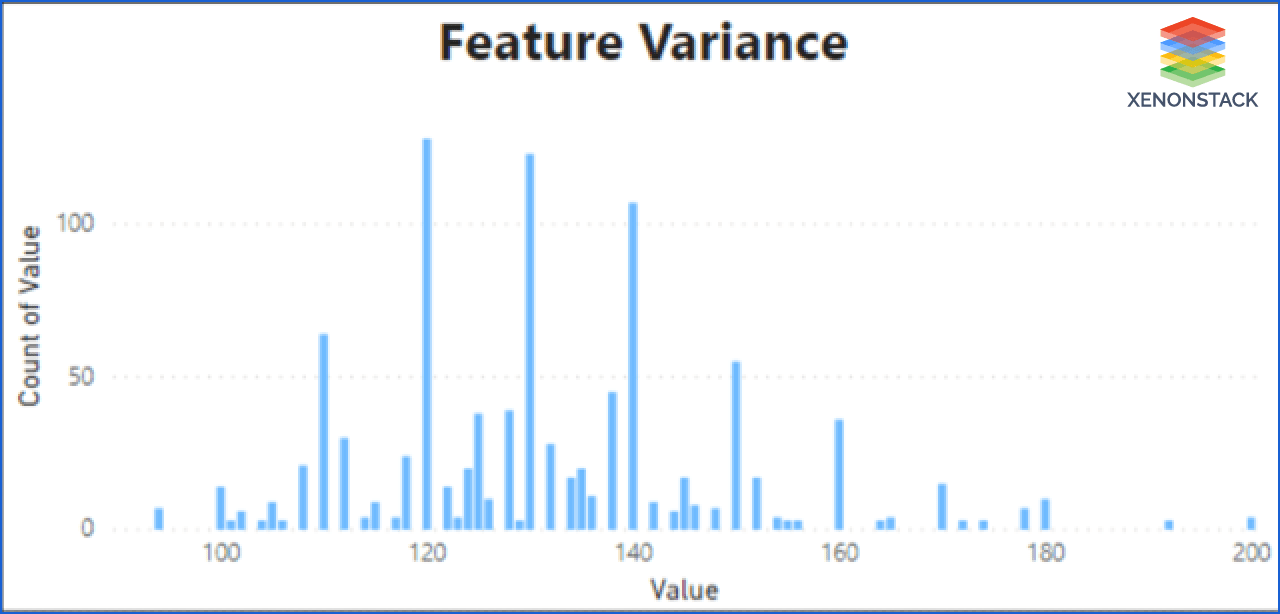
Low Variance: Suppose there is a feature that remains constant most of the time in the dataset. This feature cannot influence varied target results. There we can remove features that have low variance.
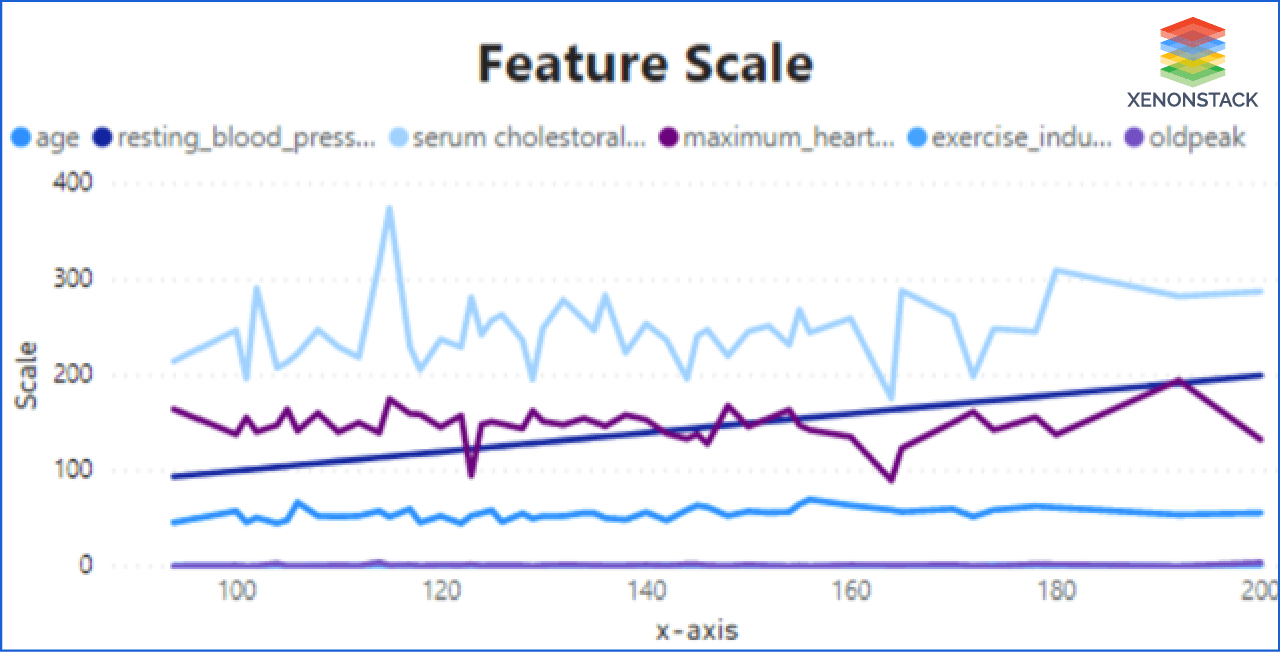
Scaling: There can be numerous features in data that are used for AI systems. And it is also possible that they can vary in scale. It can be possible that some of them dominate others. Therefore it is mandatory to scale these all features.
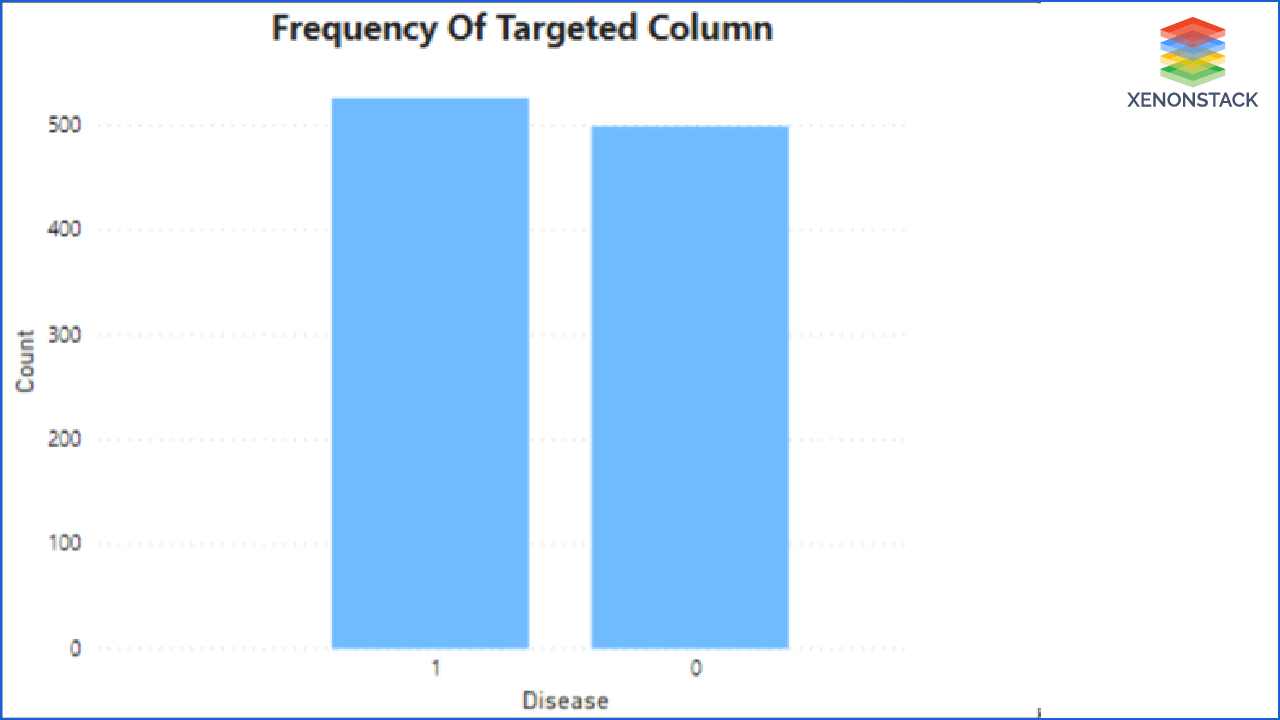
Imbalanced Data: In classification algorithms, it is compulsory to have a balanced class to get the correct result. But it can be possible that data classes are imbalanced that can give the biased result. So to make them balanced, we can use oversampling and undersampling techniques.
Correlated Data: It checks for the correlation between different features. Because the correlation between two features exceeds 99%, one from both features can be deleted. It is safe and also reduces the load of data.
Categorical Values: It is obvious that a dataset contains categorical or text values. But most of the models contain mathematical formulas. Therefore it is necessary to convert them into numeric before using them. The system is looking for those categorical values and converting them into numeric ones. Here are several techniques to convert them into numeric.
Feature Engineering
It is the process of creating features that help the machine learning algorithm works. Feature Engineering contains the following steps.
Feature Importance and Selection: There can be several columns in the dataset. It may be possible that some of them are not at all important for the output. But this unimportant data can increase the load on the model. But Xenonstack provides a solution for that. It selects the features that are important for the output and uses them for the prediction. Correct feature selection also improves the accuracy of the model.
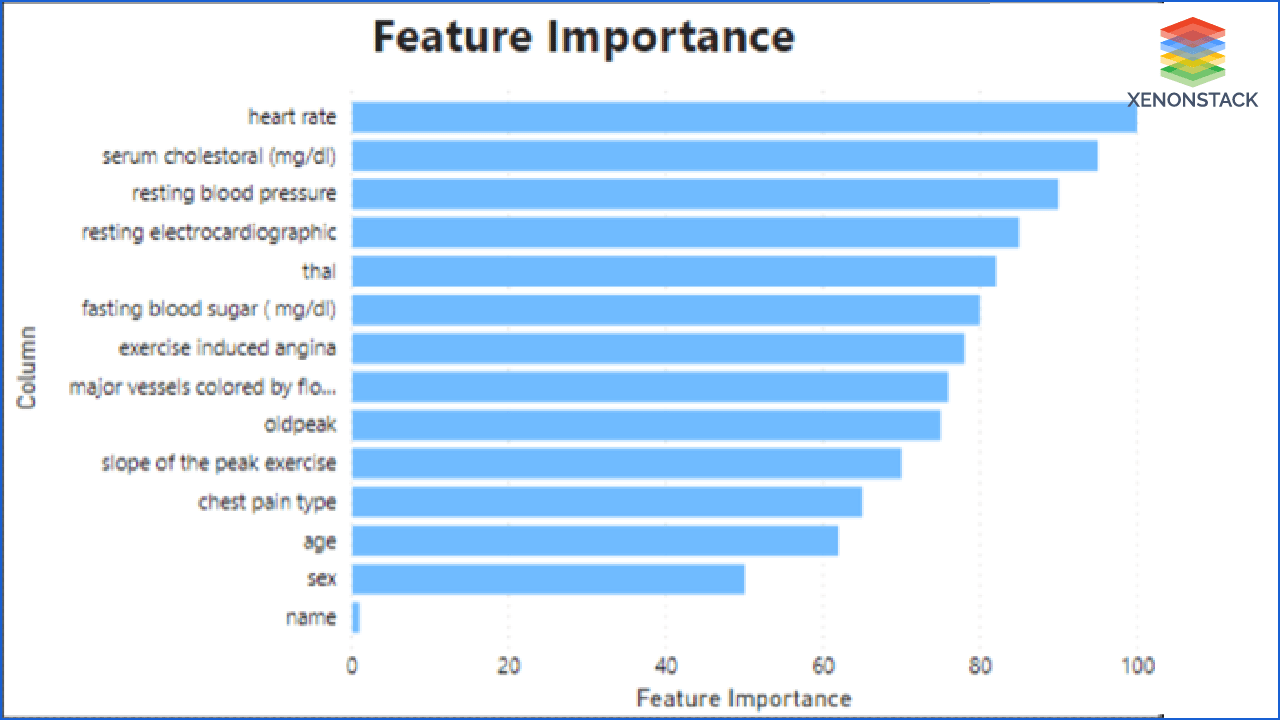
Feature importance is measured by the correlation between targeted and individual features. Feature's importance depends on the strength of their correlation.
Feature Construction: Some datasets are too volumetric. Here feature engineering can use feature extraction and dimensionality reduction using PCA (Principal Component Analysis) and can create and select more essential features for a model. It can build new features from previous elements by removing them, reducing the volume of data. It solves the problem of managing a high volume of data, especially when dealing with big data. In this technique, a linear combination of original features of the dataset is transformed into new ones.
Feature Aggregation: To give a better perspective to data, Feature aggregation is performed. Such as if we have a database containing transactional data of daily sales of different stores. Now, if we aggregate the storewide monthly of the yearly transaction, it can reduce the number of data objects. Feature aggregation helps to reduce the processing time.
Data Preparation Steps
Xenonstack provides the following feature by explaining its data preparation system.
Explanation: Xenonstack provides a step by step explanation of the process that it uses for data processing. Thus users get to know the data quality and health of data. They also get to know whether the system uses correct data or not. It also helps to decide if the system is fair or not. It provides a step by step explanation of the workflow. These are:
Step 1: First, Xenonstack provides the characteristics of the user's raw data to the system. It tells the rows, columns, missing values, and details about the target values. From data, users get to know the data quality of their provided data.
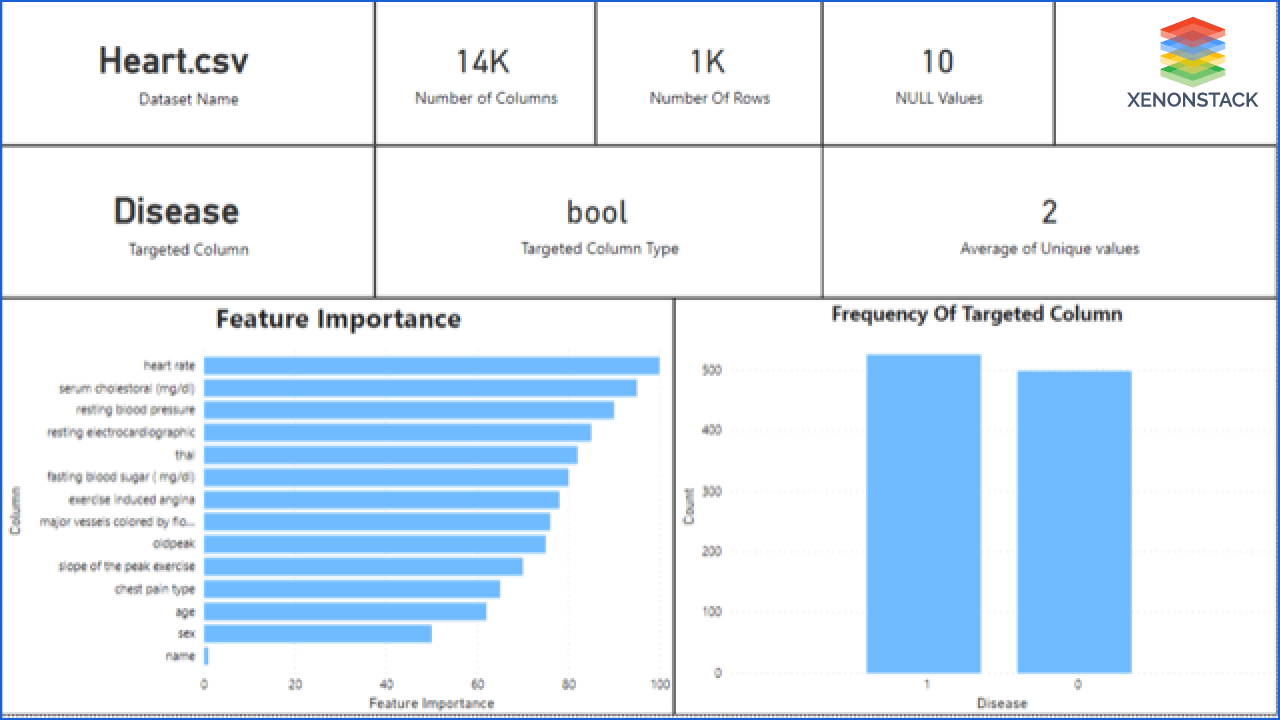
Step 2: The second step contains the EDA(Exploratory Data Analysis) of the features. It showed the correlation of features, outliers, variance, and scale of features.
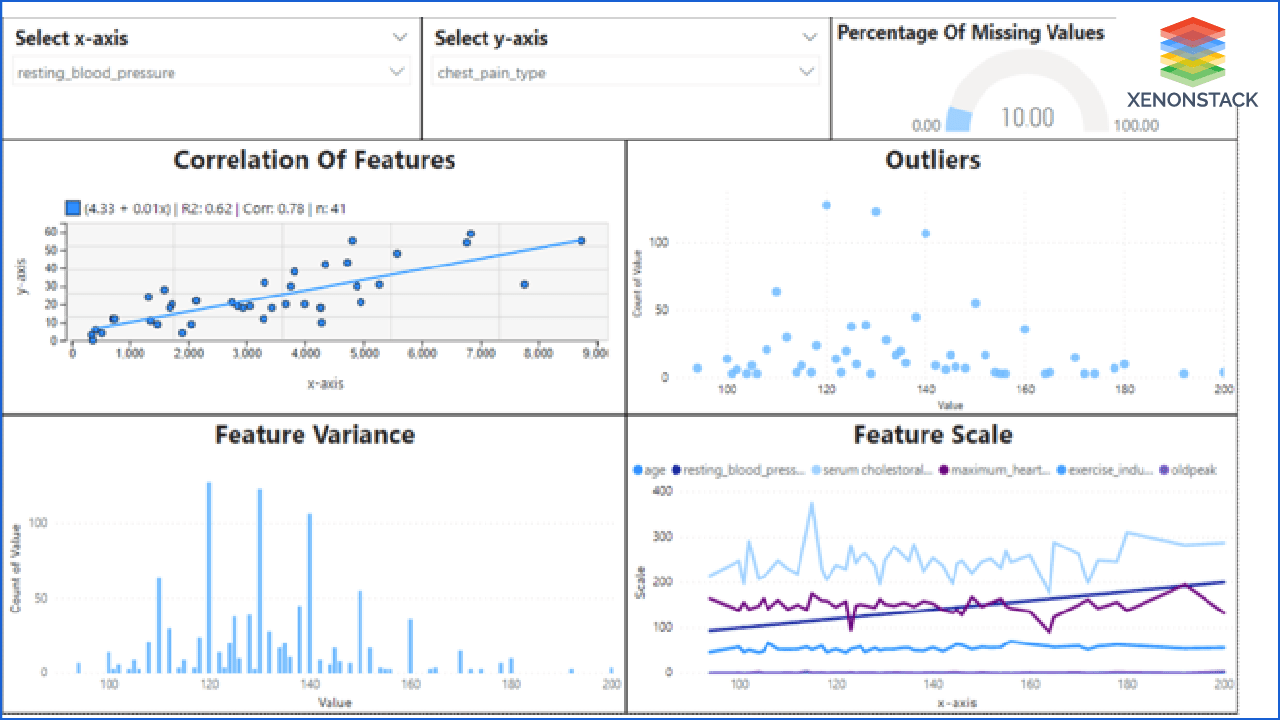
Step 3: The last step represents the processed and cleaned data that the system will use for the modeling after applying data preprocessing and feature engineering. It gives column-wise details of the feature. It also provides the feature drift and importance of features so that users get to know what are the features that are in danger.
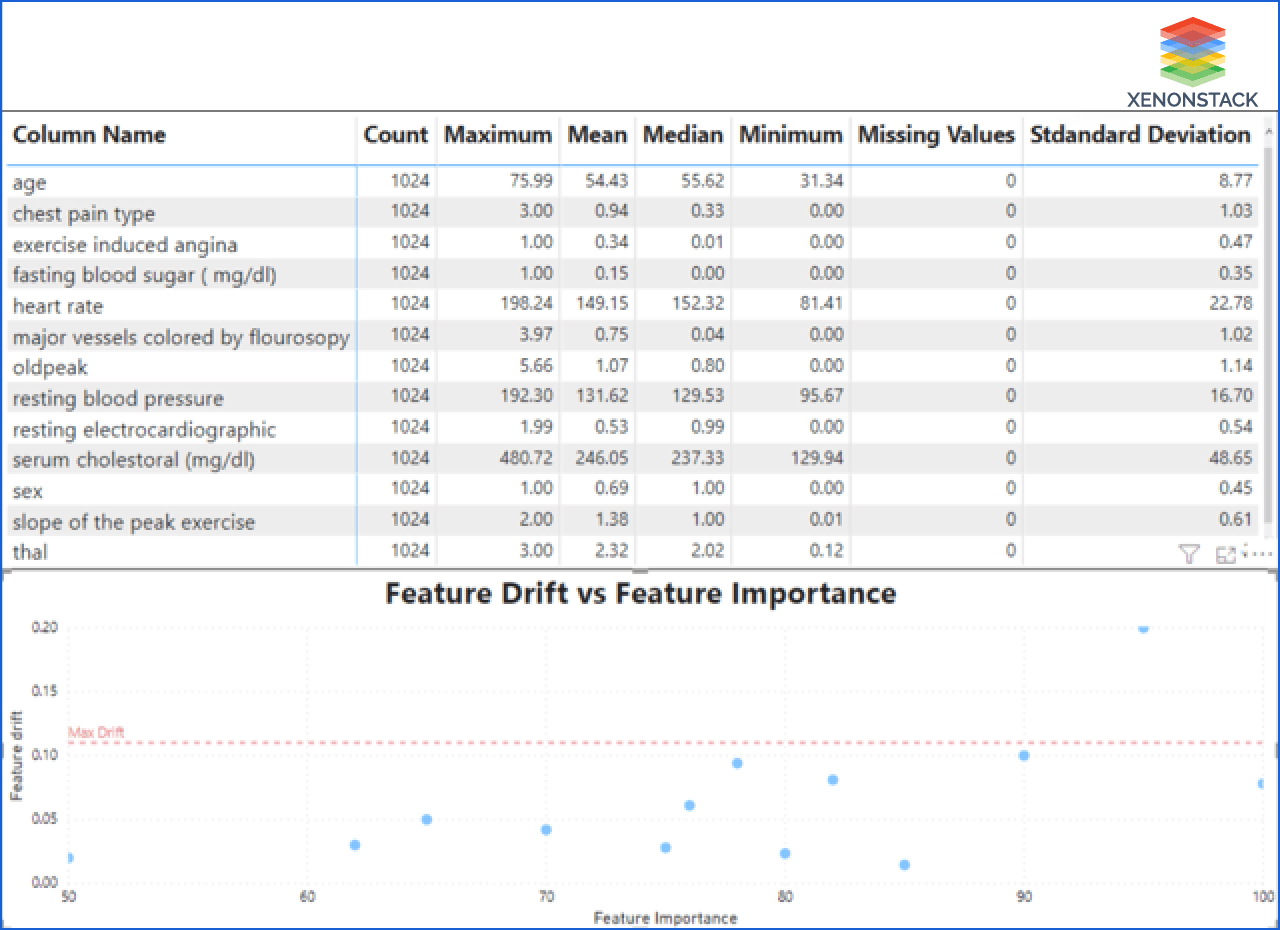
Transparent: In most AI systems, the explanation is not provided, so there is always a wall between the user and the design. Thus, it becomes hard for the user to trust the system, whether the system cleans the feature. They are also not sure what features the system uses. But Xenonstack provides a transparent system. It explains every aspect of data cleaning and transforming.
Accuracy: The system considers all the factors to make the correct data that will provide accurate results. For example, it converts all categorical values to numerical and also does the scaling of features before using it in the model.
Fair: Xenonstack takes care of fairness at every step of the system. Therefore it considers in the data preprocessing step also. For example, It selects the features according to their importance in the output to not miss any important output aspect. Similarly, it also considers the frequency of features not to show bias at any step.
Conclusion
Data preparation plays a vital role in AI systems and works on historical data. It is difficult for AI systems to understand unstructured, incorrect, and biased data. With Data Preparation Roadmap, individuals can prepare structured, correct, and biased free data for correct and better results.



























