
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is Apache Zeppelin?
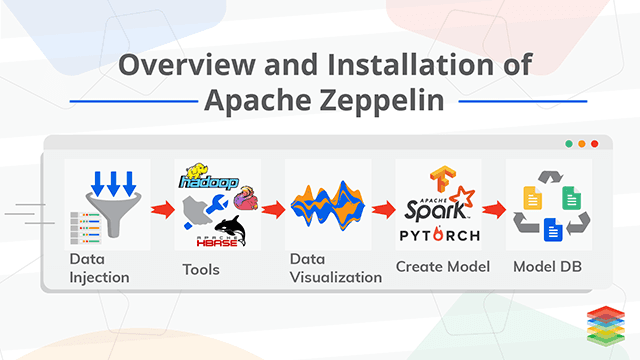
Apache Zeppelin is a kind of tool, which makes Data Scientist life smooth, they can do everything they need in one place. Things like data ingestion, data exploration, data visualization, and data analytics can be done in the zeppelin notebook. The selection of frameworks, platforms is important for Data Exploration and Visualization. There are tools which make this easy for the Data Scientist so that they can only focus on the modeling part rather than just wasting time in engineering stuff. While having choices is great, It becomes very hard for the data scientist who wants to access the data in a coherent and uniform fashion.
A part of the Big Data Architectural Layer in which components are decoupled so that analytic capabilities may begin. Click to explore about, Data Ingestion
What are the features of Apache Zeppelin?
The features of Apache Zeppelin are listed below:
- Data Ingestion: Data ingestion in zeppelin can be done with Hive, HBase and other interpreter provided by the zeppelin.
- Data Discovery: Zeppelin provide Postgres, HawQ, Spark SQL and other Data discovery tools, with spark SQL the data can be explored.
- Data Analytics: Spark, Flink, R, Python, and other useful tools are already available in the zeppelin and the functionality can be extended by simply adding the new interpreter.
- Data Visualization and Collaboration: All the basic visualization like Bar chart, Pie chart, Area chart, Line chart and scatter chart are available in a zeppelin.
How to Install Apache Zeppelin?
- Requirement: Make sure that docker is installed in the machine where Zeppelin will run on. Installing Docker Community Edition
- Getting Started: start dockerized Zeppelin with this simple command
docker run -p 8080:8080 --rm --name zeppelin apache/zeppelin:0.7.2After executing, try to access localhost:8080 in the browser. If having trouble with accessing the main page, Please clear browser cache. By default, docker container doesn’t persist any file. - As a result, the notebook will lose all the data. To persist notes and logs, set docker volume option Here is an example command for that
docker run -p 8080:8080 --rm -v $PWD/logs:/logs -v $PWD/notebook:/notebook -e ZEPPELIN_LOG_DIR='/logs' -e ZEPPELIN_NOTEBOOK_DIR='/notebook' --name zeppelin apache/zeppelin:0.7.2
A Driver program which runs the primary function and is responsible for various parallel operations on the given cluster. Click to explore about, Guide to RDD in Apache Spark
What is Zeppelin Interpreter?
Zeppelin Interpreter is the plug-in which let zeppelin user use a specific language/data-processing-backend. For example, to use Scala code in Zeppelin, you need spark interpreter. Click on the interpreter link to got to the interpreter page where the list of interpreters is available.How to Configure HAWQ with Postgres Interpreter?
Click on the edit button. After that now you are able to fill the address in the PostgreSQL.url. Add the HAWQ address in the PostgreSQL.url filed. Zeppelin interpreter setting is the configuration of a given interpreter on zeppelin server. For example, the properties required for HAWQ interpreter to connect to the PostgreSQL.Modeling with Notebook and ModelDB
Machine Learning modeling with Zeppelin is fun. All the tools and languages needed for the Modeling is available in zeppelin, It just needs to import the particular interpreter when using.Load Data
Using spark is convenient when need to load data from CSV files because it provides csv to a data frame reading function which is good for data manipulation and transformation. The finance price data will be a good example for exploration and data visualization, Let's take the Apple finance data:-Explore & Visualize Data
After loading the data into data frames, now with the show function of DF data can be explored. Also for querying the data frame lets register the template.A fast cluster computing platform developed for performing more computations and stream processing. Click to explore about, Apache Spark Optimization Techniques
Implementing ModelDB for Model Management
Modeling one model and seeing its results on somewhere is good but when there are hundreds of models with different parameters and different datasets, it will be a difficult process to manage all the models, However, there is no practical way to manage all the models that are built over time. This lack of tooling leads to insights being lost, resources wasted on re-generating old results, and difficulty collaborating. ModelDB is an end-to-end system that tracks models as they are built, extracts and stores relevant metadata (e.g., hyperparameters, data sources) for models, and makes this data available for easy querying and visualization modelDB
USE CASES
- Tracking Modeling Experiments
- Versioning Models
- Ensuring Reproducibility
- The visual exploration of models and results
- Collaboration
- Spark_ml
- Scikit-learn
- Light-api
- Create a sycer object
- Load Data and Split Training Data
- Tune Parameter and sync model with modelDB
- Monitor Your Model with ModelDB
Experiments: The overview of Experiments can be seen in the ModelDB UI. ModelDB also provides custom filters.
Metrics Comparison: ModelDB provides a view of experiments runs and metrics comparison.

Conclusion
Each system has a different set of API's, a different language to write queries in, and a different way of Process and analyzes the data at a large scale. Data visualization is the way of representing your data in form of graphs or charts so that it is easier for the decision makers to decide based on the pictorial representations. Here, comes the Apache Zeppelin, an open source multipurpose Notebook offering the following features to your data.
- Explore our Managed Apache Spark Services
- Read more about Data Serialization in Apache Hadoop
- Click here to know about Big Data Challenges, Tools & Use Cases



