
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is Serverless Computing?
Serverless Cloud Computing enables self-service provisioning and management of Servers. However, as we know in the world of Big Data, Dynamic Scaling and Cost Management are the key factors behind the success of any Analytics Platform. So, the Server Architecture exactly does that many cloud platforms such as AWS, Microsoft Azure, etc. and Open Source Technologies like Apache has launched many services which are in which code execution and will scale up or down as per the requirement, and we have to pay for Infra only for the execution time of our code.
With Serverless Architecture, developers don't need to worry about updating servers or runtimes. Instead, they can focus on their core product. Source: Building Applications with its Architectures
To add more, serverless cloud computing's main advantage is that developer does not have to think about servers ( or where my code will run) and he needs to focus on his code. All Infra Design handled by some third-party services where the code runs on their containers using Functions as a Service, and they further communicate with the Backend as a service for their Data Storage needs.
Different Cloud Platforms
- AWS: Amazon Web Services Solutions offers Cloud Consulting, Cloud Migrations, and Managed Services for Cloud in AWS. Cloud Consulting Services offers experienced and AWS Certified experts with experience covering the entire AWS Serverless Architecture.
- Azure: Microsoft Azure offers application lifecycle and cloud maturity with innovative industry-proven solutions, customized to meet the Enterprise Cloud Requirements.
- Google: Google enables an almost endless number of possibilities to manage, analyze, utilize your data with Google Cloud Platform customized to meet your unique business needs.
- OpenFaas ( with Kubernetes): It helps to Deploy, Manage, and Maintain Private and Hybrid Clouds across any Infrastructure using Kubernetes.
OpenFaas is a concept of decomposing our applications into a small unit of work, it is based on it. Source: Serverless Architecture with OpenFaaS and Java
What is Serverless Framework?
Itis an open-source web framework that is used for building applications on AWS, Microsoft Azure, Kubernetes, etc. It act as provider agnostic which means that you only need to have one tool to tap into the power of all the cloud providers.Serverless for Big Data
It is becoming very popular in the world of it. As workloads are managed by its Platforms so We don’t need an extra team to manage our Hadoop/Spark Clusters. Let’s see various points which we can consider while setting our platforms.No need for Infra Management
While working on various ETL and Analytical platforms, We found that we need many guys who can set up the Spark, Hadoop clusters, and nowadays, We use Kube Cluster and everything launched on containers. So, Monitoring them and Scaling the resources, cost optimization takes a lot of effort and resources. So Serverless make developer and manager’s life easy as they don’t have to worry about the infra.Scale on Demand
Its platforms continuously monitor the resource usage of our deployed code ( or functions) and scale up/down as per the usage. So, the developer doesn’t need to worry about scalability. Just Imagine, We have deployed some ETL job on Spark Cluster, and it runs after every hour, and let’s say at peak times, many records to extract from Data Source per hour increase to 1 million and sometimes, at midnight, it falls to the only 1k to 10k. ETL Service automatically scales up/down our job according to requirements. It's like the same we do in our Kubernetes cluster using AutoScale Mode, in that we just set the rules for CPU or Memory Usage and Kubernetes automatically takes care of scaling the cluster.Cost-Effective
Cost-Effective means that we have to pay only for the execution time of our code. It means when our deployed function is idle and not being used by any client, we do not have to pay for any infra cost for that. It's like we do not have to pay on an hourly basis to any Cloud Platform for our Infra. It's like they launch the things on the fly for us. Example: ETL platform like Glue launches the Spark Jobs according to the scheduled time of our ETL Job. So, Cloud Service will charge us only for that particular time of execution. Also, Imagine you have several endpoints/microservice / API which less frequently used. So for that type of case, It is best as we will be charged only whenever those APIs will be getting called.Built-In High Availability and Fault Tolerance
The primary architecture Providers provide built-in High Availability means our deployed application will never be down. It’s the same as we use Nginx for any application and having multiple servers deployed and Nginx automatically takes care of routing our request to any available server. In the context of it, Let’s say Our Spark’s ETL Job is running and suddenly Spark Cluster gets failed due to many reasons. So Glue will automatically re-deploy our Spark Job on the new cluster, and Ideally, Whenever a job fails, Glue should store the checkpoint of our job and resume it from wherever it fails.A time-series database is usually put in work to deal with time-stamped or time-series data. Click to explore about our, Time-series Databases in Real-Time Analytics
What is Serverless Real-Time Analytics?
Here we will discuss how we can set up a real-time analytics platform using it. Real-time Analytics Workflow: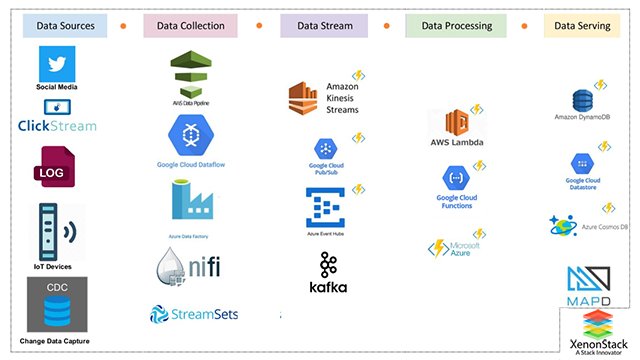
Data Collection Layer
In Real-time Analytical Platforms, Data Sources like Twitter Streaming, IoT Analytics, etc push data continuously, So the First task in these platforms is to build a unified Data Collection Layer where we can define all these Data Sources and write them to our Real-time Data Stream which can be further processed by Data Processing Engines. We can use AWS Cloud DataFlow for AWS Platforms, Google Cloud DataFlow for Google Platforms, Azure DataFactory for Azure Platforms, and Apache Nifi in case of open source platforms for defining Streaming Sources like Twitter Streaming or other Social Media Streaming which continuously loading data from Twitter Streaming EndPoints and writing it to our Real-time Streams.Data Streaming Layer
Now, we do not know that how much producers can write data means We cannot expect a fixed velocity of incoming data. So We need real-time storage which can scale up in case of a massive increase of incoming data and also scales down if the incoming data rate is slow.- AWS provides Kinesis Streams and DynamoDB Streams
- Google provides PUB/SUB service
- Azure provides Event Hubs, IoT Hubs
Data Processing Layer
The layer where we often do some Data preprocessing like Data Preparation, Data Cleaning, Data Validation, Data Transformations, etc. In this layer, We also perform real-time analytics on incoming streaming data by using the window of the last 5 or 10 minutes, etc. So While doing this stuff on Real-time Stream, We need a Data Processing Platform which can process any amount of data with consistent throughput and writes data to a Data Serving Layer. Example: In AWS Platforms, We can configure our DynamoDB Streams with AWS Lambda Function which means whenever any new record gets entered into DynamoDB, it will trigger an event to our AWS Lambda function, and the Lambda function will do the processing part and write the results to another Stream, etc. Google Platforms, We can do it using Google PUB/SUB and Google Cloud Functions/Spark using Data Proc. In Azure, We can use Azure EventHub and Azure Serverless Function for the same.Google Cloud Serverless computing makes scalability of the server to infinity, without no-load management. Source: Guide to Google Cloud Platform
Data Serving Layer
This layer is responsible for serving the results produced by our Data Processing Layer to the end-users. So This layer should also be dynamically scalable because they have to serve millions of users for Real-time Visualization. So There are two types of Serving Layer :Streams
In AWS, We can choose DynamoDB Streams as our Serving Layer on which the Data Processing layer will write results, and further a WebSocket Server will keep on consuming the results from DynamoDB, and WebSocket based Dashboard Clients will visualize the data in real-time. While Google PUB/SUB and Azure EventHub can be also used as a Streaming Serving Layer.NoSQL Datastore
We can use DynamoDB NoSQL Datastore as our Serving layer as well on top of which we can build a REST API, and Dashboard will use REST API to visualize the real-time results. Azure Cosmos DB and Google Cloud Datastore can also be used for the same.
What is Serverless Batch Processing?
In this part, we will see how we can do batch processing using it. We can have various use cases where we need Batch Processing of Data.- Define an ETL Job in which Data needs to be pulled from any OLTP Database like Amazon RDS or any other database, run transformations, and needs to be stored into our Data Lake ( like S3, Google Cloud Storage, Azure Storage ) or Data Warehouse directly ( like Redshift, BigTable or Azure SQL Data Warehouse ).
- Define an ETL Job in which Data needs to be pulled from Data Lake and need to run transformations and move the data to Data Warehouse.
What is Serverless Databases?
The concept of it is also becoming popular in databases also. Amazon has launched its Aurora Serverless Database which redefines the way we use our databases. We already used a lot of ways to optimize the read/write capabilities of databases like using Cache frequent queries to optimize the reads, using compression techniques to optimize the storage, etc.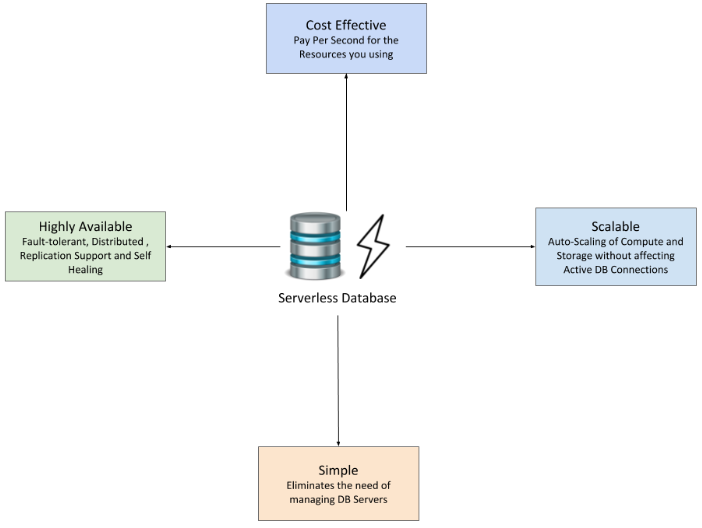 But it focuses on decoupling the Copute Nodes and Storage Nodes. And Not only Decoupling but It should also be managed automatically means auto-startup/shutting down of database servers, scaling up / down according to the workload on database servers. Also, Costing should also be based on usage like Amazon Aurora do it on a per-second basis. So It means you don’t have to pay for database server infra all the time. You have to pay only for the time when the database was in an inactive state.
But it focuses on decoupling the Copute Nodes and Storage Nodes. And Not only Decoupling but It should also be managed automatically means auto-startup/shutting down of database servers, scaling up / down according to the workload on database servers. Also, Costing should also be based on usage like Amazon Aurora do it on a per-second basis. So It means you don’t have to pay for database server infra all the time. You have to pay only for the time when the database was in an inactive state.The technology can eliminate the need for infrastructure and management, but not the servers. Source- Guide to Serverless Computing
What is Serverless Data Lake?
It provides huge storage for any kind of data, which has the ability to shaft any virtual tasks.Serverless Data Lake Architecture
It refers to storage where we have data in its natural state. The process involved in building Data Lake:Data Ingestion
Able to ingest any data from different types of Data Sources ( Batch and Streaming ) and should be scalable to handle any amount of data and costing should only be for the execution time of Data Migration Jobs. Example: AWS Glue for Batch Sources and Kinesis Firehose & Kinesis Streams with AWS Lambda for Streaming Sources.Data Storage
Should be scalable to store multi-years data at low cost and also file type constraint should not be there. Example: AWS S3, Google Cloud Storage, Azure StorageData Catalogue
Catalog Service which updates continuously as we receive data in our Data Lake. We can enable Data Discovery only if we have Data Catalog which keeps updated metadata about it. Example: AWS Glue Data Catalogue Service, Apache Atlas, Azure Data CatalogData Discovery/Searching
Querying Engine for exploring the Data Lake and it should also be scalable up to thousands & more queries and charge only when the query is executed. While Migrating data from our operational systems to it, There are two types of approaches.- ETL (Extract, Transform and Load )
- ELT (Extract, Load, and Transform )
ETL vs ELT
In the ETL Approach, Generally, Data is extracted from the Data Source using a Data Processing Platform like Spark and then data is transformed and Then it loaded into Data Warehouse. But in ELT Approach, Data is extracted and directly loaded into it, and Then Data Transformations Jobs are defined, and transformed data gets loaded into Data Warehouse. As we know that in the world of Big Data, there are different types of Data Sources like REST API, Databases, File Systems, Data Streams, etc and they have different varieties of Data like JSON, Avro, Binary Files ( EBCDIC), Parquet, etc.
So There can be use cases, in which we just want to load data as it is into our Data Lake because we can define transformations on some data after exploration only. So, That’s Why the ELT approach is better than the ETL approach in which Data is loaded as it is into it and Then Data Scientists use various Data Wrangling tools to explore and wrangle the data and Then define the transformations and then it got committed/loaded into Data Warehouse.
Azure Computing helps the user build a serverless app and helps the developer focus only on business goals and make an efficient app. Source: Azure Computing
Building a Serverless Analytics Solution
As we have explained How to build a Data Lake using Server Architecture, Now Let’s see how we can build Analytics Solution using its Architecture. Its analytics can be used for various purposes :- Data Scientists need to explore the data in it.
- The business Team needs to analyze their business in various prospects from Data Lake.
- Machine Learning and Deep Learning Models are also got offline trained by reading new data from it periodically.
- Should have a Data Discovery Service which should charge us only for the execution time of queries.
- Should be scalable for unlimited queries over Data Lake so that Concurrently multiple users can discover it simultaneously.
Serverless Analytics Example
Now Let’s say we have a Data Lake on our Cold Storage like S3 or HDFS or Glusterfs using AWS Glue or any other Data Ingestion Platform. Now We want to run SQL queries on any amount of data, and there can be multiple users who can run complex analytical queries on the data. We need a query engine that can run multiple queries with consistent performance. Just Imagine, We have a spark cluster deployed with some 100 Gigs of RAM, and we are using Spark Thrift Server to query over the data, and we have integrated this thrift server with our REST API, and our BI(Business Intelligence) team is using that dashboard.
So, Here is the point, We need a Query Engine that can serve as many users as per requirement without any degradation in performance. We can build this type of Interactive Queries Platform using AWS Serverless Services like Amazon S3, Athena, and QuickSight. Amazon S3 offers unlimited space, and Athena offers a querying engine, and QuickSight allows us to serve concurrent users. For Reporting Services, We can use Amazon Athena too by scheduling them on AWS Cloud Dataflow. In Google Platforms, We can use Google BigQuery as Querying Service.

Serverless Microservices
The Microservices architecture allows our application to divide into logical parts which can be maintained independently. It eases and fastens the process of continuous deployment and automation testing. It also enables cross-language communication like Data Scientist uses R Language for his ML/DL Model Development. If he wants to access data, then he just needs to use another microservice architecture using API Gateway which can be developed in Scala, Python, etc.Cost Optimization
You will charge only for the execution time of microservice Serverless architecture, use by any type of client.Auto Scaling
Our Microservice will be automatically scale up according to its workload, So No need of the DevOps Team for monitoring the Resources.Focus Only on Code
Developers can just focus only on his code and no need to worry about the deployment part and other things. Earlier, When the developer is working on the code, then he has to take Load Factor into consideration as well due to deployments on servers. But now if your code is proper which can handle computations in a parallel way.Composition
Let’s say we have use case in which there is a microservice that is collecting stocks data from third-party API and saving it to our Data Lake and Let’s say Then it triggers a Kafka Event and There is another Spark Streaming MicroService which is continuously reading the Kafka events and will read the file from Cloud Storage and do transformations and persist the data to warehouse and trigger the Current Stocks microservice to update the latest stocks information of various companies. So This communication among MicroServices is called Composition. It simplifies the lifecycle of these types of microservice patterns by managing them independently.The flexibility of using various Cloud Platform
Various Cloud providers support Platforms like AWS Lambda, Google Cloud Function, Azure Functions, etc. So Developers have the flexibility of deploying their serverless function on different Cloud Platforms.Know When to Implement Serverless vs. Containers
As we know that Kubernetes is very popular nowadays as they provide Container-based Architecture for your Applications. But the question how we are going to take the decision over our Application Deployment on Serverless vs Container. Here are some points which are lacking in Platforms as compared to Containers:Stateless vs Stateful Apps
So Serverless Application is like decoupling all of the services which should run independently. So, it works best when we are following Stateless Architecture in which One microservice doesn’t depend upon the state of other microservice. However, in container-based applications, we can attach Persistence Storage with containers for the same. So, It's better to use both container and it together and deploy only those applications on it. Which are independent and need to access directly from outside. Otherwise, Go for Container-based architecture.Memory and Concurrency
We talked about auto-scaling of Resources like CPU and Memory in it like AWS Lambda, but AWS Lambda has some restrictions also on it. Maximum Memory we can allocate to our AWS Lambda Function is 1536 MB, and concurrency also varies according to your AWS region, it changes from 500 to 3000 requests per minute. But in the world of Containers, There are no such restrictions. We can enable the auto-scaling in Kubernetes and scale up/down our application according to any workload.Language Support
There is also a restriction of language support in Serverless Platforms like AWS Lambda. It only supports Node.js, Python, Java, Go, C#. Scala and other languages are not in support yet. So REST API developed in Scala using Akka and Play Framework are not yet supported on AWS Lambda.Control Level and Security
We have full control over our Infra, and we can allocate resources according to our workload. We can set fine-grained rules and policies on our application access. But in it, You have to trust on Serverless Platform for this. So, If security is a major concern for you and you want it very customized, then Containers are a good fit.Debugging, Testing, and Monitoring Flexibility
It offers Monitoring by cloud watch, and you can monitor some parameters like concurrent connections and memory usage, etc. But still, a Deep level of monitoring is not there like Average time is taken by request, and other performance metrics can’t be traced. Also we can’t do deep Debugging also in Cloud-based Functions. So, For those Applications, which need high performance then we have to think about our performance expectations before we use it.Cost-Effective
Containers are always in active mode with a minimum number of resources that are necessary for an application, and you have to pay for that infra. But in the case of it, In case of no usage, our container can completely shut down, and you have to pay only for the execution time of your Function. Serverless Container often uses cold start because the container shuts down in case of no usage. So it can take time to serve in that scenario.Code Once, Use Anywhere
Microservice allows engineers to add the resizing service to the code they’re working on with a simple API call.Serverless Computing is more beneficial for services with uneven or unpredictable traffic patterns with very high computing or large processing requirements. Source: Serverless Computing Applications
Use Cases of Serverless Architecture and Design Patterns
Now we will be discussing few use cases of its architecture which are handled more efficiently by Serverless Architectures.Event-driven data processing
We were working on decoding the EBCDIC files store on our S3 Buckets by an external application. So What we do earlier is deploy a Spark Job on our EMR Cluster which was listening to AWS SNS Notification Service and use the Cobol layout. To decode the EBCDIC to parquet format and perform some transformations and move it to our HDFS Storage. So We were always paying for EMR Cluster on per hour basis. So We use the same conversion and transformation logic in our AWS Lambda function and What it does is save our infra cost. We have to pay whenever we got any new EBCDIC file in our S3 Buckets.Serverless Web Applications
Let’s say we have a Web Application hosted on our On-Premises or Cloud Instance like EC2. Now we have to pay for the infra always on which REST API deployed. So, We can deploy our API as AWS Lambda functions. We will charge only whenever any traffic incurs or whenever that specific API call. Another benefit is we don’t have to worry about scalability as AWS Lambda. It is automatically scale up or down our APIs according to load on it.Mobile and Internet-of-Things applications
While working on various cases of IoT Analytics Platform, we choose AWS Lambda as our Data Processing and Transformation Service in which AWS Lambda is continuously consuming data from Kinesis Streams and perform the Data Cleaning, Transformations and Enrichment on the data and store it to Redshift and DynamoDB.Real-time Log Monitoring & Alerting
Using CloudTrail and CloudWatch, we enabled real-time log monitoring using AWS Lambda functions. In which we keep on consuming the log events using Cloud Watch which develops by CloudTrail. Then, after doing some parsing of logs, we are monitoring the metrics and check for any critical event and generate alerts. To our notification platforms like Slack, RocketChat, Email, etc. immediately in our AWS Lambda Function.Schedule our Everyday Tasks like Database BackUp
We use a combination of Amazon SNS Service and AWS Lambda Function to automate our Database Backup Jobs. Now, the plus point is we have to pay for only that time whenever our database backup job initiated.An application that helps to understand the huge volume of data generated connected IoT devices. Click to explore about our, IoT Analytics Platform for Real-Time Data Ingestion
Serverless Architectures On Different Cloud and On-Premises
There are also various platforms in the market which are providing Serverless Services for various components of our Big Data Analytics Stack.Amazon Web Services
AWS offer the below platforms
Amazon S3
Cloud-Scale Storage is the critical point for the success of any Big Data Platform. Amazon S3 is warm storage, and it is very cheap, and We don’t have to worry about its scalability of size. So We only have to pay for what we store in it. We don’t need to worry about the cost of infra where we need to deploy our storage. We often use Amazon S3 as Data Lake, and Batch Queries in our Analytics Platform we can run Ad hoc Analytical queries using Spark or Presto over it. Also, We define our transformations jobs in Spark which checks for new data in S3 Buckets periodically and transform it and store it to our Data Warehouse.Amazon Glacier
Amazon Glacier is also cheaper storage than Amazon S3. We can use it for achieving our data which can access rarely. So Batch Queries which needs to be run weekly or monthly, we use Amazon Glacier for that.Amazon DynamoDB
Amazon DynamoDB is a powerful NoSQL Datastore which built upon it, and it provides consistent single-digit millisecond latency at scale. Here also, pay for whenever you perform any read/write request. We use Amazon DynamoDB as Serving Layer for Web and Mobile Apps which need consistent read and write speed.AWS Lambda
AWS Lambda is a compelling service launched by AWS and based upon Serverless Architecture where we can deploy our code, and AWS Lambda functions and Backend Services manage it. It scales up/down according to the incoming rate of events, and it can trigger from any Web or Mobile App. So it provides seamless integrations with almost every type of client. Moreover, We will charge 100ms of our execution time. We deploy our REST APIs on AWS Lambda using its support for Spring Framework in Java. It also supports Node js, Python, and C# language too. Another use case we mostly use this AWS Lambda is for Notification Service for our Real-time Log Monitoring. We ingest real-time logs from Kafka Streams and process them in Lambda Functions and generate alerts. To Slack, Rocket-Chat, email, etc. if any critical situation detected from logs.Interactive Query Service
Amazon Athena is a very powerful querying service launched by AWS, and we can directly query our S3 data using Standard SQL. Moreover, yes, it is as It can scales up/down as our query requirement, and We have to pay per query. Amazon Athena also supports various formats also like Parquet, Avro, JSON, CSV, etc.AWS Glue
AWS Glue is a ETL Service launched by AWS recently, and it is under preview mode and Glue internally Spark as execution Engine. Moreover, Glue is capable of handling a massive amount of data. We can transform it seamlessly and define the targets like S3, redshift, etc. Glue also allows us to get the ETL script in python or scala language. We can add our transformation logic in it. Then Upload it back to Glue and then just let Glue do the things for you.Fission Big Data
Fission has the ability to host functions on any Kubernetes cluster, whether it is on-premises or on the cloud.OpenWhisk
OpenWhisk is also similar like fission that can host any function either on the cloud or on-premises.Google Serverless
Google cloud offerings are listed below:
Cloud Function
Google Cloud Service in which we can define our business logic to ingest data from any data source like Cloud Pub/Sub and perform Data Transformations on the fly and persist it Into our Data Warehouse like Google Big Query or again to Real-time Data Streams like Google PUB/SUB.Cloud Datastore
NoSQL Service provided by Google Cloud, and it follows architecture, and its similar to AWS DynamoDB.Cloud Storage
Object Storage service like AWS S3 which is highly scalable and cost-effective.Cloud DataFlow
Serverless Stream and Batch Data processing Service provided by Google Cloud in which we can define our Data Ingestion, Processing & Storage Logic using Beam API's and deploy it on Google Cloud Dataflow.Google BigQuery
Google BigQuery is a data warehouse service, and Google Cloud Services fully manage it.Cloud ML Engine
Google Cloud also has a Cloud ML Engine to provide serverless machine learning services. Which scales automatically as per Google hardware, i.e., Tensor Processing Units.Oracle Serverless
Oracle has also launched an Oracle Fn which is a container-based platform that we can deploy at any cloud or on-premise. We can import our Lambda functions into it and define hot functions for high-performance applications.- It allows us to deploy them using our orchestration tools like Kubernetes, Docker, Mesosphere.
- It provides Smart Load Balancer which routes the data to our API according to the traffic load.
- Oracle also provides us the ability to extend it and add our custom add-ons to it according to our requirements.
Azure Serverless
Azure Cloud service has also launched its compute service called Azure Function Service. Which we can use in various ways to satisfy our needs cost-effectively. It is very much similar to AWS Lambda or Google Cloud Function.The purpose of cognitive computing is to create the frame for computing such that complex problems are solved easily without human intervention. Click to explore about our, Real Time Anomaly Detection for Cognitive Intelligence
What are the open source big data serverless framework?
Big Data Serverless open source framework are listed below:
Open Faas with Kubernetes
OpenFass (Function as a Service) is a framework for building serverless functions on the top of containers (with docker and Kubernetes). With the help of OpenFass, it is easy to turn anything into a function. That runs on Linux or windows through Docker or Kubernetes. It provides a built-in functionality such as self-healing infrastructure, auto-scaling, and the ability to control every aspect of the cluster. You can also explore it with Openfaas and Java in this blog.
Conclusion
We know that we cannot define a fixed number of resources for our platform because we never know that when the velocity/size of data can change. So Our Big Data Platforms must be able to tackle any of these situations, and it is a very high solution to thinking about these problems.
- Read more about Real-Time Big Data Integration Solutions
- Explore How to Build an Analytics Stack on GCP



























