
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
The rise of SAAS Data platforms has allowed users and admins to create on-demand resources such as compute, RAM, and GPU. While this is beneficial, it can also lead to situations where costs spiral out of control. That is why it is crucial to monitor costs proactively; a practice known as "FinOps."
FinOps, short for Financial Operations, is not just about managing cloud finances. It also promotes a cultural shift within the organisation, fostering collaboration between finance, engineering, and business teams. One key aspect of FinOps is shared responsibility. Another important aspect is making data-driven decisions. By actively monitoring costs, organisations can identify areas for optimisation and make informed choices.
The goal of FinOps is to achieve a balance between cost optimisation and meeting business needs. It is about managing your cloud finances effectively to catch waste early, optimise resource utilisation, stay within budget, and make informed decisions.
Databricks and FinOps Phases
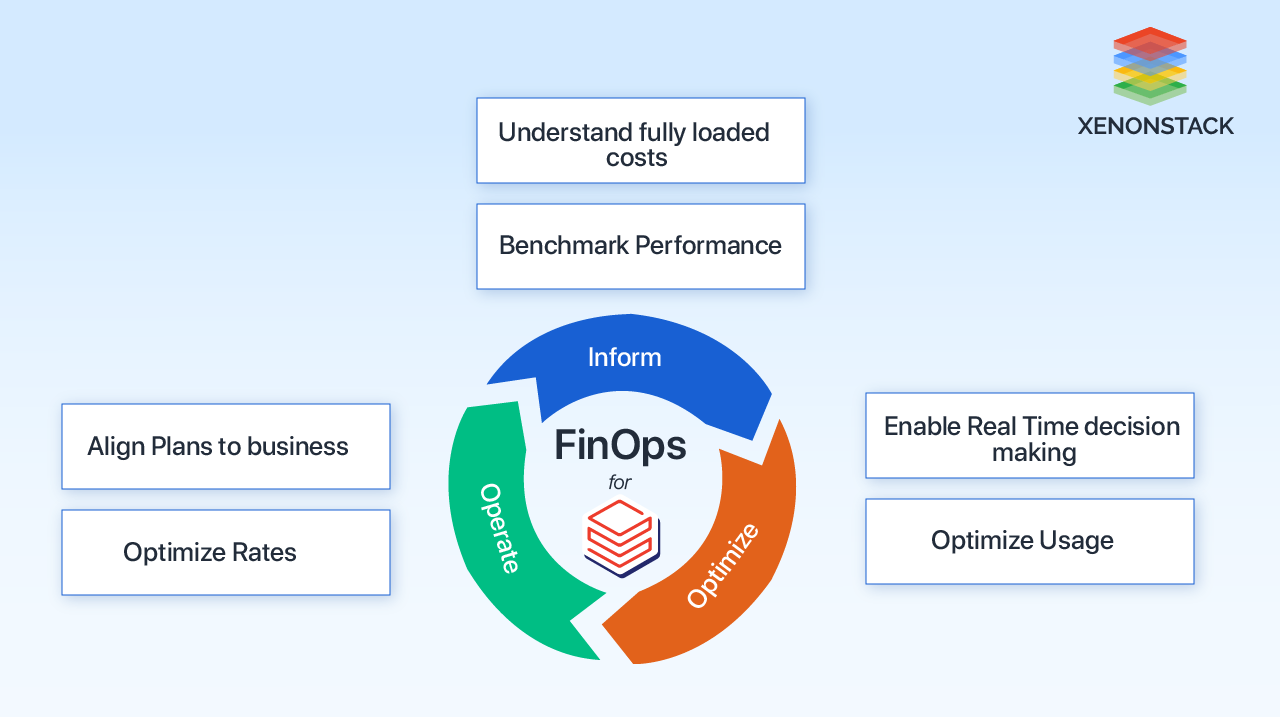
There are three phases of FinOps, namely Inform, Optimise, and Operate, which can be applied to Databricks, too. These phases allow organizations to gain visibility into costs, optimize resource usage, and align their plans with business objectives.
-
During the Inform phase of FinOps in Databricks, organisations need to gather and analyse data to gain a comprehensive understanding of fully loaded costs and benchmark performance.
This involves identifying all the costs associated with running workloads on Databricks, including compute, storage, and data transfer costs.
-
In the Optimise phase, the focus shifts toward enabling real-time decision-making and optimising usage. This involves implementing cost optimisation strategies such as rightsizing instances, leveraging spot instances, and optimising data storage.
-
Lastly, in the Operate phase, organisations align their plans with the business objectives and optimise rates. This involves negotiating contracts with Databricks and other cloud service providers to ensure favourable pricing terms.
FinOps in Databricks
To effectively manage expenses in a Databricks workspace, consider the following strategies:
-
Understand and verify DBUS: DBUS represent computational resource usage on Databricks. The number of DBUS used depends on the cluster's node count and VM instance capabilities. Different cloud providers have different DBU rates, so verify the rates for your specific cloud service.
-
Implement Cluster Policies: Use cluster policies to control DBU usage. Set parameters such as maximum node count, instance types, and auto-termination rules to optimise resource allocation and prevent unnecessary expenses.
-
Monitor Compute Costs: Track compute consumption, including VM expenses. Identify underutilised or overutilised resources and adjust cluster sizes accordingly. Consider using auto-scaling to adjust cluster capacity based on workload requirements dynamically.
-
Manage Storage Costs: Monitor storage expenses within the workspace. Understand data growth patterns and optimise storage distribution. Use managed storage solutions provided by the cloud service.
-
Regular Evaluation and Monitoring: Continuously assess DBU, compute, and storage utilisation. Look for opportunities to reduce costs and adjust resource allocation as needed. Ensure that the workspace operates within budget constraints.
Understanding DBU
The fundamental unit of consumption is a Databricks Unit (DBU). The number of DBUS consumed, except SQL Warehouses, is determined by the number of nodes and the computational capabilities of the underlying VM instance types that form the respective cluster. In the case of SQL Warehouses, the DBU rate is the cumulative sum of the DBU rates of the clusters comprising the endpoint. At an elevated level, each cloud provider will have slightly different DBU rates for similar clusters due to variations in node types across clouds. However, the Databricks website provides DBU calculators for each supported cloud provider (AWS | Azure | GCP).
Cluster Policies: Managing Costs
An admin can use a cluster policy to control configurations for newly created clusters. These policies can be assigned to individual users or groups. By default, all users can create clusters without restrictions, but caution should be exercised to prevent excessive costs.
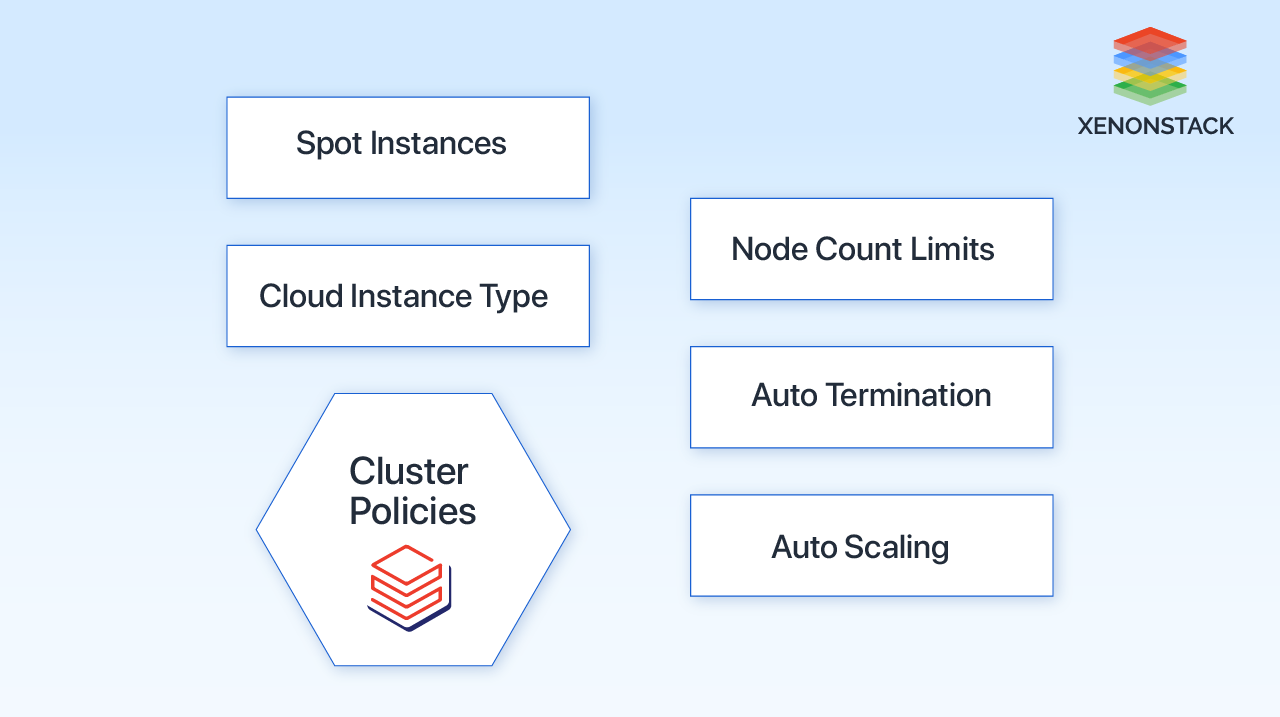
Policies limit configuration settings. This can be achieved by setting specific values, defining value ranges using regex, or allowing an open default value. These policies also restrict the number of DBUS (Database Units) consumed by a cluster, allowing control over settings such as VM instance types, maximum DBUS per hour, and workload type.
Node count limits, auto-termination, and auto-scaling
Clusters that are underutilised or inactive are a frequent problem with computing expenses. Databricks provides solutions to address these issues dynamically without requiring direct user intervention. By implementing auto-scaling and auto-termination functionalities through policies, users can optimise their computational resources without hindering access.
Node count restrictions and automatic scaling policies can be enforced to ensure the activation of auto-scaling capability with a minimum number of worker nodes.
Also, when setting up a cluster on the Databricks platform, users can configure the auto-termination time attribute. This attribute automatically shuts down the cluster after a specified period of inactivity. Inactivity is determined by the absence of any activity related to Spark jobs, Structured Streaming, or JDBC calls.
Spot Instances and Cloud instance types
When configuring a cluster, you can choose VM instances for the driver and worker nodes, each with its own DBUS rate. To simplify instance management, you can use the "allowlist" or "fixed" type to restrict usage to a single type. For smaller data workloads, choosing lower memory instance types is recommended. GPU clusters are ideal for training deep learning models due to their higher DBU requirements, but it is essential to balance the limitations of instance types.
If a team needs more resources than policy restrictions allow, the job may take longer and incur higher costs. Spot instances are discounted VMS offered by cloud providers. However, they can be reclaimed with minimal notice (2 minutes for AWS and 30 seconds for Azure and GCP).
Efficient Storage Attribution
Databricks offers a significant advantage by seamlessly integrating with cost-effective cloud storage options such as ADLS Gen2 on Azure, S3 on AWS, or GCS on GCP. This becomes particularly beneficial when utilising the Delta Lake format, as it facilitates data governance for a complex storage layer and enhances performance when combined with Databricks.
One common mistake in storage optimisation is implementing lifecycle management effectively. While removing outdated objects from your cloud storage is recommended, it is crucial to synchronise this process with your Delta Vacuum cycle. If your storage lifecycle removes objects before Delta can vacuum them, it may result in table disruptions. Therefore, it is essential to thoroughly test any lifecycle policies on non-production data before implementing them extensively.
Networking Optimization
Data in Databricks can come from various sources, but the main way to save bandwidth is by writing to storage layers like S3 or ADLS. To reduce network costs, deploy Databricks workspaces in the same region as your data and consider regional workspaces if needed. For AWS customers using a VPC, you can decrease networking costs using VPC Endpoints. These allow VPC and AWS services to connect without an Internet Gateway or a NAT Device. Gateway endpoints connect to S3 and Dynamodb, while interface endpoints lower costs for compute instances connecting to the Databricks control plane. These endpoints are available when using Secure Cluster Connectivity.
Leveraging Serverless compute
For analytics workloads, one may want to consider utilising an SQL Warehouse with the Serverless option enabled. With Serverless SQL, Databricks manages a pool of compute instances that can be allocated to a user as needed. This means that Databricks takes care of the costs associated with the underlying cases rather than having separate charges for DBU computing and cloud computing. Serverless offers a cost advantage by providing immediate compute resources for query execution, reducing idle costs from underutilised clusters.
Monitoring Usage
Databricks offers tools for administrators to monitor costs, such as the Account Console for an overview of usage and the Budgets API for active notifications when budgets are exceeded. The console's usage page allows visualisation of consumption by DBU or Dollar amount, with options to group by workspace or SKUS. The upcoming feature of Budgets API simplifies budgeting by sending notifications when budget thresholds are reached, based on custom timeframes and filters.
The emergence of SAAS Data platforms has led to on-demand resource provisioning, which can sometimes result in unmanageable expenses, necessitating proactive cost monitoring, known as "FinOps." FinOps fosters collaboration between finance, engineering, and business teams, emphasizing shared responsibility and data-driven decision-making. Its three phases - Inform, Optimise, and Operate - apply to Databricks too. Cluster policies are crucial for controlling configurations and optimising computational resources, enabling auto-scaling and auto-termination functionalities to prevent excessive costs.



























