
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introducing Hadoop - Delta Lake Migration
It is one of the fastest-growing advancements that have revolutionized IT services. It is because of their reliability and easiness to use that they are widely spread across the market. What caused this migration from it to Delta Lake? What Apache Hadoop offered? Why is it superior to it? Let's find out.What is Hadoop?
It is an open-source software platform managed by Apache Software Foundation. It is used to manage and store large data sets at a low cost and with great efficiency.Managed by the Apache Software Foundation, is at its heart a framework and file system that manages distributed computing. Source: Forbes, an American business magazineIt has two main parts - a framework used to process the data and a distributed file system used to store it. It uses Apache Hive to convert queries given by users into map-reduce jobs. As map-reduce is complex and works as batch processing (one-job-at-a-time), Hadoop tends to be used more as a data warehousing than a data analysis tool. It also uses HDFS to maintain and manage all the records - file system management across the cluster.
Why it is important?
It hit its peak popularity as a search term in summer 2015. Reasons are many.Flexible
It manages different Big Data types, whether structured or unstructured or any other kind of data. It is quite simple, relevant, and schema-less. It supports any language and works on almost any kind of operating system provided.Scalable
It is a scalable platform. Users can easily add nodes without even altering the data format or anything related to the existing applications. It is fault-tolerant, so even if a node stops working for some reason, it automatically reallocates work to another data location and keeps the work in progress.Data Economy
It is like a dam, as it harnesses the flow of an unlimited amount of data and generates much power in the form of required/necessary information.Robust EcoSystem
It has quite a rich ecosystem. Its ecosystem consists of various related projects such as MapReduce, Apache Hbase, Apache Zookeeper, HCatalog, Hive, Apache Pig, and many more. This allows Hadoop to deliver a vast spectrum of services.Cost-Effective
It helps save cost by computing parallelly, resulting in a substantial reduction in storage cost per terabyte.What are the challenges with its architecture?
Migration from Hadoop takes place because of a variety of reasons. Following are the common reasons why migration’s necessity comes up:Poor Data Reliability and Scalability
Data scalability issues with it clusters are common. Users were facing difficulty scale up for research purposes and scale down to reduce costs, which affected the team's productivity.Cost of Time and Resource
Excessive operational burdens due to Hadoop got common. It required time and headcount required to maintain, patch, and upgrade a complicated Hadoop system. Time spent in configuring the system went high for many users.Blocked Projects
Data being stuck in different silos, some in it and others in HPC clusters, hindered important deep learning projects.Unsupportive Service
Core Hadoop services like YARN and HDFS were not designed for cloud-native environments.Run Time Quality Issues
Performance and Reliability at scale were missing in data lakes built on the Hadoop stack.What is Delta Lake?
It is an open-source storage layer that helps bring reliability to the data lakes. It provides ACID transactions, unifies streaming and batch data processing, and scalable metadata handling. It runs on top of the existing data lake and is fully compatible with Apache Spark's APIs. Get to know about Apache Spark Architecture here.What Delta Lake has to offer?
Experience suggests that it makes data consistent by providing ACID transactions on Spark. This ensures that readers see only consistent. It also supports update, merge, and delete operations to enable complex use cases. It is compatible with Apache Spark APIs. Developers can easily integrate it into their existing spark pipelines with minimum changes. It can handle scalable metadata. This gives spark distributed processing power leverage to handle all the metadata for a huge data range to many petabytes with billions of files at ease. The table in it acts as a source and sink for both batch and stream processing.
Delta lake automatically handles any schema variations to prevent any bad record from inserting during ingestion. Users can easily rollback, see full historical audit trails, and reproduce machine learning experiments with data versioning. It can easily be integrated with other big data engines like Apache Presto and Apache Hive.
Know about Geospatial Analytics using Presto and Hive here.
Why to choose Delta Lake?
It is an open-source that brings new capabilities of transactions, version control, indexing, and many more to your data lakes. Delta lake provides snapshot isolation that helps to use read/write operations concurrently. This results in efficient insert, update, deletes, and rollback capabilities. It helps engineers to build efficient pipelines for their data. It helps upcoming the challenges faced by data lakes like unsafe writes, orphan data, no schematic by bringing various features like ACID transactions. Being reliable, efficient, easy to use, it is a layer that ensures data quality.Phases of Migration from Hadoop to Delta Lake
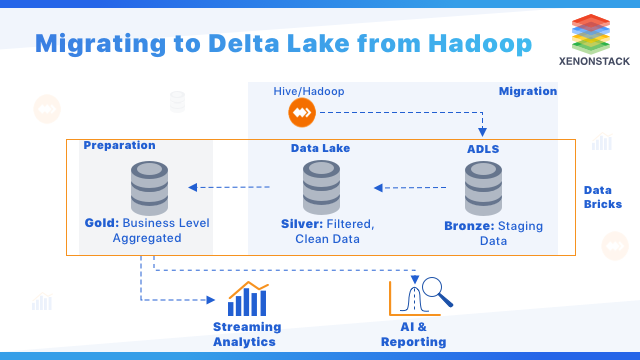 Migration from it has been a common theme. What led to it? What after the migration? Go ahead for the answers.
Migration from it has been a common theme. What led to it? What after the migration? Go ahead for the answers.
Frowning Hadoop users
Its users usually get frowned upon by the traditional problems of data gravity. Is there an application that assumes local, ready, and fast access to an on-premises data lake built on HDFS? Building an application away from that data becomes a bit challenging as it requires building additional workflows to copy or access data from on-premises data lake manually.Hadoop migration with Databricks and WANdisco
To overcome the challenges, Databricks and WANdisco got together to provide the solution, named LiveAnalytics. It takes the help of WANdisco's platform to migrate and replicate the largest datasets to Databricks and Delta Lake. One can use WANdisco’s technology to bring their respective data lake to Databricks. It will provide native support for Databricks.Hadoop to Cloud Migration Principles
Listed below are certain principles for its implementation.- Managing Complexity and Scale: Metadata movement, Workload Migration, Data Center Migration
- Manage Quality and Risk: Methodology, Project Plans, Timelines, Technology Mappings
- Manage Cost and Time: Partners and Professional Services bringing experience and training
Pondering Hadoop - Delta Lake Migration
The following points have proven to be valid while thinking of it:- One can only use it as a part of Databricks Ecosystem.
- It does not support transactions that involve multi-table and does not support foreign keys either.
- It is only available with AWS Serverless Computing and Azure Serverless Computing, but not with GCP Serverless Computing.
- Atomicity is attained using transaction logs, which are only available through Databricks.



