
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)

What is Amazon Glue AWS?
AWS Glue is a Serverless ETL (Extract, Transform, Load) service which makes it effortless for clients to construct and load their data for analytics. ETL service makes our data movable between various data sources. AWS Management Console is used to create and run ETL job script with just a few clicks. AWS Glue points to the data stored on AWS, finds the data, and stores metadata in the AWS Glue Data Catalog. Once the metadata is cataloged, your data can be searchable and available for ETL.A process to extract the data from Homogeneous or Heterogeneous data source then cleansed, enrich and Transform the data. Click to explore about, Continuous ETL and Serverless Solutions
Why is Serverless Important?
AWS provides the capability to focus more on code than to think about where my code will run. All the infrastructure set up is handled by third party services on the cloud. Data is stored on Amazon S3 data stores and resides in the cloud from where we can store or retrieve data anytime and anywhere. It doesn’t mean that you don’t have servers. Indeed, you don’t have to set up the infrastructure of servers or buy them.What is AWS Data Lake?
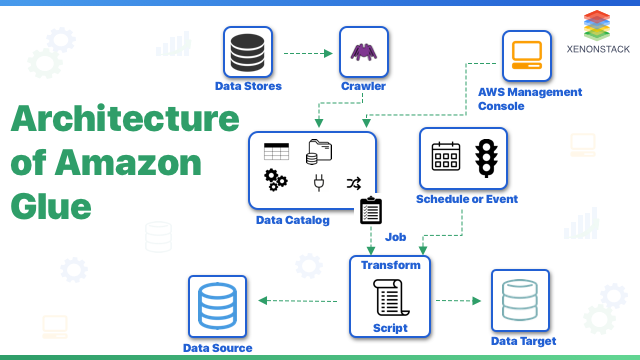
It acts as data storage that stores data on the cloud. Data can be located in the AWS Data Lake with the help of AWS Glue, which helps to maintain the catalog of the data.What is the architecture of Amazon Glue?
The architecture of Amazon Glue AWS comprises of below mentioned bulleted points that are needed to take note of:- AWS Glue provides jobs to effectuate the work that is required to extract, transform, and load data from a data source to a data target.
- AWS Glue Data Catalog is populated with metadata with the help of Crawlers. Crawlers act as a relationship between data stores and Data Catalog.
- Data Catalog also contains other metadata, which is required to create an ETL job script.
- ETL script generated by AWS Glue is used to transform your data.
- Jobs can be run on-demand or can be scheduled at specified time intervals.
- When the job runs, ETL script extracts data from sources, transforms the data, and load it into the data target.
- Script runs in Apache Spark environment present in AWS Glue.
The Terminology of AWS Glue
Following are certain terminologies to be kept in mind while operating Amazon Glue AWS:AWS Glue Data Catalog
It acts as a central metadata repository. It holds the data references of data sources and data targets used in ETL jobs. By cataloging this data, you can create Data Warehouse or Data Lake. It contains the index to location and schema of your data present in data stores. Metadata tables are stored in the data catalog, which is written to a container of tables in the Data Catalog.Classifier
It tells the schema of the data, which means a description of the data. AWS Glue provide classifiers for different file types: CSV, XML, JSON etc.Connection
Properties are needed to connect the Data Catalog to a specific data store. If you are using the S3 data store as your data source and data target, then there is no need to create a connection.Crawler
It is used to populate the AWS Glue Data Catalog with metadata. It populates the table definitions in the data catalog by pointing the crawler at a data store. Crawlers can also be used to convert semi-structured data into a relational schema.Database
It contains tables that define data from many different data stores. It is also responsible for arranging tables into separate categories.Serverless Cloud Computing enables self-service provisioning and management of Servers. Click to explore about, Serverless Solutions and Architecture for Data Lake
Data Store, Data Source and Data Target
Storing up the data is done in a repository called Data Store. Data Source is the same as Data Store, but it is used as input data for transformations. The transformation of data is written to a Data Target, which is the Data Store.Dynamic Frame
It is similar to Data Frames in Apache Spark, but Data Frames have the limitation of ETL operations. To overcome this limitation, Dynamic Frames are widely used in AWS Glue. Each record is self-describing and has a wide variety of advanced transformation operations for data cleaning and ETL. Data Frames can be converted to Dynamic Frame and vice versa.Script
Scripts like Pyspark or Scala are written and thereby used to extract the data from the data sources, transform it, and then insert the transformed data into the data target data store.Job
It works with ETL (Extract, Transform, Load) scripts. Jobs can be run only on demand or at scheduled time intervals.Table
It contains metadata definition which represents your data. Data can be of any type like S3 files, amazon RD service, etc.What is Amazon glue used for?
AWS Glue allows you to construct your data for analytics, which provides a clear glimpse of data, clean it, and catalog it properly. Some uses of AWS Glue are below:- Less Hassle
- Cost-Effective
- More Power
The data lake is Storing petabytes of data on a repository system in its natural form without any transformation, analytics or any data left behind on data source. Click to explore about, Azure Data Lake Analytics
How does Amazon Glue work?
Follow 12 simple steps given below to ease up your working with Amazon Glue:
- Step 1: Create an account of the AWS Management Console and sign in.
- Step 2: There is no need to create the infrastructure for an ETL Job as AWS Glue does it for you automatically.
- Step 3: AWS Glue console connects the other AWS Services into managed applications, which is beneficial for you to focus on creating and monitoring your ETL work.
- Step 4: Data stored in AWS is pointed by AWS Glue, which will discover your data and creates the schema of data, and stores the metadata in the AWS Glue Data Catalog.
- Step 5: Once the metadata is cataloged, your data is immediately searchable and available for ETL.
- Step 6: There is no need to create an infrastructure for an ETL tool because AWS Glue does it automatically for you.
- Step 7: Crawlers are defined to read the data from the data stores and then populate the AWS Glue Data Catalog with the metadata.
- Step 8: Data Catalog also contains the metadata required to create the ETL job. The data catalog has an index that points to the location and schema of data.
- Step 9: AWS Glue automatically generates the programming logic ETL script that can perform the transformation.
- Step 10: AWS Glue can create the script automatically or you can write the script manually.
- Step 11: ETL job can be run on-demand or at a specific scheduled time interval.
- Step 12: It runs job in Apache Spark Serverless environment.
Why Adopting AWS Glue Matters?
Reasons to adopt AWS Glue are manifold:- We can reliably schedule data pipelines from time to time.
- The trigger-based pipeline runs.
- All the AWS features are supported such as IAM, service roles, etc.
- Bare minimum coding experience required to get started with making data pipelines.
Conclusion
Amazon Glue AWS can be regarded as the best and the fastest among its peers when it comes to Serverless ETL service, supporting vast varieties of Datastores like Amazon S3, Amazon RDS, Amazon Redshift, Amazon Dynamo DB, JDBC. Go ahead and experience the vastness of Amazon Glue and rule the ETL service.


























