
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is Natural Language Processing?
Natural Language Processing involves the ability of machines to understand and derive meaning from human languages.
Machines can understand human language. It could be in the form of speech/text. It uses ML (Machine Learning) to meet the objective of Artificial Intelligence. The ultimate goal is to bridge how people communicate and what computers can understand.
If we mathematically represent it contains the following terms:
-
NLP: NLP (Natural Language Processing) is in charge of processes such as decisions and actions.
-
NLU: NLU (Natural Language Understanding) understands the meaning of the text.
-
NLG: NLG (Natural Language Generation) creates the human language text from the structured data that the system generates to answer.
How many types are there?
There are three different levels of linguistic analysis-
-
Syntax - What part of the given text is grammatically right?
-
Semantics - What is the meaning of the given text?
-
Pragmatics - What is the purpose of the text?
It is a subset technique of Artificial Intelligence which is used to narrow the communication gap between the Computer and Human. Click to explore about, Evolution and Future of Natural Language ProcessingNLP deals with different aspects of language, such as:
-
Phonology - It is a systematic organization of sounds in language.
-
Morphology is the study of word formation and their relationship with each other.
-
Distributional - It employs large-scale statistical tactics of Machine Learning and Deep Learning.
-
Frame-Based—The sentences that are syntactically different but semantically the same are represented inside the data structure (frame) for the stereotyped situation.
-
Theoretical— This approach builds on the idea that sentences refer to the real world (the sky is blue) and that parts of a sentence can be combined to represent the whole meaning.
-
Interactive Learning—This involves a pragmatic approach, and the user is responsible for teaching the computer to learn the language step by step in an interactive learning environment.
Importance of its Applications
With NLP, it is possible to perform tasks like Automated Speech and Text Writing in less time. Due to significant data (text), why not use the computer's untiring willingness and ability to run several algorithms to perform tasks quickly? These tasks include other NLP applications like Automatic Summarization (to generate a summary of a given text) and Machine Translation (translation of one language into another.
Techniques for Natural Language Processing?
In case the text is composed of speech, the speech-to-text conversion is performed. The mechanism of Natural Language Processing involves two processes --
Natural Language Understanding
-
Natural Language Generation
Natural Language Understanding
NLU, or Natural Language Understanding, tries to understand the given text's meaning. The nature and structure of each word inside the text must be known for NLU. For understanding structure, NLU attempts to resolve the following ambiguity present in natural language --
Lexical Ambiguity - Words have multiple meanings
-
Syntactic Ambiguity - Sentence has multiple parse trees.
-
Semantic Ambiguity - Sentence having multiple meanings
-
Anaphoric Ambiguity - Phrase or word that is previously mentioned but has a different meaning.
Next, the meaning of each word is understood by using lexicons (vocabulary) and a set of grammatical rules. However, certain words have similar meanings (synonyms), and some words have more than one meaning (polysemy).
Natural Language Generation
It automatically produces text from structured data in a readable format with meaningful phrases and sentences. The problem of natural language generation is hard to deal with. It is a subset of NLP Natural language generation divided into three proposed stages -
-
Text Planning - Ordering of the primary content in structured data is done.
-
Sentence Planning - The sentences are combined with structured data to represent the flow of information.
-
Realization - Grammatically correct sentences are produced finally to represent text.
Text Mining vs Natural Language Processing
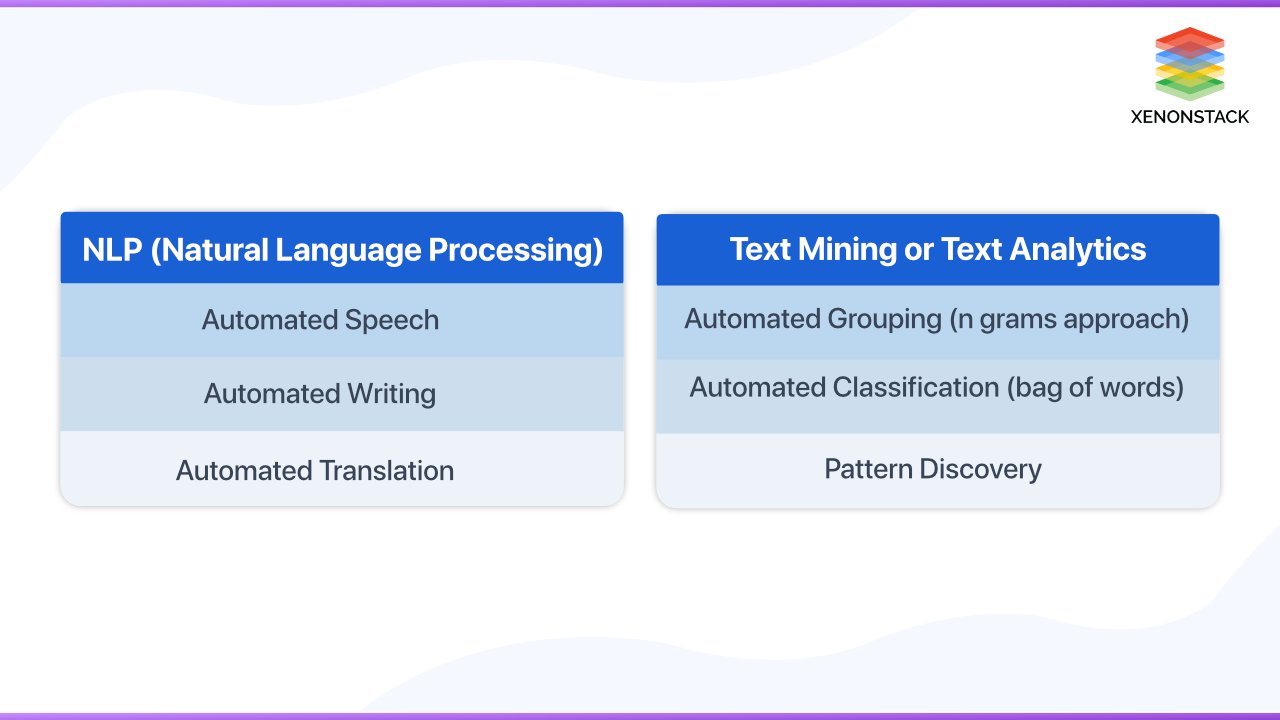 It is responsible for understanding the meaning and structure of a given text. Text Mining or Text Analytics extracts hidden information inside text data through pattern recognition. It is used to understand the meaning (semantics) of given text data, while text mining is used to understand the structure (syntax) of given text data. For example, I found my wallet near the bank. The task is to figure out at the end that ‘bank’ refers to a financial institute or ‘river bank.'
It is responsible for understanding the meaning and structure of a given text. Text Mining or Text Analytics extracts hidden information inside text data through pattern recognition. It is used to understand the meaning (semantics) of given text data, while text mining is used to understand the structure (syntax) of given text data. For example, I found my wallet near the bank. The task is to figure out at the end that ‘bank’ refers to a financial institute or ‘river bank.'
What is Big Data?
Big Data For Natural Language Processing
Around 80 % of the data is available in the raw form. Big Data comes from information stored in big organizations as well as enterprises. Examples include information about employees, company purchases and sale records, business transactions, the previous records of organizations, social media, etc. Though humans use ambiguous and unstructured language to be interpreted by computers, with the help of NLP, this large unstructured data can be harnessed for evolving patterns inside data to better know the information in it. It can solve significant problems in the business world by using Big Data. Be it any retail, healthcare, or financial institutions business.
Deep Learning For NLP Applications
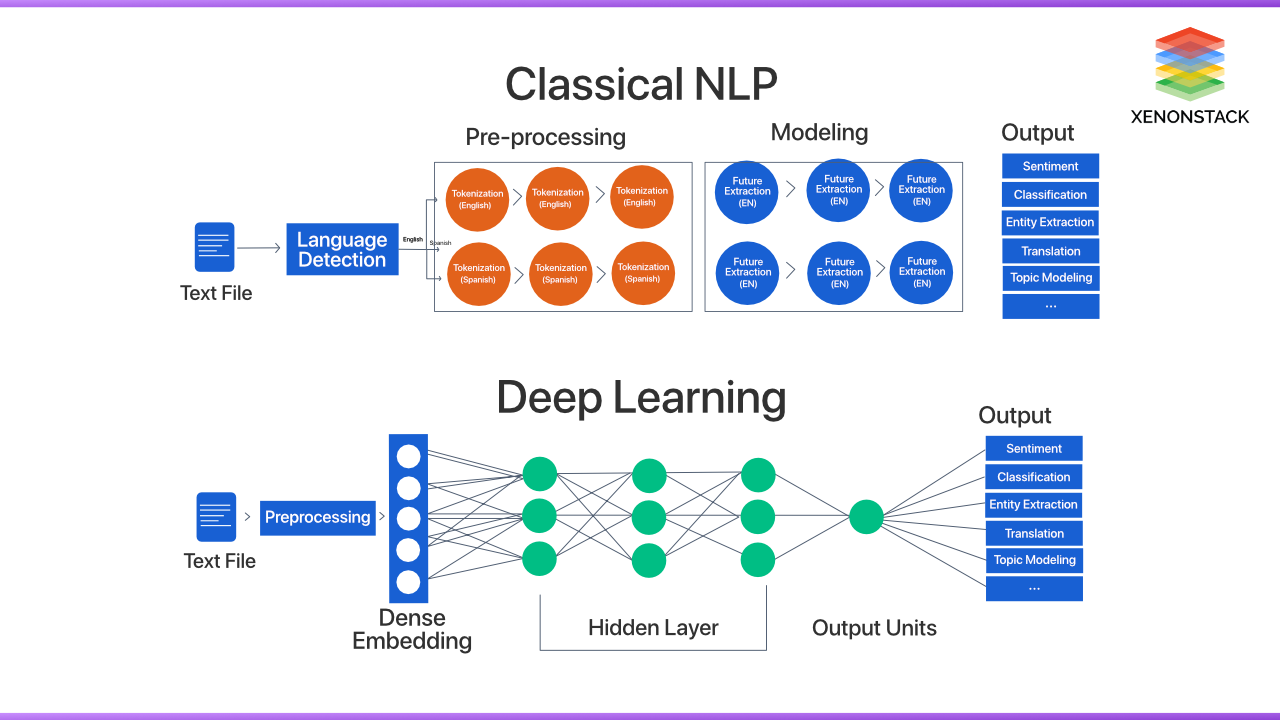
-
It uses a rule-based approach representing Words as ‘One-Hot’ encoded vectors.
-
The traditional method focuses on syntactic representation instead of semantic representation.
-
Bag of words - classification model is unable to distinguish certain contexts.
-
Expressibility - This quality describes how well a machine can approximate universal functions.
-
Trainability - How well and quickly a Deep Learning system can learn its problem.
-
Generalizability - How well can the machine predict data it has not been trained on?
Other capabilities also need to be considered in Deep Learning, such as Interpretability, modularity, transferability, latency, adversarial stability, and security. But these are the main ones.
Applications of Deep Learning in NLP
| Deep Learning Algorithms | NLP Usage |
|---|---|
|
Neural Network - NN (feed)
|
- Part-of-speech Tagging - Tokenization - Named Entity Recognition - Intent Extraction |
|
Recurrent Neural Networks -(RNN)
|
- Question Answering System - Image Captioning |
|
Recursive Neural Networks
|
- Parsing sentences - Paraphrase detection - Relation Classification |
|
Convolutional Neural Network -(CNN)
|
- Sentence/ Text classification - Relation extraction and classification - Spam detection - Categorization of search queries - Semantic relation extraction |
NLP for Log Analysis & Log Mining?
Its techniques are widely used in Log Analysis and Log Mining. Different techniques, such as tokenization, stemming, lemmatization, parsing, etc., convert log messages into structured form. Once logs are available in well-documented form, log analysis and mining are performed to extract useful information, and knowledge is discovered from the information. An example is an error log caused by a server failure.
A subset of Artificial Intelligence. It processes large amounts of human language data. It is an end to end process between the system and humans. Read Differences Between NLP, NLU, And NLG?
What are the best techniques for natural language processing?
Different methods used for performing log analysis are described belowPattern Recognition
One such technique involves comparing log messages with messages stored in a pattern book to filter out messages.
Text Normalization
Normalization of log messages is done to convert different messages into the same format. This is done when different log messages have different terminology, but the same interpretation comes from various sources like applications or operating systems.
Automated Text Classification & Tagging
Classification and tagging of different log messages involves ordering messages and tagging them with various keywords for later analysis.
Artificial Ignorance
It is a technique that uses Machine Learning Algorithms to discard uninteresting log messages. It is also used to detect anomalies in systems' ordinary workings.
Focus on helping computers to understand the way that humans speak and write. Read about Natural Processing Language in AI
Diving into Natural Language Processing Applications
It is a complex field and intersection of Artificial Intelligence, computational linguistics, and computer science.Getting started with Natural Language Processing
The user needs to import a file containing written text and then perform the following steps.| Technique | Example | Output |
|---|---|---|
| Sentence Segmentation | Mark met the president. He said:” Hi! What’s up -Alex?” | - Sentence 1 - Mark met the president. - Sentence 2 - He said: ”Hi! What’s up - Alex?” |
| Tokenization | My phone tries to ‘charge’ from the ‘discharging’ state. | - [My] [phone] [tries] [to] [‘] [charging] [‘][from] [‘][discharging] [‘] [state][.] |
| Stemming/Lemmatization | Drinking, Drank, Drunk | - Drink |
| Part-of-Speech tagging | If you build it, he will come. | - IN - prepositions and subordinating conjunctions. - PRP - Personal Pronoun - VBP - Verb Noun 3rd person singular present form. - PRP- Personal pronoun - MD - Modal Verbs - VB - Verb base form |
| Parsing | Mark and Joe went into a bar. | - (S(NP(NP Mark) and (NP(Joe)) - (VP(went (PP into (NP a bar)))) |
| Named Entity Recognition | Let’s meet Alice at 6 am in India. | - Let’s meet Alice at 6 am in India - Person Time Location |
| Coreference resolution | Mark went into the mall. He thought it was a shopping mall. | - Mark went into the mall. He thought it was a shopping mall. |
-
Sentence segmentation identifies sentence boundaries in the given text, i.e., where one sentence ends and where another begins. Sentences are often marked ended with the punctuation mark ‘.’
-
Tokenization - It identifies different words, numbers, and other punctuation symbols.
-
Stemming - It strips the ending of words like ‘eating’ and reduces it to ‘eat.’
-
Part-of-speech (POS) tagging assigns each word in a sentence its part-of-speech tag, such as designating the word as a noun or adverb.
-
Parsing involves dividing given text into different categories. To answer a question like this, modify another part of the sentence.
-
Named Entity Recognition - It identifies entities such as persons, location, and time in the documents.
-
Co-Reference resolution: It defines the relationship between a given word in a sentence and the previous and next sentences.
![]() Our solutions cater to diverse industries, focusing on serving ever-changing marketing needs. Click here for our Google Cloud Natural Language Solutions.
Our solutions cater to diverse industries, focusing on serving ever-changing marketing needs. Click here for our Google Cloud Natural Language Solutions.
What are the key Applications of Natural Language Processing?
Apart from its use in Big Data, Log Mining, and Log Analysis, it has other significant application areas. Although the term ‘NLP’ is not as popular as ‘big data’ or‘ machine learning,’ we use it daily.
Automatic Text Summarizer
Given the input text, the task is to write a summary of the text, discarding irrelevant points.Sentiment-based Text Analysis
It is done on the given text to predict the subject of the text, eg, whether the text conveys judgment, opinion or reviews, etc.Text Classification
It is performed to categorize different journals and news stories according to their domain. Multi-document classification is also possible. A famous example of text classification is spam detection in emails. Based on the journal's writing style, its attribute can be used to detect its author's name.Information Extraction
Information extraction proposes that email programs add events to the calendar automatically.How Can XenonStack Help You?
Unlock the Real Value of your Data with our Data Science Services and Solutions. Take Advantage of Business Analytics Solutions and Data Science Consulting to accelerate your Enterprise Growth.Text Analytics Solutions
Text Analytics or Text Mining is the automatic extraction of high-value information from text. The extraction involves structuring the input text, discovering patterns in the structured data and interpreting the results. Text Mining involves Machine Learning, Statistics, Data Mining, and Computational Linguistics. Sentiment Analysis Using Machine Learning, NLP, and Deep Learning At XenonStack, we process and analyze textual content and provide valuable insights by transforming the raw data into structured, usable information. XenonStack's Text Analytics Solutions offers Part-of-Speech (PoS) tagging, Clustering, Classification, Information Extraction, Sentiment Analysis and more.
Sentiment Analysis Using Machine Learning, NLP, and Deep Learning
Sentiment Analysis helps to apprehend people's reactions to situations. It predicts emotions such as anger, happiness, sadness, disgust, etc. XenonStack offers Sentiment Analysis and Intent Analytics using Machine Learning, Natural Language Processing, Deep Learning, Supervised Learning Algorithms, and Keras with Tensorflow. Enhance the customer experience through Sentiment Analysis in Business.
Enterprise Chatbot Solutions
Build, Deploy, and Manage Intelligent Chatbots that interact naturally with users on Websites, Apps, Slack, Facebook Messenger, and more. XenonStack Chatbot Solutions uses Cognitive Intelligence, enabling the bot to see, hear, and interpret more humanly.
- Click to explore AWS Natural Language Processing (NLP) Solutions
- Discover more about the Role and Uses of NLP in Government



























