
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is Agentic AI in Data Quality Management?
In an era when businesses rely on massive volumes of data to inform decisions, fuel artificial intelligence models, and drive operational strategies, ensuring data quality has never been more critical. Data serves as organisations' digital DNA, influencing everything from customer experience to compliance and innovation. Yet, data quality remains a persistent challenge.
Traditionally, organizations have depended on manual data quality checks or static rule-based engines. However, as datasets grow exponentially and become more complex and dynamic, these traditional methods prove inefficient and unsustainable. Enter Agentic AI, a paradigm shift in artificial intelligence in which autonomous software agents with decision-making capabilities take the lead in managing, maintaining, and enhancing data quality at scale.
Agentic AI is not just another AI buzzword; it's a practical evolution. These AI agents operate with a sense of purpose and autonomy. They follow programmed instructions and observe, analyze, decide, and act in real-time. This ability to operate independently makes them ideal for repetitive data quality tasks that require continuous monitoring or benefit from pattern recognition and contextual understanding.
This blog explores how Agentic AI and intelligent agents can revolutionize data quality management, their core benefits, practical use cases, and best practices for implementing these systems in your data infrastructure.
Key Takeaways
- Data Quality Agents autonomously monitor, validate, clean, and maintain data quality in real time — without human intervention or batch processing delays.
- Traditional rule-based quality tools cannot scale to modern data volumes, dynamic schemas, or cross-system consistency requirements.
- Agentic AI enforces six core quality dimensions (accuracy, completeness, consistency, timeliness, validity, uniqueness) continuously and simultaneously.
- Measurable impact: up to 80% reduction in manual data cleaning effort through automated pattern-based correction.
- For CDOs and VPs of Data & Analytics: Agentic data quality eliminates the manual remediation cycles that consume data engineering capacity — directly improving the reliability of the analytics output your teams are accountable for.
- For Chief AI Officers and CAOs: Clean, governed, continuously validated data is the prerequisite for production-grade ML and GenAI model performance. Agentic quality agents create that foundation autonomously.
What is Agentic AI Data Quality?
Agentic AI Data Quality uses autonomous AI agents to monitor, validate, and improve data quality continuously and in real time.
What Are Data Quality Agents and How Do They Work?
The Problem
Traditional data quality tools rely on manual configuration, static rule sets, and batch processing. They cannot adapt to new data patterns, enforce rules across distributed systems in real time, or learn from past corrections to improve future performance.
Why Traditional Systems Fail
| Limitation | Root Cause | Business Impact |
|---|---|---|
| Batch-only validation | Rules execute on schedules, not on data arrival | Errors persist in systems for hours or days before detection |
| Static rule sets | Rules require manual updates as data structures change | New data sources or schema changes immediately create quality gaps |
| No learning capability | Tools cannot improve based on correction history | Same categories of errors recur indefinitely |
| Siloed operation | Tools operate per system, not across the data ecosystem | Cross-system inconsistencies go undetected |
How Agentic AI Solves It
Data Quality Agents are autonomous AI systems that continuously monitor, validate, clean, and maintain data quality without human intervention. They use machine learning to identify patterns and anomalies, adapt to changing data environments, and apply corrections based on both learned patterns and defined business rules.
Key characteristics:
- Autonomy — Operate independently to detect and fix data issues 24/7
- Intelligence — Use machine learning to identify patterns and anomalies
- Adaptability — Learn from corrections and improve accuracy over time
- Real-time action — Validate and clean data as it enters systems
- Context awareness — Understand business rules and data relationships
Why Is Data Quality a Strategic Priority for Data-Driven Organizations?
High-quality data is essential for digital transformation, regulatory compliance, and trustworthy analytics. Poor data quality produces: flawed business intelligence, inaccurate forecasting, regulatory fines, customer dissatisfaction, and operational disruptions.
Six Core Dimensions of Data Quality
| Dimension | Definition | Agent Role |
|---|---|---|
| Accuracy | Data truthfully represents real-world facts | Agents cross-reference and validate against authoritative sources |
| Completeness | All required data is available | Agents detect and flag missing fields; trigger enrichment workflows |
| Consistency | Uniform data across systems and sources | Agents enforce standardization rules across distributed data assets |
| Timeliness | Data is current and relevant | Agents monitor data freshness and alert on stale records |
| Validity | Data conforms to syntax rules and standards | Agents apply format and schema validation at ingestion |
| Uniqueness | No data duplication exists | Agents continuously detect and deduplicate records |
Agentic AI enforces all six dimensions simultaneously, in real time, across the full data lifecycle.
What is the importance of data quality in business?
High-quality data drives better decision-making, compliance, and customer satisfaction, and it reduces operational risks.

How Do Agentic AI Data Quality Agents Improve Data Quality?
1. Automated Data Cleaning
Agentic AI systems autonomously detect and correct anomalies such as duplicate records, missing fields, and formatting errors. They can continuously monitor datasets and apply corrective actions without human intervention, dramatically improving speed and accuracy. Platforms like ElixirData's Data Quality Agents continuously scan datasets for duplicates, missing values, and formatting errors— automatically applying corrections based on learned patterns and business rules, reducing manual data cleaning efforts by up to 80%
2. Real-Time Data Validation
Traditional data validation happens in batches, which delays correction. Intelligent agents can perform continuous real-time validation, flagging or correcting errors as soon as data enters the system.
3. Dynamic Data Standardization
Agentic systems can learn the preferred formats for various data types and dynamically apply standardisation rules. This ensures consistency across departments, applications, and databases.
4. Intelligent Metadata Management
Agents can auto-generate metadata, track data lineage, and map interdependencies. This not only improves data discoverability but also enhances transparency and compliance.
5. Adaptive Data Governance
Agentic AI ensures that data governance policies are actively enforced. Data Governance Agents can detect policy violations, automatically rectify issues, and alert stakeholders in real-time.
What are Data Quality Agents?
They are AI systems that autonomously manage and improve data quality by monitoring, validating, and correcting data in real-time.
Where Are Agentic AI Data Quality Agents Used in Real-World Scenarios?
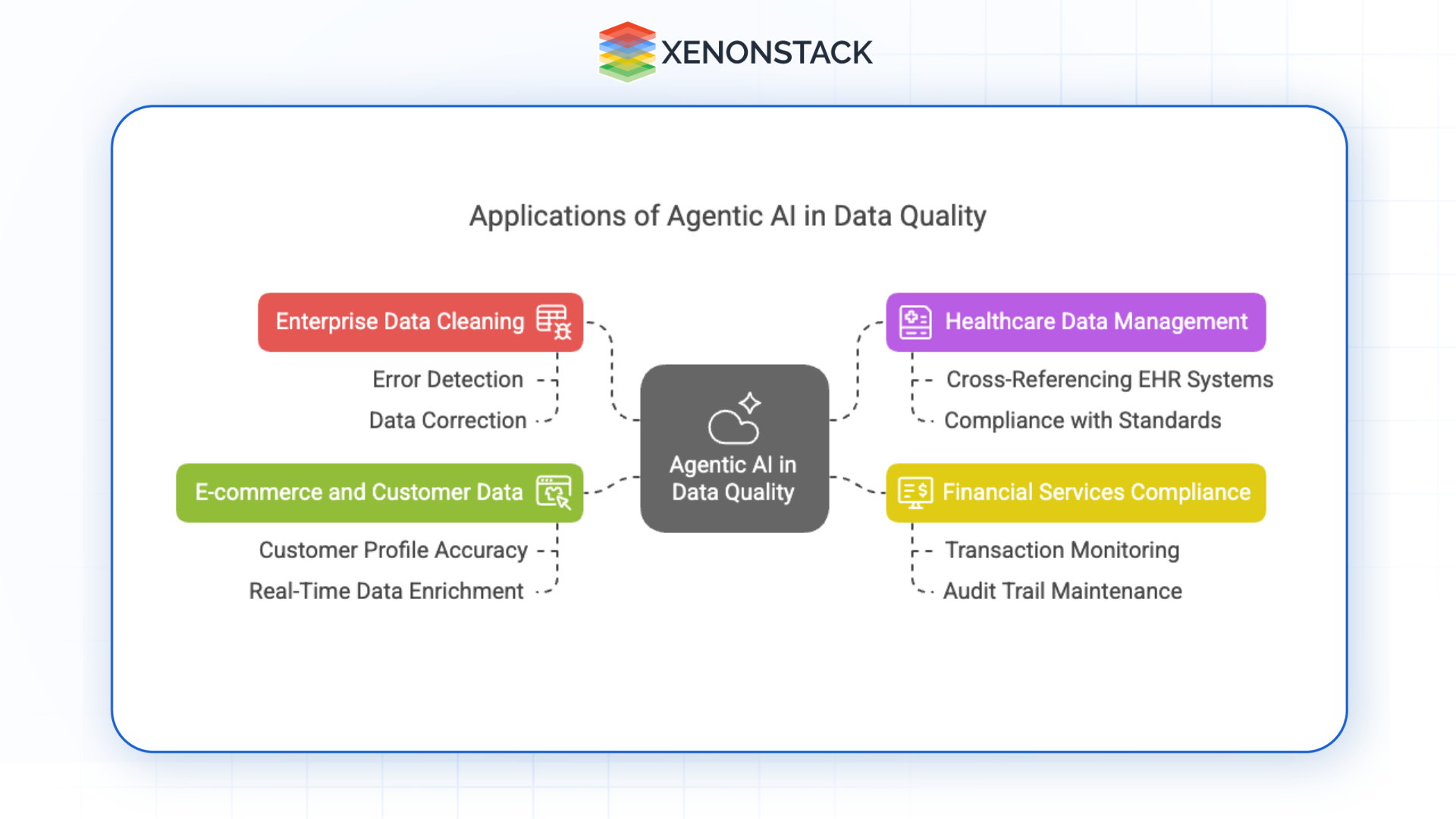 Fig 1: Applications of Agentic AI in Data Quality
Fig 1: Applications of Agentic AI in Data Quality| Industry | Use Case | Agent Capability |
|---|---|---|
| Enterprise Data Cleaning | Disparate source integration, multi-format normalization | Automates error detection and correction at ingestion |
| Healthcare | Patient record accuracy, EHR cross-referencing | Corrects inconsistencies, ensures medical data standard compliance |
| Financial Services | Transaction monitoring, regulatory reporting | Validates report data, maintains audit trails for GDPR/Basel III |
| E-Commerce | Customer profile accuracy, personalization data | Deduplicates, enriches, and validates customer records in real time |
How Should CDOs and Analytics Leaders Measure Data Quality Agent Performance?
Standard data quality metrics — error counts, manual remediation tickets, batch validation pass rates — measure symptoms, not system performance. Agentic data quality requires a measurement framework that captures autonomous decision quality, learning velocity, governance coverage, and business impact simultaneously.
Why Traditional Data Quality KPIs Are Insufficient
Manual metrics measure how much cleanup humans performed after errors surfaced. Agentic systems require metrics that capture how effectively agents prevented errors from entering downstream systems, how quickly they learned to recognize new error patterns, and whether their governance enforcement is audit-defensible.
Four-Dimension KPI Framework for Data Quality Agent Performance
| Dimension | Key Metrics | What It Measures |
|---|---|---|
| Detection & Prevention | Real-time error detection rate, time-to-detection (vs. batch baseline), error recurrence rate | Are agents catching issues before they reach downstream systems? |
| Correction Quality | Automated fix accuracy %, human override frequency, false positive correction rate | Are agents making correct decisions, not just fast ones? |
| Governance Coverage | % of data assets under active agent monitoring, policy violation detection rate, audit trail completeness | Is governance enforced across the full data ecosystem? |
| Business Impact | Manual remediation hours eliminated, data freshness improvement, downstream model accuracy change | Are quality agents delivering measurable business value? |
Portfolio-Level Metrics for CDOs and VPs of Data & Analytics
- Autonomous resolution rate — Percentage of data quality issues resolved by agents without human intervention. Target: above 75% within 90 days of deployment.
- Human override frequency — High rates indicate misconfigured business rules or insufficient agent training data — both actionable signals.
- Quality coverage growth — Is the percentage of data assets under continuous agent monitoring increasing quarter-over-quarter?
- Time-to-clean reduction — Average elapsed time between error introduction and correction, compared to pre-deployment baseline.
For Chief AI Officers: Governance coverage and audit trail completeness are non-negotiable. Every correction applied by a quality agent must be logged, explainable, and traceable to a business rule or learned pattern. Unexplained corrections in regulated data environments create compliance exposure, not protection. Build explainability requirements into agent deployment from day one.
What Are the Benefits of Agentic AI Data Quality for Organizations?
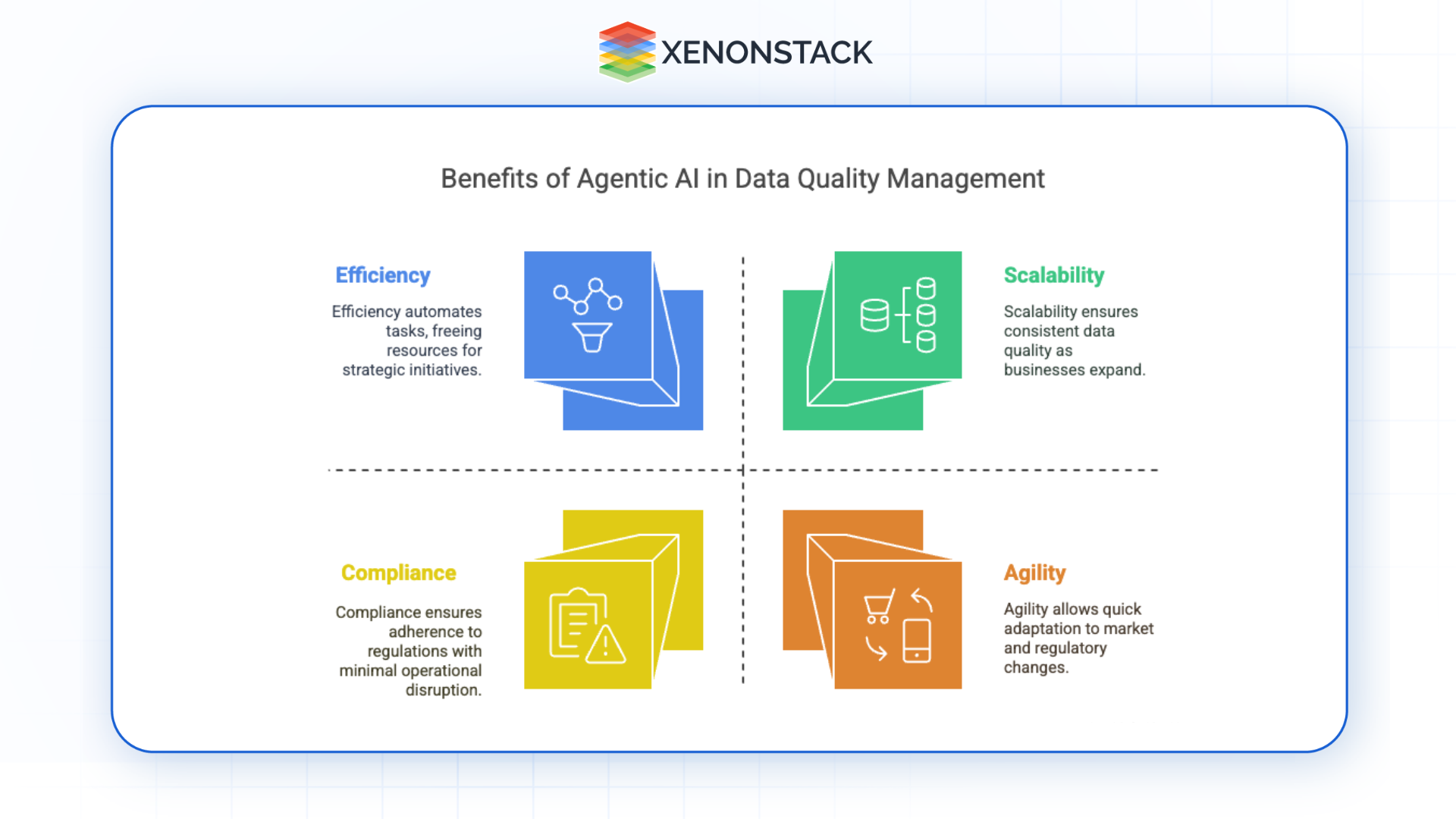 Fig 2: Agentic AI in Data Quality Management
Fig 2: Agentic AI in Data Quality Management| Business Impact | Capability | Outcome |
|---|---|---|
| Scalability | Agents handle massive volumes across sources and formats | Consistent quality as business data volumes grow |
| Efficiency | Automates cleaning, validation, and integration | Faster time-to-insight; reduced operational cost |
| Accuracy | Continuous real-time monitoring with contextual correction | Higher data fidelity and analytical reliability |
| Compliance | Enforces GDPR, HIPAA, CCPA policies continuously | Reduced regulatory risk; automated audit documentation |
| Agility | Agents retrain and reconfigure to new data structures | Rapid adaptation to regulatory or schema changes |
What Are the Best Practices for Implementing Agentic AI Data Quality Agents?
1. Assess Data Readiness
Begin by conducting a comprehensive data audit to identify gaps in data quality, existing infrastructure limitations, and integration challenges. This foundational understanding will guide your implementation roadmap.
2. Define Clear Objectives
Set measurable goals for what you want the agentic AI system to achieve—whether improving accuracy, speeding up data validation, or enhancing compliance. Well-defined KPIs will help track progress and justify ROI.
3. Choose the Right Tools and Platforms
Select AI platforms that support agentic capabilities and can integrate with your existing systems. Look for features such as automated workflows, real-time monitoring, and low-code/no-code interfaces to simplify deployment.
4. Engage Stakeholders Across the Organization
Collaboration is key. Involve data stewards, compliance officers, IT teams, and business users early in the process. This ensures goal alignment, fosters trust in AI systems, and accelerates user adoption.
5. Establish Continuous Monitoring and Feedback Loops
Implement dashboards and performance metrics to monitor the effectiveness of agentic AI systems. Use user feedback and system performance data to refine rules, retrain models, and optimize workflows.
6. Ensure Ethical and Transparent Use of AI
Build explainability and transparency into your agentic systems. Make sure decisions made by AI agents can be traced and justified, especially in regulated industries. Regular audits and ethical guidelines will help maintain trust.

How Does ElixirData Enable Agentic Data Quality Deployment?
ElixirData provides a comprehensive platform for deploying Data Quality Agents across enterprise data ecosystems. Agents work autonomously to ensure data accuracy, consistency, and compliance — reducing manual effort while improving data reliability.
Core platform capabilities:
| Capability | Function |
|---|---|
| Automated Data Profiling | Continuously analyzes data patterns, identifying quality issues before they impact operations |
| Intelligent Error Correction | ML-powered agents detect and fix errors based on historical patterns and business rules |
| Real-Time Monitoring | 24/7 pipeline surveillance with instant alerts when quality thresholds are breached |
| Compliance Automation | Built-in enforcement of GDPR, HIPAA, CCPA requirements |
| Seamless Integration | Connects with data warehouses, lakes, CRM systems, and analytics tools without workflow disruption |
| Explainable AI | Full audit trails and decision transparency for every agent action |
Deployment pathway:
- Assessment — Evaluate current data quality challenges and infrastructure
- Configuration — Deploy specialized agents tailored to data sources and business rules
- Integration — Connect agents to existing systems with minimal disruption
- Monitoring — Track performance through dashboards showing quality improvements
- Optimization — Agents continuously learn and adapt, improving accuracy over time
How can I get started with Data Quality Agents?
Contact us to assess your data needs, configure agents, integrate with your systems, and monitor their performance.
Conclusion: Agentic Data Quality Is the Foundation Enterprise AI Requires
Agentic AI is redefining data quality management — moving organizations from reactive cleanup cycles to continuous, autonomous data integrity enforcement. For CDOs, CAOs, VPs of Data & Analytics, and Chief AI Officers, the strategic implication is direct: the quality of data flowing through enterprise systems determines the reliability of every analytical output, every ML model prediction, and every AI-driven decision your organization makes.
Organizations that deploy Data Quality Agents with rigorous performance governance frameworks today build the trusted data foundation that makes enterprise AI defensible, scalable, and consistently reliable. Those that continue with manual or batch-based quality approaches absorb compounding technical debt — in engineering time, compliance risk, and degraded model performance — as data volumes continue to grow.
The capability is available. The competitive cost of inaction is measurable.



























