
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is Delta Lake?
Delta Lake is an open-source data storage layer that delivers reliability to data lakes. It implements ACID transactions, scalable metadata handling, and unifies the streaming and batch data processing. Delta Lake architecture runs on top of your current data lake and is fully cooperative with Apache Spark APIs.Why Delta Lake?
Are we making progress? Well, let's see what are the main benefits of implementing a Delta Lake in your company.The Predicament with current Data Architectures
Current big data architectures are challenging to develop, manage, and maintain. Most contemporary data architectures use a mix of at least three varying types of systems: streaming systems, data lakes, and data warehouses. Business data comes through streaming networks such as Amazon Kinesis or Apache Kafka, which mainly focus on accelerated delivery. Then, data is collected in data lakes, such as Apache Hadoop or Amazon S3, which are optimized for large-scale, ultra-low-cost storage. Lamentably, data lakes individually do not have the performance and quality required to support high-end business applications: thus, the most critical data is uploaded to data warehouses, which are optimized for significant performance, concurrency, and security at a much higher storage cost than data lakes.Delta Lake architecture, Lambda Architecture
Lambda architecture is a traditional technique where a batch system and streaming system prepare records in correspondence. The results are then merged during query time to provide an entire answer. Strict latency requirements to process old and newly formed events made this architecture famous. The key downside to this architecture is the development and operational overhead of maintaining two different systems. There have been efforts to ally batch and streaming into a single system in history. Companies have not been that victorious though in those attempts. With the arrival of Delta Lake, we are seeing a lot of our clients adopting a simple constant data flow model to process data as it comes. We call this architecture, The Delta Lake architecture. We cover the essential bottlenecks for using a continuous data flow model and how the Delta architecture resolves those difficulties.Hive on HDFS
Hive is formed on top of Hadoop. It is a data warehouse framework for implementing and examination of data that is collected in HDFS. A hive is an open-source software that allows programmers to analyze massive data sets on Hadoop. In Hive, records and databases are built primary, and then data is arranged into these records. Hive is a data warehouse composed of handling and querying only structured information that is collected in logs. While dealing with structured data, Map Reduce does not have optimization and usability characteristics like UDFs, but the Hive framework does. Query optimization leads to an efficient method of query execution in terms of performance.Hive on S3
Amazon Elastic MapReduce (EMR) provides a cluster-based distributed Hadoop framework that executes it transparent, quick, and cost-effective to process immense volumes of data over dynamically scalable Amazon EC2 instances. Apache Hive runs on Amazon EMR clusters and communicates with data collected in Amazon S3. A typical EMR cluster will have a master node, one or more core nodes, and arbitrary task nodes with a set of software resolutions that are proficient in shared parallel processing of data at scale. Delta Lake comprises features that combine data science, data engineering, and production workflows, perfect for the machine learning life cycle.How Delta Lake is different?
ACID transactions on Spark
Serializable isolation levels guarantee that users never see variable data. In a typical Data lake, several users would be accessing, i.e., Reading and writing the data in it, and the data integrity must be preserved. ACID is a critical feature in the bulk of the databases. Still, when it comes to HDFS or S3, generally, it is tough to give the same stability guarantees that ACID databases provide us. Delta Lake stores a transaction log to track all the commits done to the record directory to implement ACID transactions. Delta Lake architecture provides Serializable isolation levels to guarantee the data consistent crosswise many users.Scalable metadata handling
Leverages Spark’s distributed processing power to manage all the metadata for petabyte-scale records with billions of files at ease.Streaming and batch unification
In a Data lake, if we have a use state of both Stream processing and Batch processing, it is common to follow Lambda architecture. In Data lake, the data coming in as Stream (maybe from Kafka) or any past data you have (say HDFS) is the same record. It gives a consolidated glimpse of both these two distinct paradigms. A record in Delta Lake is a bunch record as well as a streaming origin and sink. Streaming Data Ingest, batch historic backfill, interactive queries all just work out of the case.Schema enforcement
Data Lake helps avoid detrimental data getting your data lakes by implementing the capability to define the schema and help execute it. It restricts data corruption by blocking the faulty data to get toward the system even before the data is ingested to the data lake by giving reasonable failure messages.Time travel
Data versioning allows rollbacks, full past audit trails, and reproducible machine learning practices while using Delta Lake.Upserts and deletes
Delta Lake architecture supports merge, update and delete operations to enable complex use cases like change-data-capture, slowly-changing-dimension (SCD) operations, streaming upserts, and so on.
The solution to the "Data Lake dilemma" is to adopt Delta Lake. How? Ask Our Big Data Consultant
Delta Lake Transaction Log
Delta lake transaction logs, also known as delta log. It is an ordered record of all transactions that have been performed on the delta lake table since its creation. Use of transaction log: 1. To allow various users to read and write to the given table at the same time. It shows the correct view of data to users. It tracks all changes that users make to the table. 2. it implements atomicity on delta lake, it keeps watching on transactions performed on your delta lake either complete fully or not complete at all. Delta lake offers a guarantee of atomicity with the help of a transaction mechanism. It also works as a single source of truthTransaction Log Working and atomic commits
- Delta Lake automatically generates checkpoint files every ten commits. the checkpoint file saves the current state of the data in parquet format, which is easy for the spark to read quickly.
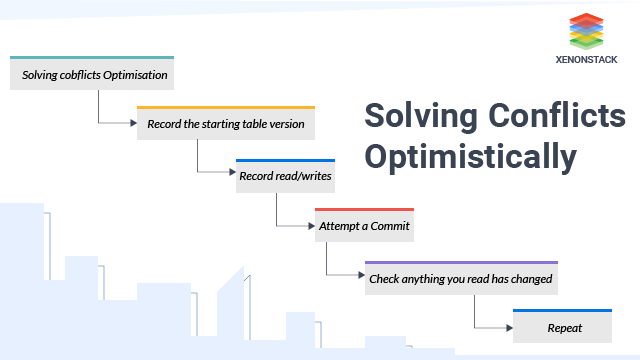
- Delta Lake is built on top of apache-spark, so multiple users cannot modify a table at once to handle this problem delta lake employs optimistic concurrency control when we need the same pieces of data at a time, that there’s a conflict and that’s optimistic concurrency control.
- Solving Conflicts Optimistically
Delta Lake Schema Enforcement
Schema enforcement also is known as schema validation. Delta Lake architecture ensures data quality by matching data to be written on the table. If the data’s schema is not matching with the table’s schema then it rejects the data. Like the front desk manager in some busy restaurant that only accepts reservations. Schema enforcement is a great tool. It works as a gatekeeper. It was enforced to those tables that directly feed to ML Algorithms, BI dashboards, Data Visualization Tools, and a production system that required strongly typed and semantic data.Schema Evolution
Schema evolution is a feature that allows users to change tables current Schema easily, mostly used when we are performing append or overwrite operations. It can be used at any time when you want to intend to change the table schema. After all, it is not hard to add a new column.Delta Time Travel for Data Lakes
There is a new feature titled time travel capability. The next-generation unified analytics engine is made at the top of the apache-spark. Delta automatically versions all big data stored in Delta Lake. You can access any version of the data. Delta Lake architecture simplifies the Data pipeline by making it easy to change and roll back data in any case of wicked writes. You can access versions of data in two different ways.- Using timestamp - You can provide the timestamp or date string as an option to the DataFrame reader
- Using a version number - In Delta, every writer has a version number, and one can use it to travel back in time as well.
Conclusion
As the business issues and requirements grow over time, so does the structure of data. But, with the help of Delta Lake, incorporating new dimensions become easy as the data changes. Delta lakes are making data lakes' performance better, more reliable, and easy to manage. Therefore, accelerate the quality of the data lake with a safe and scalable cloud service.- Get insight on Hadoop Delta Lake Migration
- Discover more about AWS Delta Lake


























