
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction Service Level Agreements
The demand for accurate, real-time data has never been greater for today's data engineering teams, yet data downtime has always been a reality. So, how do we break the cycle and obtain reliable data?
Data teams in the early 2020s, like their software engineering counterparts 20 years ago, experienced a severe conundrum: reliability. Businesses are ingesting more operational and third-party data than ever before. Employees from across the organization, including those on non-data teams, interact with data at all stages of its lifecycle. Simultaneously, data sources, pipelines, and workflows are becoming more complex.
While software engineers have resolved application downtime with specialized fields (such as DevOps and Site Reliability Engineering), frameworks (such as Service Level Agreements, Indicators, and Objectives), and a plethora of acronyms (SRE, SLAs, SLIs, and SLOs, respectively), data teams haven't yet given data downtime the due importance. Now it is up to data teams to do the same: prioritize, standardize, and evaluate data reliability. I believe that data quality or reliability engineering will become its specialization over the next decade, in charge of this crucial business component. In the meantime, let's look at what data reliability SLAs are, why they're essential, as well as how to develop them.
Data meshes address the shortcomings of data lakes by giving data owners more autonomy and flexibility, allowing for more data experimentation and innovation, and reducing the burden on data teams to meet the needs of every data consumer through a single pipeline. Read more about Adopt or not to Adopt Data Mesh?
What is a Service Level Agreements?
"Slack's SLA guarantees 99.999 service uptime. If breached, they apply for a service credit."
The best way to describe Service Level Agreements (SLAs) is a method that many businesses use to define and measure the standard of service that a given vendor, product, or internal team will provide—and potential remedies if they do not.
As an example, for customers on Plus plans and above, Slack's customer-facing SLA guarantees 99.99 percent uptime every fiscal quarter with no more than 10 hours of scheduled downtime. If they come up short, impacted customers will be given service credits for future use on their accounts.
Customers use service level agreements (SLAs) to guarantee that they receive what they paid for from a vendor: a robust, dependable product. Many software teams develop SLAs for internal projects or users instead of end-users.
Importance of data reliability Service Level Agreements for Data Engineers
As an example, consider internal software engineering SLAs. Why bother formalizing SLAs if you don't have a customer urging you to commit to certain thresholds in an agreement? Why not simply rely on everyone to do their best and aim for as close to 100 percent uptime as possible? Would that not be adding extraneous burdensome regulations?
No, not at all. The exercise of defining, complying with, and evaluating critical characteristics of what defines reliable software can be immensely beneficial while also setting clear expectations for internal stakeholders. SLAs can help developing, product, and business teams think about the bigger picture about their applications and prioritize incoming requests. SLAs provide confidence that different software engineering teams and their stakeholders mean the same thing, caring about the same metrics and sharing a pledge to thoroughly documented requirements.
Setting non-zero-uptime requirements allow for room to improve. There is no risk of downtime if there is no room for improvement. Furthermore, it is simply not feasible. Even with the best practices and techniques in place, systems will fail from time to time. However, with good SLAs, engineers will know precisely when and how to intervene if anything ever goes wrong.
Likewise, data teams and their data consumers must categorize, measure, and track the reliability of their data throughout its lifecycle. Consumers may make inaccurate assumptions or rely on empirical information about the trustworthiness of your data platform if these metrics are not strictly established. Attempting to determine data dependability SLAs help build trust and strengthen bonds between your data, your data team, and downstream consumers, whether your customers or cross-functional teams within your organization. In other words, data SLAs assist your organization in becoming more "data-driven" in its approach to data.
SLAs organize and streamline communication, ensuring that your team and stakeholders share a common language and refer to the same metrics. And, because defining SLAs helps your data team quickly identify the business's priority areas, they'll be able to prioritize more rapidly and respond more rapidly when cases arise.
Data meshes address the shortcomings of data lakes by giving data owners more autonomy and flexibility, allowing for more data experimentation and innovation, and reducing the burden on data teams to meet the needs of every data consumer through a single pipeline.Click to explore Adopt or not to Adopt Data Mesh? - A Crucial Question
What is DQ SLA (Data Quality Service Level Agreement)?
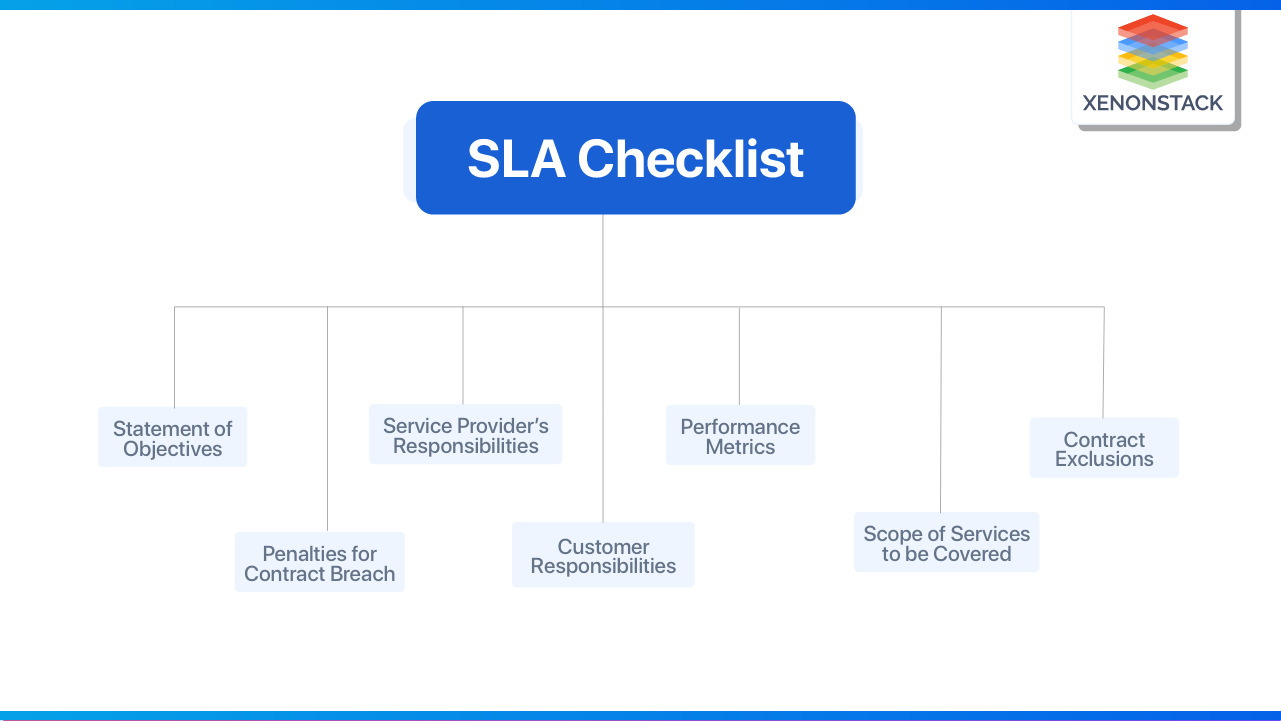
A DQ SLA, like a more traditional SLA, governs the roles and responsibilities of a hardware or software vendor in accordance with regulations and levels of acceptability, as well as realistic expectations for response and restoration when data errors and flaws are identified. DQ SLAs can be defined for any circumstance where a data provider transfers data to a data consumer.
More specifically, a data recipient would specify expectations regarding measurable aspects related to one or more dimensions of data quality (such as completeness, accuracy, consistency, timeliness, and so on) within any business process. The DQ SLA would then include an expected data quality level and even a list of processes to be followed if those expectations are not fulfilled, such as:
- The location in the business process flow that the SLA covers.
- The SLA covers critical data elements.
- Each data element has its own set of data quality dimensions.
- Quality expectations for each data element for each of the identified dimensions.
- Specified data quality rules that formalize those expectations.
- Business consequences of noncompliance with defined data quality rules.
- Methods for determining non-compliance with those expectations.
- Acceptance criteria for each measurement
- How and where should concerns be classified, prioritized, and documented.
- The individual(s) will be notified if the acceptability thresholds are not met.
- Expected resolution or restoration times for the issues.
- Method for keeping track of the status of the resolution process.
- When the resolution times are not met, an escalation tactic and hierarchy are implemented.
The DQ SLA is distinctive because it recognizes that data quality issues and resolution are almost always linked to business operations. To benefit from the processes suggested by the definition of a DQ SLA (particularly items 5, 7, 9, and 12), systems facilitating those operations, namely:
- Management of data quality rules
- Monitoring, measurement, and notification
- Categorization, prioritization, and tracking of data quality incidents
These concepts are critical in establishing the DQ SLA's goal: data quality control, which is based on the definition of rules based on agreed-upon data quality dimensions.
Suppose it is determined that the information does not meet the defined expectations. In that case, the remediation process can include a variety of tasks, such as writing the non-confirming text to an outlier file, emailing a system administrator or data steward to resolve the issue, running an immediate corrective data quality action, or any combination of these.
Data catalog scan by facets, keywords, and business terms with robust search capabilities. Non-technical users can appreciate the ability to search using natural language.Read More about Data Catalog Architecture for Enterprise Data Assets
How to build Service Level Agreements for Data Platforms?
Creating and adhering to data reliability SLAs is a cohesive and precise exercise.
First, let's go over some terminology. According to Google's service level agreements (SLAs), clear service level indicators (SLIs), quantitative measures of quality service, and accepted service level objectives (SLOs), the expected values or ranges of values where each criterion must meet, are necessary. Many engineering teams, for example, use availability as a criterion of site reliability and set a goal of maintaining the availability of at least 99 percent.
Creating reliability SLAs for data teams typically involves three key steps: defining, measuring, and tracking.
Using SLAs to define Data Reliability
The first phase is to consent and clearly articulate what reliable data signifies to your company.
Setting a baseline is a good place to start. Begin by taking stock of your data, how it's being used, and by whom. Examine your data's historical performance to establish a baseline metric for reliability.
You should also solicit feedback from your data consumers on what "reliability" means to them. Even with a thorough knowledge of data lineage, data engineers are frequently isolated from their colleagues' day-to-day workflows and use cases. When developing reliability agreements with internal teams, it is crucial to know how consumers interact with data, what is most important, or which potential complications require the most stringent, critical intervention.
Furthermore, you'll want to ensure that all relevant stakeholders — all data leaders or business consumers with a stake in reliability — have assessed it and agreed on the descriptions of reliability you're constructing.
You'll be able to set clear, actionable SLAs once you understand
- What data you're working with
- How it's used, and
- Who uses it.
SLIs for measuring Data Reliability
Once you've established a comprehensive understanding and baseline, you can begin to home in on the key metrics that will serve as your service-level reliability indicators.
As a general rule, data SLIs should portray the mutually agreed-upon state of data you defined in step 1, as well as limitations on how data can and cannot be used and a detailed description of data downtime. This may include incomplete, duplicated, or out-of-date data.
Your particular use case will determine sLIs, so here are a few metrics used to assess data health:
- The number of data points associated with a specific data asset (N). Although this may be well outside your control, given that you most likely rely on external data sources, it would still be a significant cause of data downtime and, therefore, should be determined by measuring.
- Time-to-detection (TTD): This metric quantifies how quickly your team is alerted when an issue arises. This could take weeks or even months if you don't have proper detection and emergency notification strategies in place. Bad data can cause "silent errors," leading to costly issues that influence both your company and your customers.
- Time-to-resolution (TTR): This measures how quickly your team was capable of resolving an issue after being notified about it.
Using SLOs to track Data Reliability
You can set objectives, i.e., reasonable ranges of data downtime, when you've already identified key indicators (SLIs) for data reliability. All such SLOs should be appropriate based on your current situation. For instance, if you choose to include TTD as a metric but are not using automated monitoring tools, your SLO should be lower than that of a mature organization with extensive data reliability tooling. Aligning those scopes makes it easy to create a consistent framework that rates incidents depending on the severity, making it easier to interact and quickly respond when issues arise.
Once you've established these priorities and integrated them into your SLAs, you can create a dashboard to track and evaluate progress. Some data teams build ad hoc dashboards, whereas others depend on dedicated data observability options.
KAFKA vs. PULSAR: Pick the Right one for your Business
What are the challenges of Service Level Agreements in Data Platforms?
The delivery of services for millions of customers via data centers involves resource management challenges. Data processing of risk management, consumer-driven service management, and independent resource management, measuring the service, system design, and reiteration assessment resource allocation in SLA with virtualization are the challenges of service level agreements.
Consumer-Driven Service Management
To satisfy the customer requirement, three user-centric objectives are used: Receiving feedback from customers. Providing reliable communication between customers. Increasing access efficiency to understand the specific necessities of the customer. Believing the customer. When developing a service, if customer expectations are taken into account, those expectations are imported into the service provider.
Data Processing of Risk Management
The Risk Management process includes:
- Identifying risk factors and assessing them.
- Identifying risk management techniques.
- Reviewing the risk management plan.
Grid service customers' service quality conditions necessitate the formation of service level agreements between service providers and customers. Because resources are disrupted and unavailable, service providers must decide whether to continue or reject service level agreement requests.
Independent Resource Management
The data processing center should keep the reservation process going smoothly by managing the existing service requisition, improving the future service requisition, and changing the price for incoming requests. The resource management paradigm maps resource interactions to a platform-independent service level agreements pool. The resource management architecture with the cooperation of computing systems via numerous virtual machines enhances the effectiveness of computational models and the utilization of resources designed for on-demand resource utilization.
SLA Resource Allocation Using Virtualization
Virtual machines with various resource management policies facilitate resource allocation in SLA by meeting the needs of multiple users. An optimal joint multiple resource allocation method is used in the Allocation of Resource Model of Distributed Environment. A resource allocation methodology is introduced to execute user applications for the multi-dimensional resource allocation problem.
Measuring the Service
Various service providers offer various computing services. Original cloud impressions from numerous public documents must be assessed for service performance to design the application and service needs. As part of service level agreement, service measurement includes the current system's configuration and runtime information metrics.
System Design and Reiteration Valuation
Various sources and consumers with varying service standards are assessed to demonstrate the efficiency of resource management plans. Because resources are transferred, and service requisitions will come from multiple consumers at any stage, it is tedious to perform a performance evaluation of monitoring the resource plans in a repetitive and administrable fashion.
Click to explore Top 9 Challenges of Big Data Architecture
Conclusion
Data SLAs help the organization stay on track. They are defined as a public pledge to others. They are a bilateral agreement; you agree to continue providing data within specified criteria in exchange for people's participation and awareness. A lot can go wrong in data engineering, and a lot is due to misunderstanding. Documenting your SLA will go a long way toward setting the record straight, allowing you to achieve your primary objective of instilling greater data trust within your organization.The good news is when defining metrics, service, and deliverable targets for big data analytics, you don't have to start from scratch since the technique can be borrowed from the transactional side of your IT work. For so many businesses, it's simply a case of examining the level of service processes that are already in the place for their transactional applications, then applying these processes to big data and making the required changes to address distinct features of the big data environment, such as parallel processing and the handling of several types and forms of data.
- Read more about Governed Data Lake
- Explore more about Composable Data Processing with a Case study


























