
Introduction to Crop Yield Prediction
Precision farming has emerged as a game-changer in modern agriculture, reshaping traditional practices by integrating advanced technologies. At the core of precision farming lies the ability to predict crop yields accurately, a capability that empowers farmers to optimize resources and increase productivity. Leveraging cutting-edge techniques like Generative AI and state-of-the-art platforms such as Databricks, we embark on a journey to explore the revolutionary potential of crop yield prediction.
Crop yield prediction involves forecasting the quantity and quality of crops harvested from a particular area. This predictive capability holds profound significance in precision farming, as it enables farmers to make data-driven decisions regarding planting, irrigation, fertilization, and pest control. By anticipating potential yields, farmers can optimize resource allocation, minimize waste, and maximize profitability. Moreover, accurate yield predictions facilitate proactive risk management, allowing farmers to mitigate the impact of adverse weather conditions, diseases, or market fluctuations.
Exploring Generative AI Techniques for Synthetic Data Generation
Generative AI techniques have become increasingly popular for generating synthetic data, particularly in scenarios where real data is scarce. These methods have demonstrated the ability to create data that is comparable to real-world samples, making them a promising solution for overcoming data scarcity challenges.
Among the key generative AI techniques are Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GANs are a type of AI model that employs two neural networks to generate fake data points that closely resemble real ones. On the other hand, VAEs learn a latent space representation of the data, enabling the controlled generation of new samples. Both techniques have shown promise in creating synthetic data that mirrors the characteristics of authentic data sets.
Recent research has focused on utilizing large language models (LLMs), such as GPT and BERT, for synthetic data generation. These models, trained on extensive datasets, have demonstrated remarkable capabilities in generating coherent and contextually relevant text, pushing the boundaries of AI in language-related tasks.
For example, domain-specific models like Clinical BERT, which are adapted from BERT through pre-training on clinical texts, have shown superior performance in tasks such as predicting hospital readmissions compared to the original BERT model. This underscores the importance of synthetic data in enabling the development and fine-tuning of AI models for specific domains.
Utilizing Databricks Platform for Crop Yield Prediction Models
Databricks presents a robust platform capable of aiding in crop yield prediction through its prowess in big data processing and machine learning. Below is a fundamental outline of employing Databricks for crop yield prediction:
-
Data Gathering and Integration: Start by collecting relevant data such as weather patterns, soil quality, and past crop yields. Databricks simplifies the integration process by allowing you to bring in data from various sources effortlessly.
-
Data Processing and Analysis: Leverage Databricks' Spark functionalities to process and analyse the gathered data. This involves tasks like cleaning up the data, dealing with any missing values, and exploring the data to gain insights.
-
Feature Engineering: Identify key factors that influence crop yield, such as temperature variations, precipitation levels, and the types of crops being grown. Databricks empowers you to create new features from your data, enhancing the predictive power of your models.
-
Model Development: Utilize Databricks' MLlib to construct machine learning models tailored for crop yield prediction. You can choose from a variety of models ranging from simple regressions to more sophisticated algorithms like Random Forests or Gradient Boosting.
-
Model Training and Assessment: Train your chosen model using the dataset you've prepared. Databricks offers tools for conducting cross-validation and fine-tuning hyperparameters, enabling you to enhance the accuracy and reliability of your model.
-
Prediction and Visualization: Apply the trained model to forecast crop yields based on the input data. Databricks provides built-in visualization tools to help you interpret the results effectively, allowing you to gain valuable insights from your predictions.
-
Deployment: Once you've validated and fine-tuned your model, you can deploy it as a web service or integrate it seamlessly into your existing systems, ensuring that your crop yield predictions are readily accessible and actionable.
Training and Fine-Tuning Crop Yield Prediction Models with Synthetic Data
Training and fine-tuning crop yield prediction models with synthetic data involves a detailed process to ensure the predictions' accuracy and reliability.
-
Formulate a Question: Define the specific problem you aim to address with your crop yield prediction model. For instance, you might want to predict the yield of a particular crop, such as maize, in a specific geographical region, considering various environmental and agricultural factors.
-
Gather Information: Collect a wide range of relevant data sources that can provide insights into the factors affecting crop yield. This includes but is not limited to weather conditions, soil quality, historical yield data, agricultural management practices, and crop characteristics.
-
Generate Synthetic Data: Utilize crop simulation models or statistical techniques to generate synthetic datasets that mimic real-world agricultural conditions. These models can simulate various factors such as plant spatial arrangement, pollination efficiency, pest infestations, and fluctuations in weather conditions over time.
-
Data Preprocessing: Preprocess the collected data to ensure its quality and usability for model training. This involves tasks such as cleaning the data to remove any inconsistencies or errors, handling missing values through imputation or deletion, and normalizing or standardizing the data to bring it to a consistent scale if necessary.
-
Train the Model: Select appropriate machine learning algorithms suited for crop yield prediction tasks. Depending on the nature of the data, algorithms like Long Short-Term Memory (LSTM) networks for time-series data or ensemble methods such as Random Forests may be suitable. Train the model using the synthetic dataset, enabling it to discern patterns and correlations between input variables and crop yields.
-
Test the Model: Evaluate the trained model's performance using a separate test dataset that was not used during the training phase. Measure various performance metrics such as Mean Absolute Error (MAE), Mean Squared Error (MSE), or Root Mean Squared Error (RMSE) to assess the model's accuracy and predictive capability.
-
Fine-Tune the Model: Fine-tune the model's hyperparameters and architecture to optimize its performance further. This involves techniques such as grid search or random search to explore different parameter combinations systematically and identify the configuration that yields the best results on the validation set.
-
Deploy the Model: Once satisfied with the model's performance, deploy it for real-world use in agricultural decision-making processes. This could involve integrating the model into a user-friendly application or deploying it as a web service accessible to stakeholders such as farmers, agronomists, or policymakers.
-
Iterate: Recognize that machine learning is an iterative process, and improvements can always be made. Iterate on the model development process based on feedback from stakeholders, new data sources, or advances in machine learning techniques. Continuously monitor the model's performance in production and update it as necessary to maintain its effectiveness over time.
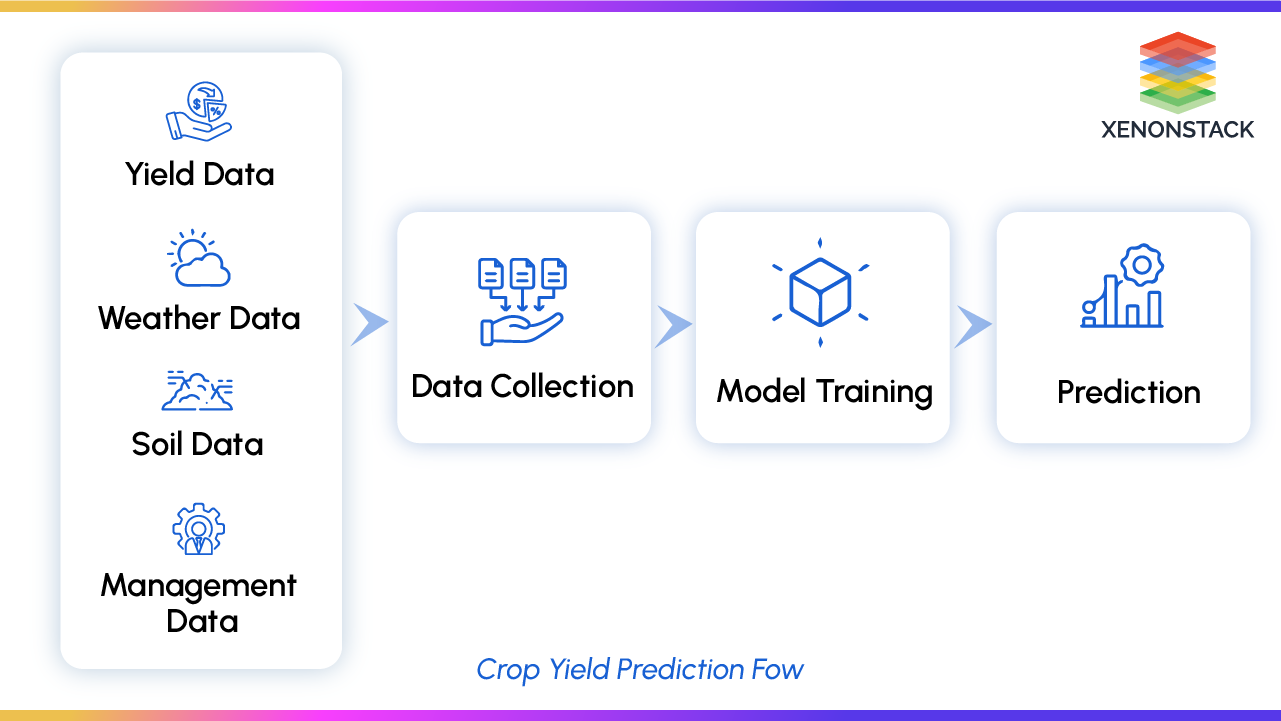
Validating Model Accuracy and Performance in Crop Yield Prediction
Validating the accuracy and performance of a model in crop yield prediction involves several steps. Here are some key points that we use for validating model accuracy -
-
Input Modalities: To predict crop yields accurately, we need to gather various types of information. This includes detailed maps showing where crops are grown, images from satellites like Sentinel-2, data on weather conditions, soil quality, and even the shape of the land (Digital Elevation Model or DEM). The combination of data we use depends on where we're looking, what crop we're interested in, and the specific model we're using.
-
Machine Learning Models: Various machine learning models such as Random Forest Regression, Gradient Boosting Regression, Adaboost Regression, and Decision Tree Regression have been employed for crop yield prediction. The performance of these models can be compared to determine the most accurate one.
-
Performance Metrics: The Root Mean Square Error (RMSE) serves as a prevalent metric for assessing the prediction precision of a model. For example, a model achieving an RMSE equivalent to 12% of the average yield and 50% of the standard deviation on the validation dataset through predicted weather data is deemed to exhibit excellent prediction accuracy.
-
Early Prediction: Predicting crop yield early can assist farmers in boosting their harvest and consequently enhancing their socioeconomic standing.
By gathering the right information, testing different models, checking how well they work, and using the predictions to help farmers plan, we can improve crop yields and make life better for farmers.
Real-world Implementations of Crop Yield Prediction in Precision Farming
-
Precision Irrigation Systems: Integrating crop yield prediction with IoT sensors and automated irrigation systems allows for precise water management, ensuring that crops receive the optimal amount of moisture based on predicted yield requirements.
-
Variable Rate Application of Inputs: By tailoring the application of fertilizers, pesticides, and other inputs to specific areas of a field based on predicted yield variations, farmers can optimize input usage and minimize environmental impact.
-
Pest and Disease Management: Predictive models can identify patterns and indicators of pest and disease outbreaks, enabling farmers to implement targeted control measures and reduce crop losses.
-
Market Forecasting and Planning: Accurate crop yield predictions provide valuable insights into market trends and demand, empowering farmers to make strategic decisions regarding crop selection and pricing.
-
Optimized Crop Planning: By accurately predicting crop yields, farmers can optimize planting schedules and crop rotations to maximize productivity.
-
Resource Allocation: Precise yield forecasts enable efficient allocation of resources such as water, fertilizers, and pesticides, reducing waste and environmental impact.
-
Sustainable Agriculture Practices: By optimizing resource usage and minimizing waste, Generative AI contributes to the promotion of sustainable agriculture practices, ensuring long-term environmental stewardship.
Benefits of Using Generative AI on Databricks for Precision Farming
-
Enhanced Accuracy: Generative AI algorithms, trained on both real and synthetic data, yield more accurate predictions compared to traditional methods.
-
Improved Scalability: Databricks' scalable architecture allows for the analysis of large-scale agricultural datasets, enabling farmers to make data-driven decisions at scale.
-
Cost-Effectiveness: By reducing the reliance on manual observation and experimentation, Generative AI on Databricks helps minimize operational costs while maximizing productivity.
-
Adaptability to Dynamic Conditions: Generative AI models can adapt to changing environmental conditions, ensuring robust predictions even in unpredictable climates.
Challenges and Future Directions
Predicting crop yields is a complex task with various challenges and exciting future directions. Here are some of the challenges and future directions in this field:
Challenges:
-
Data Partitioning: How we divide our data into training and testing sets can significantly affect the accuracy of our crop yield predictions. Different partitioning methods may yield different results, making it crucial to choose the most suitable approach.
-
Algorithm Selection: Choosing the right algorithm and parameters for our predictive models requires careful consideration. For example, in some studies, the Random Forest algorithm outperformed artificial neural networks and other models, highlighting the importance of selecting the most appropriate algorithm for the task.
-
Weather Forecasting: Accurate predictions rely heavily on weather forecasts. However, errors in seasonal weather forecasting can impact the reliability of crop yield predictions. It's essential to account for these uncertainties to improve the accuracy of our models.
-
Data Requirements: Utilizing AI algorithms for crop yield prediction often requires additional data. It's essential to assess whether the benefits of using these algorithms justify the costs associated with collecting and processing the required data.
Future Directions:
-
Machine Learning Guidelines: Establishing guidelines for the ethical and fair use of machine learning in crop yield prediction is crucial. These guidelines can help ensure transparency and accountability in the development and deployment of predictive models.
-
Improved Estimation Techniques: Combining crop growth models with remote sensing data holds promise for enhancing our understanding of the crop growth process and improving yield estimation.
-
Genotypic Data: Advances in genetic technologies enable the rapid and accurate screening of genotypic data for various crops. Incorporating genotypic data into predictive models can lead to more precise and personalized yield predictions.
-
Sustainable Practices: Sustainable agriculture practices are essential for minimizing the negative environmental impact of crop production. Emphasizing sustainable practices in crop yield prediction can help promote eco-friendly farming methods and ensure long-term agricultural sustainability.
Conclusion
In conclusion, leveraging the capabilities of Databricks platform for crop yield prediction presents a promising avenue for addressing the challenges and exploring the future directions in this field. The platform's robust data processing and analysis tools enable researchers and practitioners to effectively handle diverse datasets, including high-resolution crop maps, satellite imagery, weather data, and soil information. Furthermore, Databricks' support for machine learning algorithms facilitates the development and training of predictive models, allowing for the exploration of various algorithms and parameter configurations to optimize prediction accuracy.
As Databricks continues to evolve and innovate, it offers an ideal environment for researchers, data scientists, and agricultural stakeholders to collaborate, experiment, and deploy cutting-edge crop yield prediction solutions. By harnessing the power of the Databricks platform and staying abreast of advancements in the field, we can make significant strides toward improving crop yield prediction accuracy and supporting sustainable agricultural practices globally.
-
Know more about Generative Adversarial Network Architecture
-
Explore more about How to Build a Generative AI Model for Image Synthesis



