
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Cloud Native Storage Solutions: Efficient Data Management
Cloud-native is a new paradigm for developing and running software applications that incorporates technological trends such as cloud computing, containerization, serverless, and microservices. Cloud native storage is a type of storage technology intended for use in a cloud-native environment.
A cloud native storage platform manages data for stateful applications and solves ongoing data storage challenges in Kubernetes or other cloud native infrastructure-based cloud native environments. Object storage solutions in a distributed architecture can be based on modern object storage technology, block storage, or traditional disk drives.
Cloud-native storage solutions leverage Kubernetes to provide scalable, flexible, and efficient data management. Object storage, a key component, ensures high availability and durability, catering to diverse workloads. Key characteristics include elasticity, automation, and seamless integration into cloud-native infrastructure, enabling businesses to efficiently store and manage their data in the cloud.
What are the Key Features of Cloud Native Storage?
The basic key features of Cloud Native Storage are mentioned below:
Availability
It must be available in high demand. The storage system has the feature through which it also accesses the data even when an event fails—whether in the transmission system, storage medium, controller, or other components. Storage availability provides three elements:
- On other storage devices, it maintained the replicated copies of data.
- In any case of Failure, the redundant devices handle the failover.
- Failed Components can be healed and restored.
- Recovery time object (RTO): It is the time from failure to the restoration of service.
- Recovery point objective (RPO): How recent is the latest copy of data? It affects most of the data that can be lost in the case of failure.
- Percentage of uptime: % of the total time the service is up and available.
- Meantime between failures (MTBF): How often faults occur.
- Meantime to recovery (MTTR): How much time it takes the service to recover from failure.
A Cloud Native database is a sort of database service used to build, deploy, and deliver through cloud platforms. Click to explore Cloud Native Databases on Docker and Kubernetes.
Scalability
Cloud Native Storage can be scalable easily. The storage system scalability can be defined in four dimensions:
-
Client Scalability: through which we have the ability to increase the strength of clients and users who access the storage system.
-
Throughput Scalability: the ability to run with more throughput, measured in MB/sec or GB/sec, or using the same interface for many operations per second.
-
Capacity Scalability: it has the ability to increase the storage capacity of storage systems in a single deployment
-
Cluster Scalability: it has the ability to increase the storage components by adding more components as needed
Storage Performance
It should support predictable, scalable performance and service levels which are typically measured from the following perspectives.
- Time to Complete Read/Write Operation.
- A maximum number of storage operations per second.
- The throughput of data can be stored or retrieved in MB/s or GB/s.
Consistency
Cloud Native Storage considered support consistency as follows:
-
After the write, update, or delete operations, read operations should return the correct and updated data.
-
The system should be called "strongly consistent" if there is no delay between the modification of data and the availability of new data to read operations by clients.
-
The system is "eventually consistent" if there is a delay until read operations return the updated data.
In a consistent system, read delay can be considered a recovery point objective (RPO) because it represents the most data loss in case of component failure.
Durability
It should be durable because it protects the data against any loss. It goes beyond accessibility which describes the system's ability to ensure that the data remains can be stored for an extended period. Some factors affect the durability of a storage system:
-
Layers of Data protection, such as several data copies available.
-
Level of redundancy- local redundancy, redundancy to a remote site, redundancy over public cloud availability zones, & redundancy over regions.
-
Durability characteristics of storage media- for example, SSD, rotating disk, tapes.
-
The system's ability to detect corruption due to component failure, wear out of social media & so on & automatically reconstruct or restore corrupted data.
Dynamic Deployment
Dynamic deployment is the final desired criterion for cloud-native storage systems that can deploy or provision them quickly as per requirement. It can also be deployed and instantiated in a variety of ways, which includes
-
Hardware Deployment:- Physical storage equipment deployed in the data center. It uses this deployment model to build standardized components which can be added to the cluster with no special configuration, swapped, and removed when needed.
-
Software Deployment: Storage components are defined as software components on commodity hardware, devices, or cloud instances. Cloud-native software solutions can typically be installed in both local and cloud environments. Some software-defined storage systems are built as containers and can be deployed automatically using orchestrators.
-
Cloud Service: These cloud services should be managed by the public cloud providers & delivered as a service, with the abstraction of the underlying storage implementation. By using a web interface or API, the user provisions new instances or additional storage.
What are the Cloud Native Storage Fundamentals?
When we talk about the cloud native development and deployment of an application, we should also take care of the cloud native infrastructure and the storage part. An application's deployment process will not accomplish until it does not have any cloud storage characteristics attached to the application. As the application gets traffic and data from different sources, it is necessary to attach storage during the application's deployment to save, and desired operations can perform on that data. Some key considerations include scalability in cloud storage, availability in cloud storage, storage performance, and durability in cloud storage, which can be helpful to decide some specific parameters:
Scaling
An application runs to provide a service. Running an application requires resources to be configured as per requirements. The scaling depends upon the resources of an application. The application is scaled up and scaled down based on the usage of resources. Here the scaling means not only to scale the application by running its multiple replicas, but the resources provided to an application should also be scalable.
Resiliency
If the application runs, failures will also occur due to any interruption. After a failure, the application's new replicas may start on another node or in a different zone or data center. In such cases, there should be a data service that can provide access to the application whenever it comes up after restart. The failure can be in a microservice, or it can be a node failure. To make data available in such situations, we need a data service to support microservices' resiliency.
Isolation
Multitenancy provides the sharing of resources to run multiple applications. In the case of a cloud native premise, a variety of applications run on the same infrastructure. It means, applications with different dependencies and requirements run on the same infrastructure and share the same resources. In such cases, the isolation should take care of for applications and their data and security.
Tiering
Tiering can be done as per the requirement of the application. In simple words, tiering can be prioritized for a particular application according to its need. For example, the tiering can be done by taking care of required access by applications. Some applications may require high-level access, or some may need low-level access. The cloud tiering includes data lifting from on promises to cloud-based upon the defined policies for access.
Mobility
Mobility is necessary not only for application workloads but also for data. For efficient migration and replication, efficient data mobility must be there for application mobility.
Models of Cloud Native Storage Solutions
The best solutions to cloud native storage are defined below:
Cloud Storage for Public
Public Clouds can provide a range of cloud native storage options, which include object storage (such as Amazon S3 or Azure Blob Storage), cloud-based file shares ( such as Amazon EFS or Azure Files), and managed disk attached to compute instances ( such as Amazon EBS or Azure Managed Disks)
Cloud Storage for Business
Whenever organizations build private clouds, they often turn to commercial cloud storage services that provide easy scalability, high reliability, and convenience. Most of the services offer post-production support and operations & maintenance (O&M) services. As demand for cloud native storage grows, private cloud infrastructure vendors offer the most mature cloud native interfaces that allow on-premises resources to consume cloud storage.
Storage Services that is self-maintained
Mainly two types of storage services companies can build in-house: block storage and simple file storage. Ceph RBD & storage area networks (SAN's) are considered relatively mature solutions for block storage. However, due to their complexity, they often require specialized support and maintenance teams.
Services like GlusterFS, NFS, and CephFS provide file storage services for those companies who decide to create their own distributed storage systems. As NFS is relatively mature, which is insufficient to address the high-performance application requirements. GlusterFS and CephFS often cannot meet the performance and reliability needed for mission-critical applications.
A new trend in on-premises cloud-native storage is S3-compatible storage, which involves local storage devices that support the S3 API.
Local Storage
There are so many use cases in cloud-native applications which doesn't make any sense to use a distributed storage service. Two most common cases in which edge devices or components in a cloud-native system use local storage:
-
Databases: cloud native applications still use traditional databases, both SQL and NoSQL. In many cases, cloud native storage provides the throughput and the high performance required for production databases. So databases may already be replicated or set up for redundancy, making high availability built into cloud native unnecessary.
-
Caching: In most cases, components use local storage as a cache for temporary information, which is not necessary to persist to protect the data. Ephemeral storage is the most common example used by the containers, which is erased when the container shuts down.
Addressing Infrastructure Challenges
Kubernetes services can help to reduce the complexity and skills required to manage large container deployments. When IT professionals evaluate their technology roadmaps, one of the essential criteria is streamlining the infrastructure that supports Kubernetes workloads. Many Kubernetes users included their current storage and cloud vendors on their cloud native shortlists. Then it appeared that users were having difficulty narrowing that list.
Cloud providers exposed block storage through storage classes and dynamic provisioning with the rise of managed Kubernetes. Customers could connect to AWS Elastic Block Store (EBS) volumes, Azure-managed discs, Google Persistent Disks, and Kubernetes worker nodes running on AWS, GCP, and Microsoft Azure. This provided an advantage to cloud providers.
When asked which cloud native storage services they use, Kubernetes users cited Amazon EBS, Google Persistent Disk, and Azure Disk Storage as the most popular. In many cases, StatefulSets enabled cluster workloads to access the cloud provider's block storage. As they are widely used, the block storage from large cloud providers was not explicitly designed for Kubernetes workloads.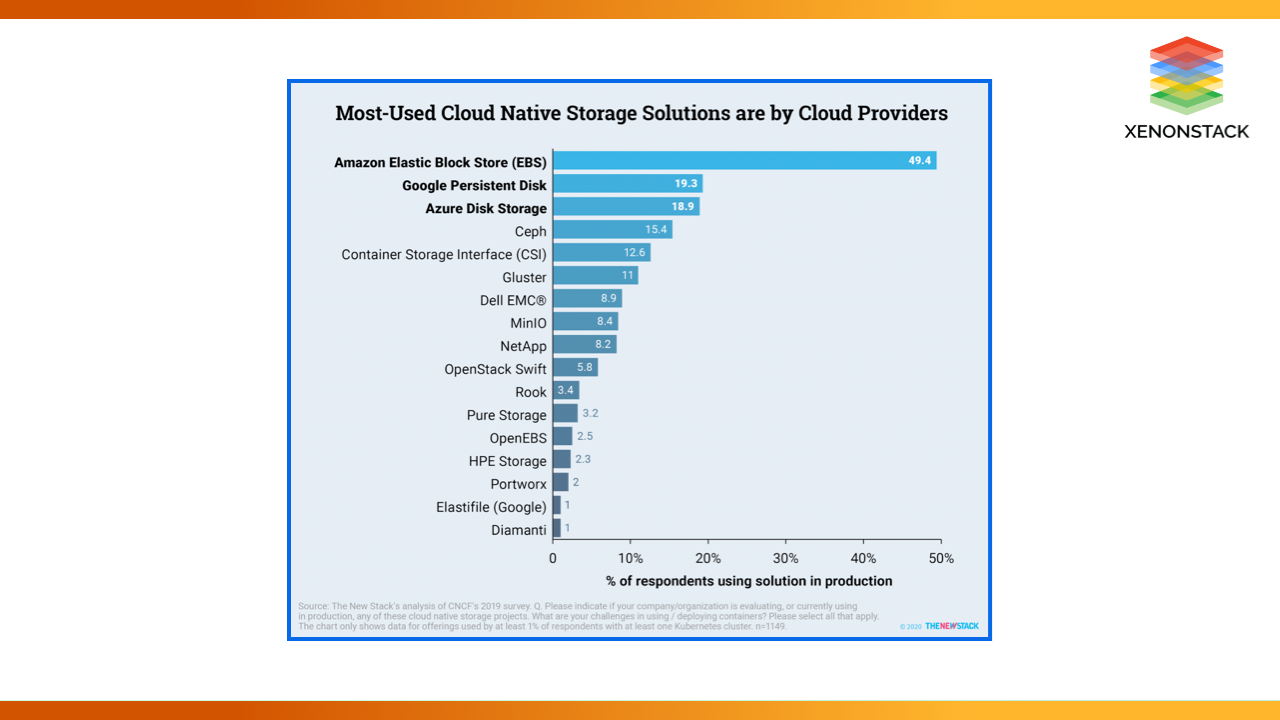
Customers of traditional storage companies were far more likely to complain about storage issues. For example, 46 percent of Pure Storage customers reported difficulties with container-related storage, compared to 27 percent of the average Kubernetes user. While some were considering established companies, open-source projects were top of mind for those looking for new storage options.
When compared to the average respondent, the 27 percent of Kubernetes users who faced storage challenges were more likely to consider Rook (26 percent vs. 16 percent ), Ceph (22 percent vs. 15 percent ), Gluster (15 percent vs. 9 percent ), OpenEBS (15 percent vs. 9 percent ), and MinIO (13 percent vs. 9 percent ). These open-source efforts were notable for not being motivated by a desire to sell hardware.
Users were more likely to cite storage challenges for traditional storage companies and the newer breed of uniquely cloud native storage offerings. While many users of newer offerings, such as MayaData's OpenEBS, Minio, and Portworx, reported storage issues, they most likely referred to problems connecting legacy data stores. On the other hand, traditional storage companies addressed their customers' concerns by implementing new approaches such as CSI.
Choose the Right Cloud Native Storage Solutions
Cloud-native storage offers high-performance storage for Kubernetes Deployments. As a result, it provides common data management and security workflows across hybrid and multi-cloud deployments. Many Kubernetes storage platforms can adapt to technological changes and changing customer needs without forklift upgrades. Manage your enterprise data more effectively and affordably than ever before.
- Discover about Developing Cloud Native Services with Open Policy Agent
- Click to explore Cloud Native Applications Design and Architecture
- Explore more about Cloud Analytics and Visualization Solutions


























