.webp?width=1921&height=622&name=usecase-banner%20(1).webp)

Best Practices of Hadoop Infrastructure Migration
Migration involves the movement of data, business applications from an organizational infrastructure to Cloud for -- Recovery
- Create Backups
- Store chunks of data
- High security
- Reliability
- Fault Tolerance
Challenge of Building On Premises Hadoop Infrastructure
- Limitation of tools
- Latency issue
- Architecture Modifications before migration
- Lack of Skilled Professional
- Integration
- Cost
- Loss of transparency
Service Offerings for Building Data Pipeline and Migration Platform
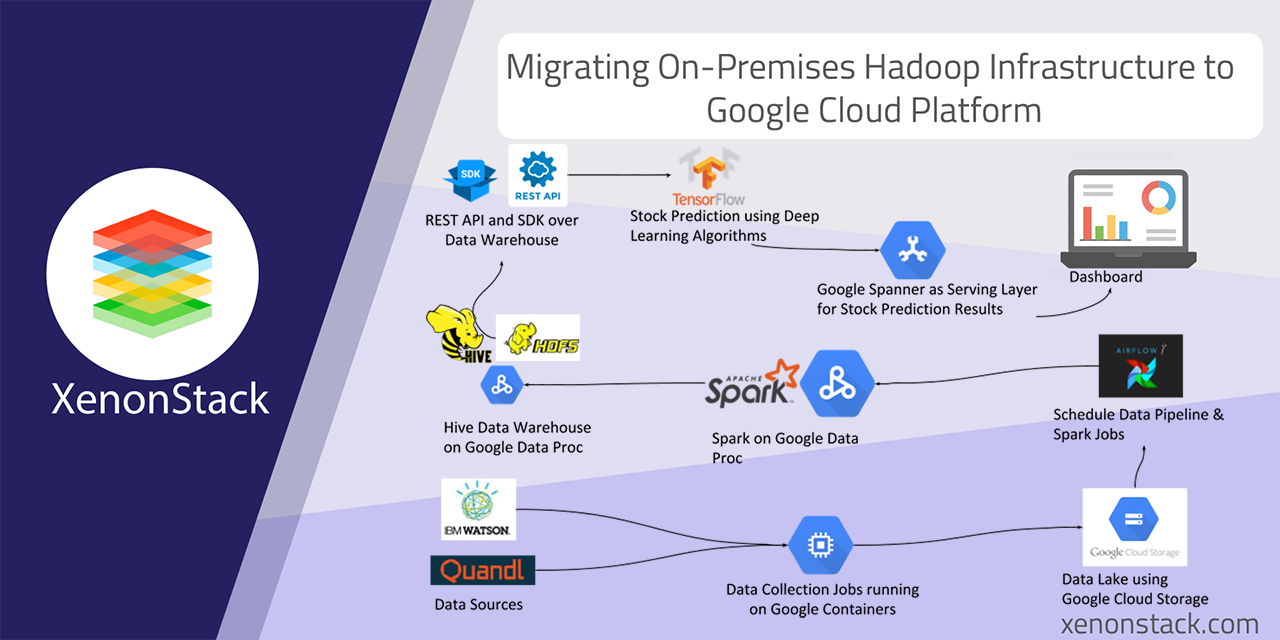
Understand requirements involving data sources, data pipelines, etc. for the migration of the Platform from On-Premises to Google Cloud Platform.- Data Collection Services on Google Compute Engines. Migrate all Data Collection Services and REST API and other background services to Google Compute Engine (VM’s).
- Update the Data Collection Jobs to write data on Google Buckets. Develop Data Collections Jobs in Node.js and write data to Ceph Object Storage. Use Ceph as Data Lake. Update existing code to write the data to Google Buckets hence use Google Buckets as Data Lake.
- Use Apache Airflow to build Data Pipelines and Building Data Warehouse using Hive and Spark. Develop a set of Spark Jobs which runs every 3 hours and checks for new files in Data Lake ( Google Buckets ) and then run the transformations and store the data into Hive Data Warehouse.
- Migrate Airflow Data Pipelines to Google Compute Engines and Hive on HDFS using Cloud DataProc Cluster for Spark and Hadoop. Migrate REST API to Google Compute Instances.
- The REST API served as Prediction results to Dashboards and acts as Data Access Layer for Data Scientists migrated to Google Compute Instances (VM’s ).
Technology Stack -
- Node Js based Data Collection Services (on Google Compute Engines)
- Google Cloud Storage found Data Lake (storing raw data coming from Data Collection Service)
- Apache Airflow (Configuration & Scheduling of Data Pipeline which runs Spark Transformation Jobs)
- Apache Spark on Cloud DataProc (Transforming Raw Data to Structured Data)
- Hive Data Warehouse on Cloud DataProc
- Play Framework in Scala Language (REST API)
- Python based SDKs
Best Practices for Building Data Warehouse
Apache Hive is data warehouse used for analyzing, querying and summarising data. Apache Hive converts queries into Mapreduce jobs. Data Warehouse implementation comprises of ETL process i.e. Extract, Transform and Load. Apache Spark is analytics framework for data processing which performs Real-Time, Batch and Advanced analytics.Apache Spark helps companies and markets to ingest data and run Machine Learning Models. Data Warehouse using Apache Hive- Import Data
- Design Data Warehouse
- Build Data Warehouse with Hive using Data Library
- Run Queries
- Extraction of Data
- Transformation of Data
- Loading of transformed data
- Data Visualisation