
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
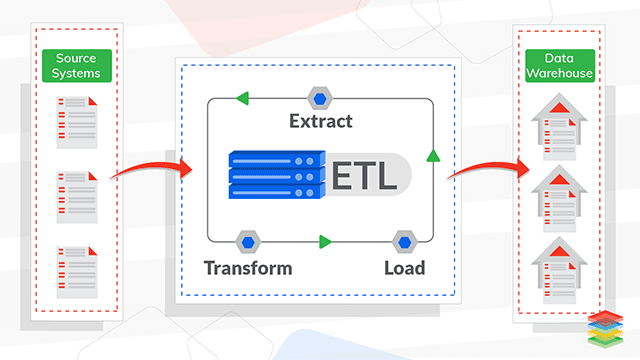
What is Continuous ETL?
It is a process to extract the data from a Homogeneous or Heterogeneous data source, then cleanse, enrich, and Transform the data, Which is further Load back to Lake or Data Warehouse. It is a well-defined workflow and an ongoing process. It is a near-to real-time process with latency in seconds, not in hours or days.What is Continuous ETL working architecture?
The number of data sources can be there from where information is extracted. Then numerous transformations can be applied to it. There is a continuous process of Extract, Transform and Load as the data comes. The following steps are required to make its process Continuous.Serverless Cloud Computing enables self-service provisioning and management of Servers. Click to explore about our, Serverless Solutions and Architecture for Big Data
Extract Process Overview
- Update notification - When the changes have been done helps to extract the data quickly. These types of systems are required for the continuous process.
- Incremental extraction - Incremental extraction is supported by the systems which can provide information about a record modification. When the system knows about record modification, it can extract the unread only.
- Full extraction - Some systems are not able to provide information about the last record changes, so reloading all the data is the only option. In these cases keeping track of the previous extraction is required. The continuous extraction is not preferable in this case as keeping track of the data is difficult in these kinds of systems.
- Transform - Architecturally; there are two ways to approach ETL transformation.
- Multistage data transformation -In multistage data transformation, the transformation occurs in the staging area before loading it to the warehouse.
- In-warehouse data transformation - Data is extracted and loaded into the warehouse, and transformations are done there.
Basic Transformations in ETL
- Cleaning - Date format consistency and mapping of the data.
- Deduplication - Remove duplicate values from the data.
- Format revision - Date/Time conversions unit conversions.
- Essential restructuring - Establishing key relationships across tables.
- Derivation - Creating new data using existing data by applying business rules – for example, creating a revenue metric from taxes.
- Filtering - Selecting only the specific row and columns from the data.
- Joining - Adding data into one stream from multiple sources.
- Splitting - Split the single columns into multiple columns.
- Data Validation - Simple or complex data validation – for example, reject the rows from processing if the first three columns in a row are empty.
- Aggregation - Aggregate data from multiple data sources and databases.
- Integration - Standardize each unique data’s name with one standard definition.
Loading in ETL
Ordering - Keeping data accurate is a critical step of loading data as there can be deletion updation operations in the data pipeline which can lead to the wrong updation in the process.
Schemas evolution - What happens if data warehouse starts receiving wrong data type for a field that is expected be an integer. This situation can be destructive, so schema evaluation is there in the loading process to make sure everything occurs smoothly.
Monitorability - When there is a large number of data sources, failures are inevitable. The failure can occur due to a number of reasons.
- Api’s downtime
- Api’s expiration
- Network congestion
- Warehouse offline
An Observability Platform for Monitoring, Logging, Tracing and Visualization of Big Data Cluster and Kubernetes. Click to explore about our, Observability for Kubernetes and Serverless
Why is Continuous ETL Important?
The word ‘Data’ matters most here. Data is generated in every business, and the need for getting insights from the information is increasing. People want to track and query a variety of data sources, but the traditional model built for structured data was inadequate. So conventional batch processing is too slow for making real-time decisions. So it makes sense for ever-growing businesses who want to move their data and operations in real-time.How to adopt Continuous ETL Architecture?
When the real-time data is generating using sensors or applications, The continuous ETL can be applied to get insights and real-time alerts for detecting an anomaly or suspicious security threats. The first step for Implementing it will be choosing the right kind of tools according to the use case and challenges. But before that, data modeling and partitioning strategy can decide for storing and querying the data efficiently. The source-of-truth pipeline is needed for feeding all data-processing destinations. It should also serve as a real-time messaging bus and stateful stream processing.What are Continuous ETL Advantages?
- Updated Data Warehouses
- Continuous & Real-time alerts and analytics
- Continuous operations on the data as it comes
- Enables low-latency data for time-sensitive analytics
With Serverless Architecture, developers don't need to worry about updating servers or runtimes. Click to explore about our, Building Applications with Serverless Architectures
What are the Best Practices of Continuous ETL?
Analyzing data: Analyzing the data will be the first step in the ETL best practice because having a mature data model will help in the long term.
Fixing data issues at source - The data issues should be set at the source end because the errors at the data source inevitably will affect the systems.
Efficient Partitioning - Based on the value of one or more columns, queries can be done more efficiently by reading only the relevant fraction of the total dataset.
Ensuring scalability - The scalability should be kept in mind when the solution is proposed. Because as the business grows, the system should be able to handle it gracefully.
Scheduling, Auditing & Monitoring ETL jobs - To ensure its jobs are done as per decided, scheduling and monitoring are essential.
What are the Best Tools for Continuous ETL?
- Apache Kafka - Apache Kafka serves as the real-time, scalable messaging bus for applications, with no EAI.
- Amazon Kinesis Data Stream - Amazon Kinesis Data Streams (KDS) is a massively scalable and durable real-time data streaming service.
- Amazon Kinesis Data Analytics - Analyze data, and gain actionable insights in real-time. It provides a serverless SQL query engine to join, aggregations over time windows, filters, and more.
- Amazon Kinesis Firehose - It loads streaming data into data stores and configures a delivery stream to automatically convert the incoming data to columnar forms like Apache Parquet and Apache ORC.
- Apache Flink - It support for stream and batch processing, sophisticated state management, event-time processing semantics, and exactly-once consistency guarantees for a state.
- Apache Airflow - Apache Airflow is useful for scheduling ETL jobs and monitoring & handling job failures efficiently.

Conclusion
Continuous ETL helps in extracting the data of different types which further clean, enrich and transform the data and load back to data warehouses with the latency in seconds. For any organization, data plays a crucial role and it is though difficult to manage. If you want to know more about this, you must explore each step mentioned below:- Read more about Real-time Data Streaming using Apache Spark
- Explore more about Modern Data Warehouses



