
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is AresDB?
AresDB is a GPU-powered real-time query engine that improves uber’s existing solutions too. Uber Engineers developed a unified, simplified solution as AresDB. Real-time data analytics is now the need for every organization to track real-time metrics and monitor them for fraud detection and ad hoc specific solutions. These issues are solved with real-time analytics solutions such as Azure Data warehouse, Redshift, etc. But then, a new issue arises to process that data on multiple factors such as columnar way or parallel way, but at a conveniently fast way.
Then, Apache comes with Pinot, which comes with distributed analytics database written in Java. But it doesn’t fit the Uber requirements for a GPU-based unified, simplified solution. It settles functional, scalability, performance, cost, and operational requirements at Uber.
AWS analytics is one of the broad and cost-effective services, offers multiple services on the cloud such as data warehousing, real-time analytics, and many more. Source: AWS Data Lake and Analytics Solutions
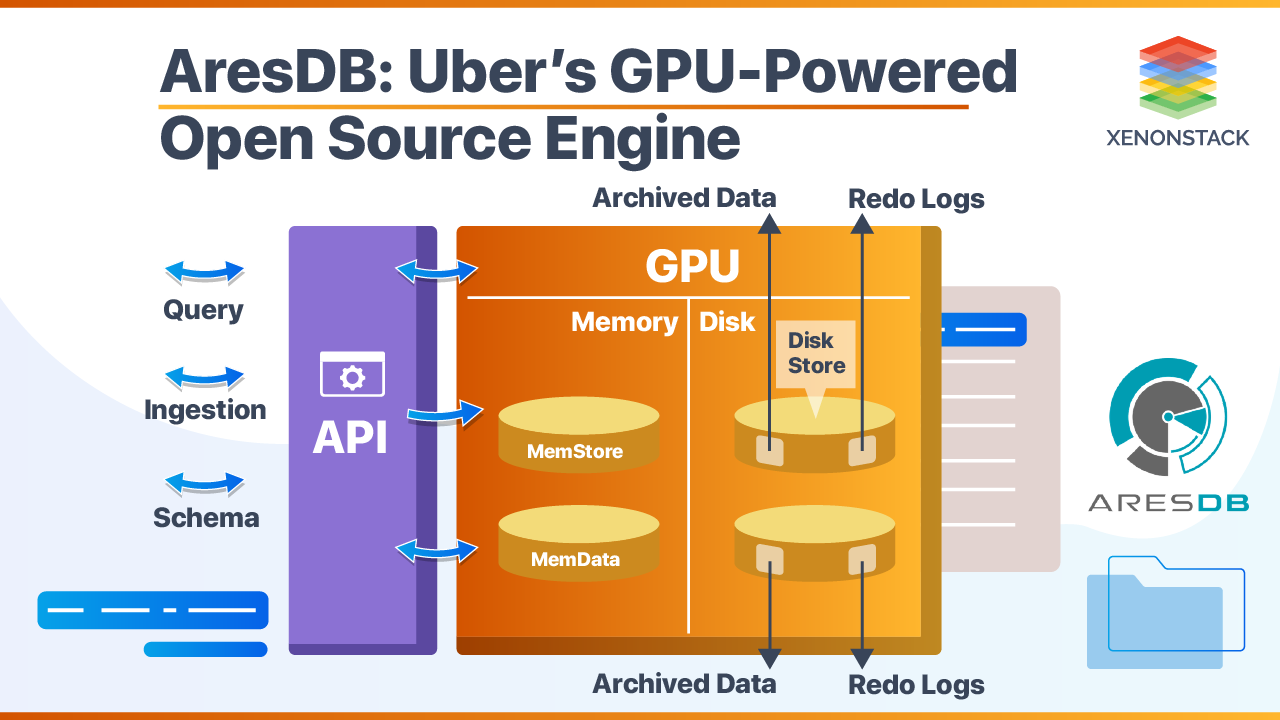
What is the architecture of AresDB?
AresDB consists of three main parts that define the overall performance of it. These are:
- Memory Store – (RAM as host memory)
- Disk Store – contains Archived data and Redo Logs
- Metadata Store – checkpoints information and DDL schema
GPU is the core for processing queries at a scale, but the above three are also the runners. It has no schema or database scope, the data is directly stored in tables. There are two tables used in it for storing data, i.e., Fact Table and Dimension Table. The Fact Tables grow infinite with respect to time, but dimension tables are size bounded. Fact tables also have a special event time column, unlike dimension tables.
- AresDB has two stores that help in tracking data. One is a Live store that stores real-time data, and the other is archive store stores compressed and mature data. Live store uses partitions batch system during ingestion, and once that batch partition is archived to archive store, it gets removed from the live store.
- String functions are not supported, but string records are converted into enum types before loading to tables.
- Stable records are moved into Fact tables from a live store to an archive store.
What are the steps data follow while being archived?
- First, data is sorted from low cardinality columns, and mostly high cardinality columns are discarded for this step.
- Data is then compressed in sorted form recursively for all sorted columns. Once a batch is processed, then data is merged with previously compressed data on disk.
- Data is snapshotted for certain conditions for dimension tables. The recovery process goes to megastore for the latest snapshot for a fast rebuild. Data is then backfilled, which makes data actually visible for queries.
An Open source, Data Ingestion and dispersal framework and library for Apache Hadoop, build on the top of the Hadoop ecosystem. Click to explore about our, Uber Marmaray Features and its Best Practises
What are the benefits of AresDB?
- GPU is used for real-time analytics processing that runs faster and processes queries smoothly. You would love to explore more about GPU in this blog.
- GPU is required for Query execution and processing.
- Highest compute-to-storage data accessing throughput as data is compressed.
- Includes schema alteration, partial updates (that were missing in Kinetica).
- Supports Deduplication (that was missing in omniscient).
- Automatic string conversion to Enumerated types before they enter into the database.
- JSON formatted Query Structure is known as Ares Query Language (AQL). AQL structure is used for Schema defining, querying data, and as query result also.
- It is a query efficient solution as less data is transferred from ALU to GPU during query Processing.
An Open source, Data Ingestion and dispersal framework and library for Apache Hadoop, build on the top of the Hadoop ecosystem. Source: Hadoop Data Ingestion and Dispersal Framework
Why is it important?
While data needs to be processed for faster queries, AresDB uses GPU for excessive fast query processing. Data is deduplicated, so less data needs to be transferred between ALU to GPU or from memory to memory GPU for processing. The schema of tables is defined in JSON format. For the Fact table, the first column is always the time column and of Uint32 type. There is no namespace for tables in it; thus, explicit data tables like Fact tables and Dimension tables are directly accessible to its instance or cluster. Columnar storage is used with low cardinality columns sorted first in order, and compression is based on that cardinality with deduplication. Hence, it is storage efficient also with many to one mapping support.
So, basic testing can be performed individually and at standalone instances. Time Filters expressions are used to filter data between date ranges. These three types of time filters, i.e., Absolute time filter, current time filter, and relative time in the past with respect to the current time. Backfilled Queue is used in memory that contains all late records. Once it is full, it blocks all proceedings until queue space is freed. You can also get an insight into M3DB in this piece of content.

Use Cases for AresDB
- Uber developed AresDB to improve their existing system for generating more accurate and real-time analytics on their real-time data. It helps Uber to build better dashboards, automated decisions, and ad hoc queries. AresDB helps in producing a more accurate user dashboard based on trips, fares, and time-based events. It also removes overhead to include more new third-party user applications to achieve such targeted goals.
- It can retain data for a specific range of dates as it has inbuilt functionality to retain data. Generally, it can be done by modifying data retention time in the JSON schema file of a table.

Conclusion
AresDB also encourages the use of GPU for real-time data analytics. Uber is now maintaining data at different nodes for monitoring and marketing purposes using it parallel processing approach on GPU. Learn more about Coroutines in this insight. It manages memory resources on its own, so there must be no error or delay occurs while processing the query. Query Engine of AresDB is written in C++, whereas memory store, disk store, and metadata store components are written in golang.
- Click to explore about Coroutines Benefits and its Use Cases
