
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Real-Time Event Processing with Kafka
As the industry grows, the production of products also increases in the changing scenario. This data can be a great asset to the business if analyzed properly. Most tech companies receive data in raw form, and it becomes challenging to process data. Apache Kafka, an open-source streaming platform, helps you solve the problem. It allows you to perform basic tasks like moving data from source to destination to more complex tasks like altering the structure and performing real-time aggregation on the fly. Real-time event Processing with Kafka in a serverless environment makes your job easier by taking the overhead burden of managing the server and allowing you to focus solely on building your application.
The new technologies give us the ability to develop and deploy lifesaving applications at unprecedented speed — while also safeguarding privacy. Source: Tracking People And Events In Real Time
Serverless Environment and Apache Kafka
Serverless is that form of computing architecture wherein all the computational capacities can transfer to cloud platforms; this can help increase the speed and performance. This serverless environment helps build and run applications and use various services without worrying about the server. This enables the developers to develop their applications by putting all their efforts towards the core development of their applications, removing the overhead problems of managing the server and using this time to make better applications.
Apache Kafka is an open-source event streaming platform that provides data storing, reading, and analyzing capabilities. It has high throughput reliability and replication factor that makes it highly fault-tolerant. It is fast and scalable. It is distributed, allowing users to run it across many platforms, thus giving it extra processing power and storage capabilities. Initially built as a messaging queue system, it has evolved into a full-fledged event streaming platform.
Different use cases of Kafka are:
-
Messaging
-
Web activity tracking
-
Log aggregation
-
Event sourcing
-
Stream processing
How does Apache Kafka Work?
Kafka acts as a messenger sending messages from one application to another. Messages sent by the producer (sender) are grouped into a topic that the consumer (subscriber) subscribed to as a data stream. 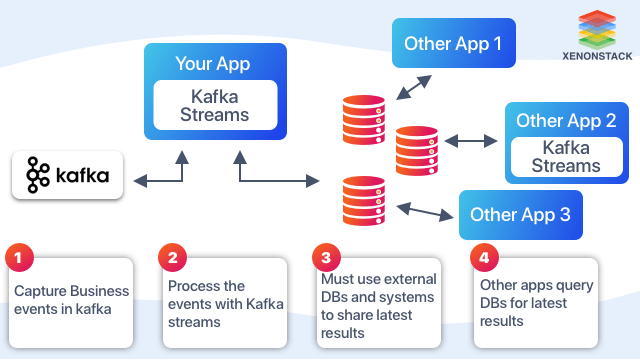 Kafka Stream API And KSQL for Real-time Event Streaming - Kafka Stream is a client library that analyzes data. The stream is a continuous flow of data that is to be analyzed for our purposes. It helps us read this data in real time with milliseconds of latency, allowing us to perform some aggregation functions and return the output to a new topic. The picture below shows how an application using the Apache Kafka stream library works.
Kafka Stream API And KSQL for Real-time Event Streaming - Kafka Stream is a client library that analyzes data. The stream is a continuous flow of data that is to be analyzed for our purposes. It helps us read this data in real time with milliseconds of latency, allowing us to perform some aggregation functions and return the output to a new topic. The picture below shows how an application using the Apache Kafka stream library works.
Kafka Stream and KSQL features
-
High scalability, elasticity, and fault tolerance
-
Deploys on cloud and VMs
-
Write standard java/scala application
-
No separate cluster is needed
-
It is viable for any case, small, medium, large
KSQL streaming SQL engine for Apache Kafka KSQL is a streaming SQL engine for real-time event processing against Apache Kafka. It provides an easy yet powerful interactive SQL interface for stream processing, preventing you from writing any Java or Python code.
Different use cases of KSQL
-
Filtering Data: Filtre the data using a simple SQL-like query with a where clause.
-
Data Transformation and Conversion: KSQL makes data conversion very handy. Converting data from Jason to Avro format can be easy.
-
Data Enrichment with Joins: With the join function's help, to enrich data.
-
Data manipulation with scalar function: Analyzing data with aggregation, processing, and window operation can perform various aggregation functions, like sum count average, on our data. If we want the data for the last twenty minutes or the previous day, that can also be done using a window function.
Read more about Apache Kafka Security with Kerberos on Kubernetes.
Features of KSQL
-
Develop on mac Linux and windows
-
Deploy to containers cloud and VMS
-
High scalability, elasticity, and fault tolerance
-
It is viable for any case, small, medium, large
-
Integrated with Kafka security
Kafka on AWS, Azure and GCP
Kafka on AWS
AWS provides Amazon MSK, a fully managed service that allows you to build Apache Kafka applications for real-time event processing. Managing the setup and scale of Apache Kafka clusters in production might be tedious. Once you run it on your own, you would like to provision servers, configure them manually, replace server failures, integrate upgrades and server patches, create the cluster to maximize availability, ensure data safety, and plan to scale events from time to time for supporting load changes. Amazon MSK makes it a cakewalk to create and run production applications on Apache Kafka without its infrastructure management expertise, taking the weight off your shoulders to manage infrastructure and focus on building applications.
Benefits of Amazon MSK
-
Amazon MSK is fully compatible with Apache Kafka, which allows you to migrate your application to AWS without making any changes.
-
It enables you to focus on building applications, taking on the overhead burden of managing your Apache Kafka cluster.
-
Amazon MSK creates multi-replicated Kafka clusters, manages them, and replaces them when they fail, thus ensuring high availability.
- It provides high security to your cluster.
Before discussing how Kafka works on Azure, let us quickly get insight into Microsoft Azure.
What is Microsoft Azure?
Azure is a set of cloud services provided by Microsoft to meet your daily business challenges by giving you the utility to build, manage, deploy and scale applications over an extensive global platform. It provides Azure HDinsight, which is a cloud-based service used for data analytics. It allows us to run popular open-source frameworks, including Apache Kafka, with effective cost and enterprise-grade services. Azure enables massive data processing with minimal effort, complemented by an open-source ecosystem's benefits. QUICKSTART: Create a Kafka cluster using the Azure portal in HDInsight. To create an Apache Kafka cluster on Azure HDInsight, follow the steps below.
-
Sign in to the Azure portal and select + create the resource
-
To go to create the HDInsight cluster page, select Analytics => Azure HDInsight
-
From the basic Tab, provide the information marked (*)
-
Subscription: Provide Azure subscription used for cluster
-
Resource group: enter the appropriate resource group(HDInsight)
-
Cluster detail: provide all the cluster details (cluster name location type)
-
Cluster credential: give all the cluster credentials (username, password, Secured shell (SSH) username)
-
For the next step, select the storage tab and provide the detail
-
Primary storage type: set to default (Azure)
-
Select method: set to default
-
Primary storage account: select from the drop-down menu your preferences
-
Now, for the next step, select the security + networking tab and choose your desired settings
-
In the next step, click on the configuration + pricing tab and select the number of nodes and sizes for various fields ( zookeeper = 3, worker node = 4 preferred for a guarantee of Apache Kafka )
-
The next step is to select review + create (it takes approx 20 min to start cluster)
Command to connect to the cluster: ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net
Kafka on Azure
-
It is managed and provides simplified configurations
-
It uses an Azure-managed disk that provides up to 16 storage per Kafka broker
-
Microsoft guarantees 99.9% SLA on Kafka uptime (service level agreement)
Azure separates Kafka's single-dimension view of the rack to a two-dimension rack view (update domain and fault domain) and provides tools to rebalance Kafka partitions across these domains
Kafka for Google Cloud Platform (GCP)
Following Kafka's huge demand in its adoption by developers due to its large scalability and workload handling capabilities, almost all developers are shifting towards stream-oriented applications rather than state-oriented ones. However, breaking the stereotype that managing Kafka requires expert skills, the Confluent Cloud provides developers with Kafka's full management. The developers need not worry about the gruesome work of managing it. This is built as a 'cloud-native service' that provides the developers with a serverless environment with utility pricing that offers the services, and the pricing is done by charging for the stream used. The Confluent Cloud is available on GCP, and the developers can use it by signing up and paying for its usage. Thus, it provides the developers with an integrated billing environment using the metered GCP capacity. The use of tools provided by Confluent clouds, such as Confluent Schema Registry, BigQuery Collector, and support for KSQL, can be done by this subscription, enabling the developers to take care of the technical issues or write their codes.
How Kafka works on Amazon MSK ?
In a few steps, you can provide your Apache Kafka cluster by logging on to Amazon MSK to manage your Apache Kafka cluster integrate upgrade, which lets you freely build your application. 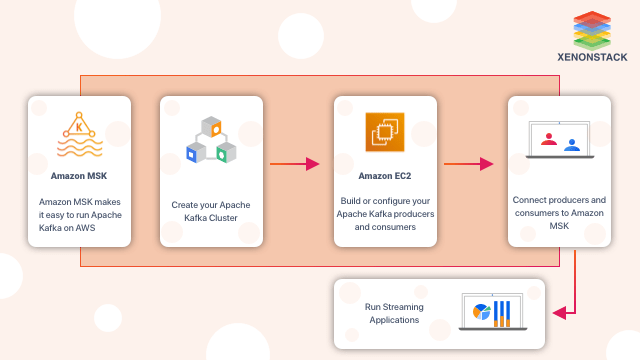
What are the Steps to Deploy Confluent Cloud?
The steps to deploy the confluent cloud are given below.-
Spin up Confluent Cloud: Firstly, the user needs to log in and select the project where the user needs to spin up Confluent Cloud and then select the 'marketplace' option.
-
Select Confluent Cloud in Marketplace: In Marketplace, select Apache Kafka on the Confluent cloud.
-
Buy Confluent Cloud: The Confluent Cloud purchase page will appear. The user can click on the 'purchase' button to purchase it.
-
Enabling Confluent Cloud on GCP: Enable the API for usage after purchasing the Confluent Cloud. Click on the 'enable' button after the API-enabled page opens.
-
Register the Admin User: The user should register as the cloud's primary user by going to the 'Manage via Confluent' page. Then, the user needs to verify the email address.
After all these steps, the user will log in to his account. In this case, the user needs to make some decisions regarding the clusters, but it is not as complicated as the ones wherein the users manage Apache Kafka independently. Thus, it makes developing event-streaming applications easier and provides a better experience.
Click to explore the Managed Apache Kafka Services.
So, in a nutshell, we can say that Real-Time Event Processing with Kafka has huge demand in its adoption by developers due to its extensive scalability and workload handling capabilities; almost all the developers are shifting towards stream-oriented applications rather than state-oriented. Combining this with a serverless environment makes it a piece of art with the reduced burden of managing the cluster, letting us focus more on the development and leaving most of the working part in a serverless environment.
- Explore more about Real Time Data Streaming with Kafka
- Read more about Top Real Time Analytics Use Cases
More Ways to Explore Us
Real-Time AI Development Services
Real Time Data Streaming
Real Time Analytics Tools and Benefits



