
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Overview of Big Data Analytics Infrastructure
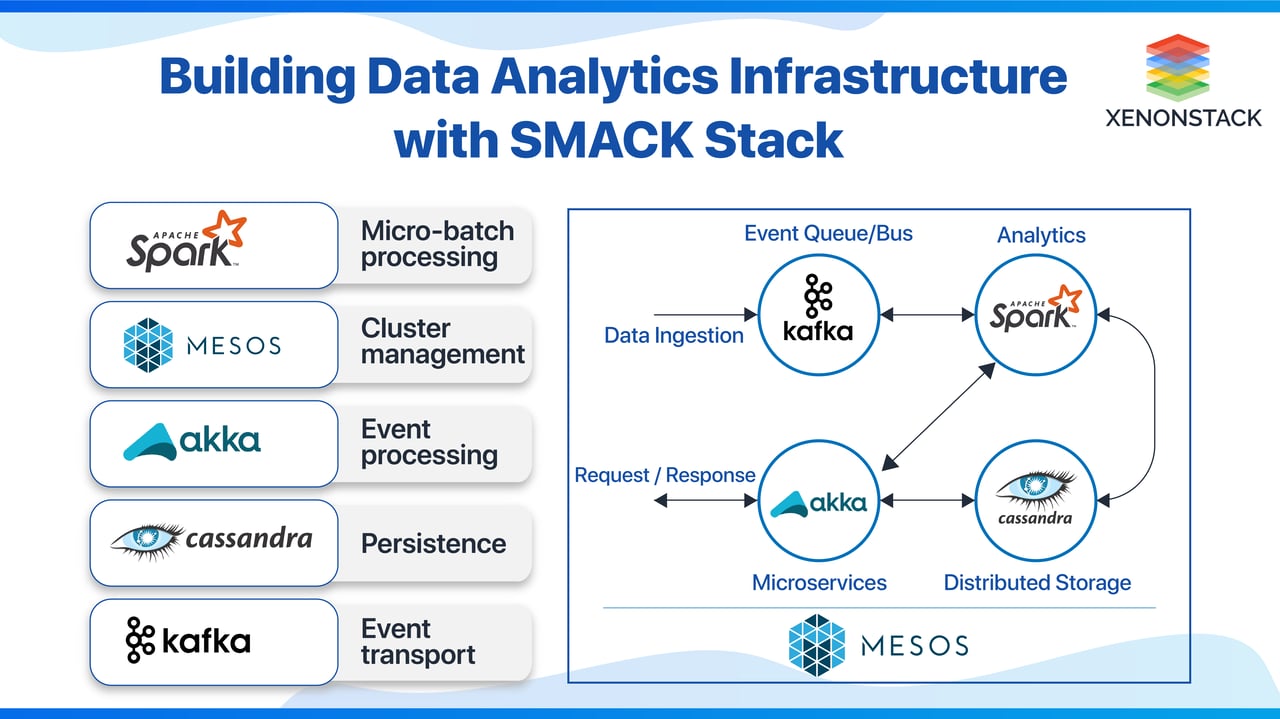
Building Data Analytics Infrastructure with SMACK Stack using the following terms - S - stands for Apache Spark, used for Batch Processing or Real-Time Data Streaming. M - stands for Apache Mesos, responsible for installation and administration. A - stands for Akka for Data Streaming and Data Ingestion at a faster pace. C - stands for Cassandra database to write and read the stored data. K - stands for Apache Kafka to perform decoupling and reduction of overhead.The challenge for Building the Analytics Platform
Power Scalable Real-Time & Data Driven Application. Build a system of Real-Time insights to create new opportunities and deliver new value. Ingest Data at a scale without loss. Trigger actions based on the analyzed data, and store the data at Cloud-scale.
Solution for Building Infrastructure with SMACK Stack
The SMACK stack builds modern enterprise apps because it performs each of these objectives with a loosely coupled toolchain of technologies that are all open-source and production-proven at scale.
- Spark – A general engine for large-scale Data Processing, enabling analytics from SQL queries to Machine Learning, Graph Analytics, and Stream Processing.
- Mesos – Distributed systems kernel that provides resourcing and isolation across all the other SMACK stack components. Mesos is the foundation on which other SMACK stack components run.
- Akka – A toolkit and runtime to easily create concurrent and distributed apps that are responsive to messages.
- Cassandra – Distributed database management system that can handle a large amount of data across servers with high availability.
- Kafka – A high throughput, low-latency platform to handle Real-Time data feeds with no data loss.



