
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Metacat API
Metacat API is an Application Programming Interface provides an interface and helps connect the two applications and enable them to communicate with each other. Whenever we use an application or send a request, the application connects to the internet and sends the request to the server, and the server then, in response, provides the fetched data. The data set at any organization is stored in different data warehouses like Amazon S3 (via Hive), Druid, Elasticsearch, Redshift, Snowflake, and MySql.Spark, Presto, Pig, and Hive are used to consume, process, and produce data sets. Due to numerous data sources and to make the data platform interoperate and work as a single data warehouse Metacat was built. Metacat is a metadata exploration Application Programming Interface service. Metadata can be termed as the data about the data. Metacat explores Metadata present on Hive, RDS, Teradata, Redshift, S3, and Cassandra.A messenger that brings your request to the provider whom you are requesting and returns a response. Click to explore about our, Top 4 API Authentication Methods
What are the types of API?
WEB API (can be accessed through HTTP protocol) in this, we define the endpoint, valid requests, and response data. The web API's can be combined to form a composite of it.
- Open API: These are public and can be used by any developer with minimum restrictions. They are meant for external users.
- Internal API- These are hidden from an external user. It is meant to be used by the people under that organization and is used for different teams to communicate and transfer data, tools, and programs.
- Partner's API- These are similar to Open API, but they have restricted access, and they are generally controlled through a third party gateway. It is common in the SaaS ecosystem.
- Composite API- It is the which accesses multiple endpoints or multiple services or the data sources, though a single Application Programming Interface.
The primary purpose of Metacat is to give a place to describe the data so that we could do more useful things with it. Source: Metacat focusses on solving which problems?
What is the architecture and protocol of API?
The protocol defines the data types and the command accepted, and different API architecture have different protocols associated with them.
Rest: It stands for the Representational State Transfer, and this architecture is widely used in Application Programming Interface. For it to be REST, it needs to follow specific protocols that are:
- Client-Server Architecture: as the interface is separated from backend and data storage, they have the flexibility to evolve independently
- Statelessness: In between requests, the client context is not stored on the server.
- The client can cache the response, so REST Application Programming Interface informs whether the response can be cached or not.
- It can communicate directly with the server and communicate through a layered system like a load balancer.
The soap satisfies:
- It relies heavily on XML
- With XML and schema, it is a very strongly typed messaging framework.
- How to structure SOAP message.
- Every operation's XML request and response is explicitly defined.
GET: Used to get data from the server. It is reading the only method, and hence it doesn't change or corrupt the data.
POST: It sends the data to the server and creates a new server resource. When the resource gets posted, the Application Programming Interface will assign the URI(Uniform Resource Identifier ) to the resource.
PUT: It is used often to update the existing resource. The PUT method can be called to the URI, which is updated, and the new version of the help is present in the request body.
PATCH: The patch method is similar to the PUT method, but PATCH in the requested body only needs specific resource changes. The Application Programming Interface services will create the new version according to that instruction.
DELETE: The DELETE request deletes a specific resource from the resource.
A query based language for REST APIs used to retrieve the exact data needed. Click to explore about our, Apollo GraphQL Features and Tools
What are the benefits of Metacat API?
Listed below are the benefits of Metacat Application Programming Interface:- Metacat provides a unified REST/Thrift interface to access metadata of data sources.
- The metadata stores of respective data sources are still the source for the schema of Metadata.
- Only the business and user-defined metadata about the dataset are stored.
- It provides the information about the dataset to Elasticsearch for full-text search and data discovery.
- Metacat is a repository of metadata and data, which enables scientists and data analysts to find, understand and effectively use the data set.
- Metacat provides a vast amount of data to work on as the data which is well documented can be easily searched, compared, merged, and used as needed.
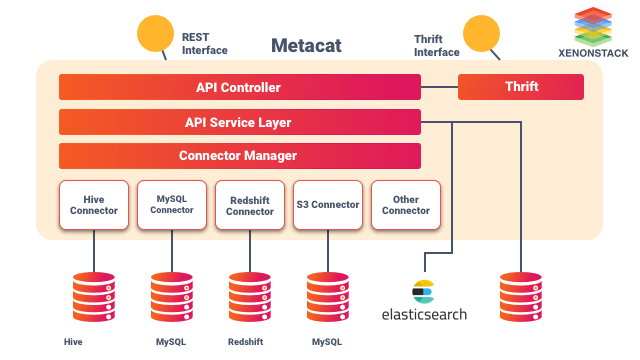
What are the main objective of Metacat?
The main objective of Metacat are give below.Federated view of Metadata
Metacat can interact with most of the metadata stores to fetch and store the Metadata from different metadata stores and provide the user and clients an experience using a single metadata store.Unified API for Metadata
Metacat enables the user to fetch metadata from Hive, RDS, Teradata, Redshift, and this all can be done using a single Application Programming Interface. That is why it is termed as a unified API for Metadata.Interoperability
Multiple processing engines like Spark, Pig, Hive are used, and by applying an abstraction layer, the data can be accessed from any processing engine. They can be worked upon using the Metacat API. Metacat can also be used for data movement from one data warehouse to another.Data change auditing and notifications.
Metacat is the doorway to the different data stores, and the Metacat records any change in Metadata, and a notification is generated, which can be used is event driven architecture. The notification can be published to SNS (Simple Notification Service), and the system can react to the change in the Metadata.Hive metastore optimizations
The optimization of Hive Metastore backed with RDS (Amazon's Relational Database Service) was not good in reading and writing using megastore Application Programming Interface. Metacat eliminated this issue by improving the hive connector and establishing a direct connection between the hive connector and RDS.Data discovery
The user of the data can only use the data if they can access it and the main task in this is to search and browse the datasets easily. Metacat publishes the data to Elasticsearch, searching for information in data warehouses.Business and User-Defined Metadata
Business metadata stores connection information (for RDS data sources, for example), configuration information, metrics (Hive/S3 partitions and tables), and tables TTL (time-to-live). It can be further divided into logical and physical Metadata. Logical metadata provide information about the default values, validation rules, and logical construct like tables. In physical Metadata, the data about the actual data stored in the table or partition is there. User defined Metadata is stored according to the need of the user.
Conclusion
Schema and metadata versioning so that the changes in the Metadata can be audited and can be used to check how the Metadata looked at some point in time. It will also be useful for reprocessing and rollback. The business and user defined Metadata is not validated before storing as the Metadata is in the free form there is no credibility to the Metadata. To maintain the data's integrity, there need to be validation strategies before storing the Metadata.
- Discover here about API’s Latency Rate vs Response Rate
- Click to know about Contract Testing for Applications with Microservices


























