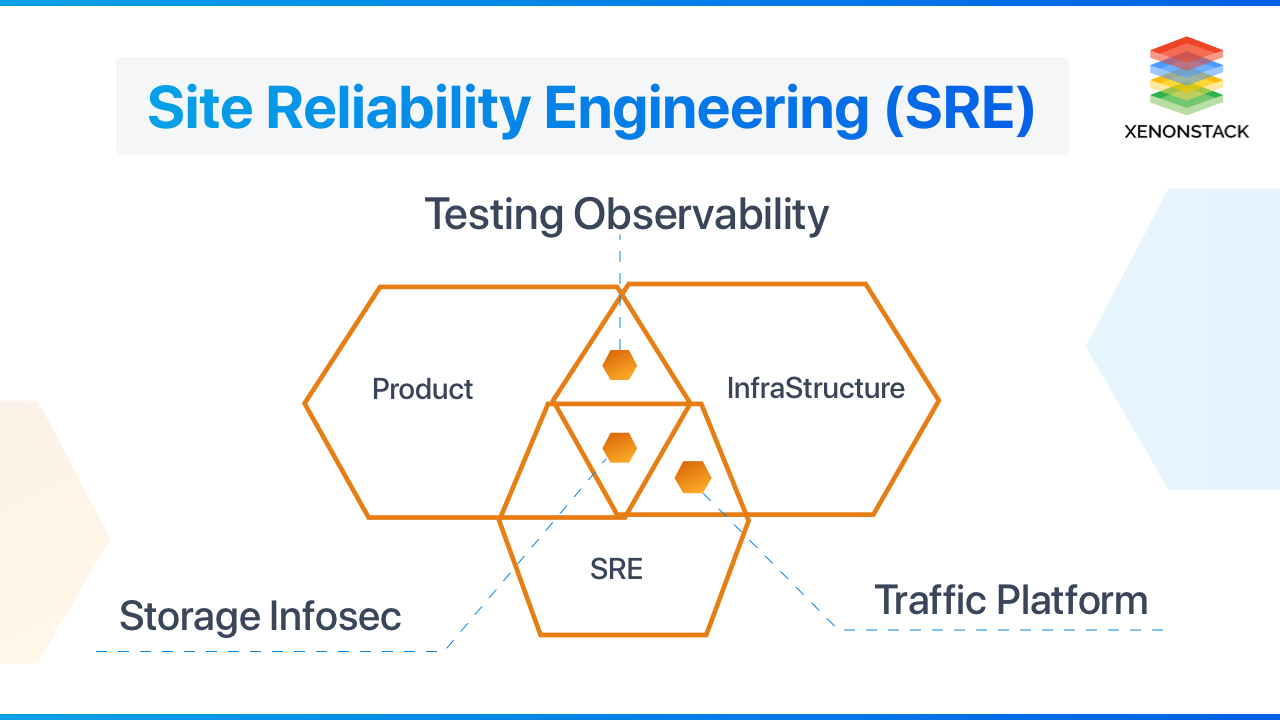
Introduction to Site Reliability Engineering
Managed SRE is a revolutionary approach to IT operations. The SRE team is responsible for resolving incidents, automating operational tasks, and using the software to manage systems. The most important responsibility is to maintain the reliability of systems, services, or applications. While operating it, the group has to undergo numerous challenges as well. In this document, I will discuss the solutions for some of the common challenges faced by the team.
SRE’s are typically a core group of professionals who have a wide array of skills. Click to explore about, Forbes
What are the key principles of Managed SRE?
Below are the 7 key principles of the Site Reliability Engineering team:-
- Embracing Risk
- Monitoring Distributed Systems
- Eliminating Toil
- Service Level Objectives
- Release Engineering
- Simplicity
- The Automation
Importance of Managed SRE
- Monitoring and improving the reliability of systems
Monitoring helps in the development of a business by saving time and money. Its team helps anticipate and alert the issues/situations that require attention/action.
- Troubleshooting escalation issues
The SRE teams deal with technical issues/incidents, take care of escalation cases and provide good customer support. The Site Reliability Engineering team aims to reduce critical incidents and manual work, allowing the IT support and development teams to concentrate on implementing new services and building new features.
Challenges in Implementing SRE
The main focus of the SRE team is to maintain the reliability of applications and servers and automate tasks to reduce manual work. The challenges that the SRE team faces while meeting its goals are described below :
- Monitoring and Alerting: Selecting the right tools for monitoring and configuring the correct metrics to monitor the servers and applications.
- Reliability: Maintaining the reliability of infrastructure and applications is another challenge that the team needs to overcome to meet the Service Level Expectations.
- Incident Management:
- Maintaining records of incidents.
- Defining policies and procedures for managing incidents inside the organization to be resolved quickly and without violating SLAs.
- Prioritizing Tickets: Prioritizing tickets based on their impact.
- Automating Manual Tasks: Stop wasting time with time-consuming and repetitive operations. Use the time you would have spent on repetitive manual tasks to automate because one of a company's most critical criteria is quick delivery with accuracy. For a more efficient workflow, SREs use automation tools to automate repetitive operations and releases.
- Debugging and Troubleshooting Skills: There must be an aspiration to be a "detective" and figure out why things work – or don't work as they should. Anyone who works with distributed computing systems needs to be able to troubleshoot.
These are some of the most common issues that need to be addressed for SRE to run smoothly.
SRE Team comprises the software engineers knowing sysadmin, which substitutes automation for human labor and focuses specifically on system reliability. Click to explore about, Site Reliability Engineering Best Practices
Solutions offered for the Managed SRE
Solutions for Managed SRE are below :
Monitoring and Alerting
One of the most challenging aspects of becoming a site reliability engineer is determining what to monitor and how to do it efficiently. Monitoring allows you to gain visibility into a system, which is critical for analyzing the health of your service and diagnosing problems. Monitoring tools help it to generate essential metrics and insights about an application and assist it with everything from benchmarking to diagnosing outages.
Implementing Google's four golden signals is a significant step to begin when developing a monitoring solution. Latency, traffic, errors, and saturation are the golden signals. The golden signals must be implemented correctly for observability to be achieved.
- Latency: The time it takes to service a request. It is a significant measure of the application's degeneration. Keep an eye on the latency of errors as well.
- Traffic: A measure of how much demand is being placed on your system.
- Errors: Errors are the rate of requests that fail. Other metrics, such as delay and saturation, might be influenced by error rates.
- Saturation: Saturation is how "full" your service is. To assess saturation, you'll need utilization measurements and the maximum flexibility possible.
The golden signals are ideal for monitoring cloud-based and on-premises applications that are delivered continually. The approach applies to any application. The team should have complete knowledge of the server or application they need to monitor, and based on this, and they should define required alerting policies based on Service Level Objectives. The alerts configured should be meaningful. The team should prioritize the alerts based on their impact on services.
A tool that enables end users, administrators and organizations to gauge and evaluate the performance of a given system. Click to explore about, Performance Monitoring Tools and Management
Incident Management
- Understanding of Logs: When there is a lack of information about an incident, it can be challenging to determine the cause, which takes a long time to resolve. To eliminate this problem, you can set up proper monitoring and alerting to generate meaningful logs, and corresponding metrics will provide the relevant information.
- Communication: Regular updates of internal staff allow for constant sharing of the truth about the incident. Suppose you do not establish a reliable source of truth about what happened and how it responded. In that case, people will tend to draw their conclusions, which creates confusion. Keeping external clients up to date is essential because it helps build trust. While they may be affected, at least they will know that the team is fixing it. You can use slack channels, status pages, or other tools as communication and alerting tools.
- Aware of Incident severity: If you were not aware of incident priorities, you would be wasting time on low-priority incidents instead of high-priority and major incidents. To resolve these conflicts, you can set priority levels for incidents based on their severity level, impact on other teams or applications, or client-side impact. You can automate this task of assigning high-priority problems that demand immediate attention while separating the low-priority incidents that can wait.
- Defined Process and Policies: Not having any plans or policies defined for managing incidents can lead to delayed response time due to a lack of contact information for stakeholders and employees and inappropriate escalation or the creation of new issues.
To overcome these kinds of issues, plan and create a process for managing incidents and ensuring that every stakeholder is aware of this process. There should be a proper workflow setup, from detecting an incident to resolving them. Every stakeholder or incident manager should have clarity about their roles and responsibilities. The team should have an adequate communication medium. - Documentation: Documenting the entire process for resolving major incidents helps the organization prepare for similar incidents in the future. With proper documentation of previous incidents, an organization can quickly deploy a tried-and-true solution in the case of a similar severe incident, minimizing the effect. You can create a postmortem report of the same, including every detail of the event or incident.
Enabling Team
- The team member should have the ability to troubleshoot and solve problems.
- The team should know to automate the manual tasks.
- The team should possess good communication skills.
- The team should be trained to understand the logs and identify the root cause of any incident.
- Enable teams to understand, manage and improve performance.
Automate Manual Tasks
There is great importance of automation in Site Reliability Engineering. It can reduce toil by replacing manual tasks with automation. Automating manual tasks saves time as automated workflows are quicker than manual responses. It streamlines the workflow to ensure that the code is deployed on time and within the error budget.
A methodology or an operating model that establish an Agile relationship between growth and IT operations. Click to explore about, DevOps and SRE on Google Cloud Platform
What are the best tools for SRE?
The best Site Reliability Engineering tools with their purposes are highlighted below:
For Monitoring and Observability
The SRE team works very closely with monitoring and observability tools. Metrics and logs play a very important role in maintaining the services and systems’ health. Based on these metrics and logs, the Site Reliability Engineering team can configure alerts. We recommend below some most popular and useful tools for the same. Some of them are open-source, while some are paid. You can choose anyone amongst them that meets your requirements.
- Prometheus and grafana
- ELF/EFK Stack
- Solarwind
- Appdynamics
- New Relic
- DataDog
- Zabbix
- PRTG Network Monitoring tools
- Nagios
On-Call Management tools
The on-call management tools assist you in evenly and fairly distributing on-call responsibilities among team members. Some popular and recommended tools for on-call management are :
- Atlassian’s Opsgenie
- PagerDuty
Communication Tools
Communication tools also play an essential role in it. The use of communication systems boosts response readiness significantly. Here are some recommendations for communication tools :
Incident Tracking tools
- Atlassian's Jira tool
- Trello
- Asana
- Zoho Sprints
Tickets Management Tools
- Service Now
- Jira Service Desk
- Fresh service
How SRE works with DevOps?
Google’s approach, it ensures organizations adopt DevOps principles better and measure implementations’ success. Site Reliability Engineering is an implementation of the DevOps paradigm. Just as continuous integration and delivery (CI/CD) are applications of DevOps principles to software release, it applies these same principles to software reliability.
Differences between SRE and DevOps?
|
Parameters |
Site Reliability Engineering |
DevOps |
|
Monitoring and Remediation |
It deals with the post-failure situation |
It deals with the pre-failure situation |
|
Role in SDLC |
It is concerned with efficient development and effective delivery of software system. |
It manages the IT operations efficiently once the application is deployed |
|
Speed & Cost of incremental change |
It includes rolling out new updates/features, faster release cycle, quicker deployment, and CI/CD. |
It includes instilling resilience and robustness in the new updates/features. |
|
Key measurements |
Its plan revolves around CI/CD |
It regulates IT operations with some specific parameters like Service Level Indicators (SLIs) and Service Level Objectives (SLOs) |
The ideas of DevOps and Site Reliability Engineering (SRE) have become extremely popular as a result of the widespread adoption of the cloud and the enormous scale of software operations. Align SRE with DevOps and transform ITOps.
Transforming Culture with Site Reliability Engineering
Site Reliability Engineering proclaims many advantages for distributed systems. It increases reliability, improves infrastructure automation, and transforms incident management. It often involves cultural transformation. It makes it possible for the organization to:
- Embrace Risk: The goal of it is not to have 100% reliable services. Site Reliability Engineering embraces the risk that systems will go down, followed by managing the risk. The measures taken to manage the risk allow the organization to deliver value.
- Reducing IT Dogma: Earlier, organizations relied on system administrators to run their systems and infrastructure. Repeated processes were executed one at a time with zero or little automation. Today’s organizations need pragmatic engineers who are willing to change processes and procedures and automate original problems for a better solution.
- Learning from failures: It encouraged to learn from failures by sharing failures publicly and with transparency. Getting into the failure and dissecting the cause of failure helps teams to resolve the issue.

Conclusion
Building an SRE team and implementing Site Reliability Engineering concepts and values within an organization is not easy. It's more about taking responsibility for production operations when you're in charge of it. It's a method that focuses on IT operations. As mentioned above, during building the SRE, the team will face a myriad of challenges. We've covered most of the main obstacles that teams experience in this document, and we've tried to present the best solutions that will help you avoid those problems and develop a successful team. Train your team, address challenges, and trust the process to implement SRE culture in your project or organization.
- Click here to talk to our Managed Services Expert
- Discover more about Best Practises and Solutions for SRE Team