Introduction to Recommender Systems
The main issue which is coming into the light of the modern world is the overloading of information which itself giving rise to the problem of navigation in the ocean of all real choices available online. Wontedly if we go to the market, there was a smart merchant in every shop who guide us through decisions after realizing the nature of the customer from his/her experience. Recommender Engines or we can recommender systems are doing the same for the online customers nowadays. It was all started with Tapestry, the first commercial recommender system, which was based on "collaborative filtering," and was designed to recommend documents drawn from newsgroups to a collection of users.
The strength of currently used recommender engines lies in recommending the products based on users’ buying habits as seen from their history. So, we can say recommender system are those smart merchants who can guide us through the ocean of all available online choices. Now we are going to discuss it and their generations with a brief introduction of the technologies involved in the functioning of a Recommender System.
An autonomous approach for making a knowledgeable and concise decision about the systems. Click to explore about our, Intelligent Decisioning System Tools
What is Recommender Systems?
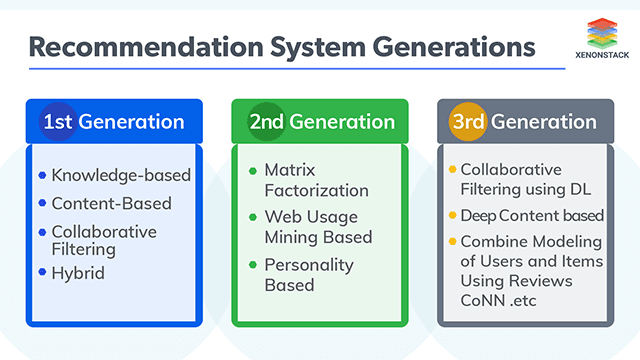
Recommender engines on e-commerce websites suggest new items to customers by collecting preferences of people based on explicit ratings of various products or on the analysis of behaviors of the users working within the system. It seems to be magic but it is purely data science based on the use of machine learning techniques. These engines are based on the interactions between users and items where users can be visitors, readers, customers etc. and app users on the other hand items can be products, articles, movies and events.First Generation of Recommender Systems
Till now we got the knowledge what the Recommender Systems are and what they can do, now it is the time to explore the type of traditional with their involved techniques.Knowledge-based
The knowledge exported in the forms of rules and patterns is the base of these type systems which will eventually use for recommendations. These systems process user-item attributes similarities to make recommendations. But these types of systems cannot handle the interactions made by the users in the past at all, which is a significant disadvantage of these type of systems?Content-Based
These systems recommend item based on the comparison of the analogy between the user's profile and content of the items which is based on reviews given to the item by the user. This analogy comes from the reviews or the feedback given to the item by the user. There are two ways by which a user can review an item first is by hitting like/dislike buttons or by rating an item which is known as explicit way of evaluating and second by viewing an item, by reading an article, by ordering a product, by adding an item to the cart and by purchasing that item which is known as implicit way of review.
However, to obtain the explicit type of review are hard to achieve. For this procedure, we can form an interaction matrix (between user and items) by using data related to items and users and for calculating similarities and analogies we can use the functions like cosine similarity and correlations. These systems are also known as Item based it The primary disadvantage of these systems is the lack of the capability in detecting inter dependencies between the different users or complex behaviors of the users.
Collaborative Filtering Based Recommender Systems
In this type, "user 's behavior" comes into the play. In this we attainment the behavior of other users and items regarding rating, transaction history, purchase, and selection information by the help of which we recommend items to the new users. So primarily in this procedure, we make recommendations by using the mapping between new users and existing users and this mapping is done by items. This mapping can be done by using neighborhood approach. For implementing neighborhood approach, we can use KNN (K- nearest neighbor) and APRIORI. KNN is not costly to train but take time to recall that is why they are also known as lazy learners.
Again, similarity is calculated by using cosine similarity and correlations functions. The final to take the arithmetic mean of these similarities and on these similarities, we recommend items to the new users. The main disadvantages of these types of recommender are the cold start (take time to make recommendations to the new user as they do not have their rating registered) and Gray sheep (lack of recommending beneficial information as the user does not have any curiosity to pursue a distinguished group).
Hybrid Recommender Systems
These types the most popular systems nowadays as it is used to overcome the disadvantages of all above techniques. By the word 'Hybrid' we not only mean the hybridization of the techniques, but it also refers to hybridizing the features related to the users such as combines users’ history and the personal behavior which is the base idea of building PBRS (Personality Based Recommender Systems). In this type, we can jointly use qualities of above techniques. One of the most recent examples of using Hybrid methodology is the technique used by Facebook known as rotational hybrid approach with apache giraffe a robust platform for distributed iterative and graph processing.A part of Geospatial data that helps in the collection, storage, manipulation, analyzation, and present spatial data. Click to explore about our, Geospatial Analytics using Presto and Hive
Second Generation of Recommender Systems
Before diving into the semantics of the topics, let us allow to discuss some techniques which can be considered as the important part of the topic.Matrix Factorization Based Approach
This approach is based on latent factors, and latent factors are variable which are used to relate the content or the item with the genre of the items. Neural Networks based models are also the type which is based on latent factors. In Matrix factorization methods the predictions are made from analogy between user and item factors. It is highly lean on the matrix formed by the input data in which the user represents one dimension and items represents another. It starts by outlining the items and the users into a combined latent factor space. The interactions between the users and the items are shaped in terms of the intrinsic product in that space. Evaluating The vector which is correlated with the item i and calculating the amount which acquire those factors.
The vector which is correlated with the user u and calculate the amount of the interest of the user in the items. Now if we have to determine that how much user u is interested in item i, we can calculate rating by evaluating the dot products. This is how we can calculate recommendation scores on the basis of these dot products which can be further used for the predictions. So, here basic idea is (as the name suggests) we have to factorize a matrix into two vectors which can given us latent factors and on the basis of which predictions are made. The main intuition of this whole process is to discover how a user is rating a particular item and in this method the answer is latent factors which gives us the idea about the genre of the item or a article on the basis of which a user is rating that article.
WUM (Web Usage Mining) Based
The procedure of exporting knowledge from the data accessed by the different users on the Web with the help of data science technologies is known as Web Usage Mining (WUM) which is used for accomplishing different objectives such as modification of the website, Improving the system and personalization. The whole procedure takes place concerning off-line component and online component taking into consideration the Web server activity. The task of the off-line element is to frame the knowledge database by estimating the previously existing data, after that the online component use this data.
There are some these are implemented by using this approach one of them is SUGGEST 3.0 (by Ranieri Baraglia and Fabrizio Silvestri). SUGGEST 3.0 (which is the upgraded version of SUGGEST 2.0 and SUGGEST 1.0) is a recommender engine which accomplishes the task of giving helpful data about the pages which are in the interest of a user. It produces the links of the websites which are not visited by a user until now and might be related to the possible interest of the user in a real-time manner. This recommender system is capable of administering Websites which are fabricated of pages in real time scenario without using any offline element.
What is PBRS (Personality Based Recommender Systems)?
PBRS, a hybrid recommender system, which uses both Customers’ buying patterns and their personality as the base for effective recommendations. In this way, it creates a bridge between the automatic personality classifier and data mined from shopping history of a user. We believe that this approach has the potential to alleviate the problem of users’ distraction by ensuring and thus leads to the increase in sales on the portal. So, how we can estimate the personality of a user. There are two ways of evaluating the character of a user: First is by asking the user to fill out a questionnaire related to the personality which can give us the estimate of nature, but this method has a significant issue which is what is one user does not provide a correct answer or what if any user does not fulfil the questionnaire completely, it will be strenuous to deal with these missing values so there is another way which is doing estimation of the personality of the user by analyzing the data which is openly obtainable online.
TWIN (Tell Me what I need): It is a personality-based recommender system which is based on the second way of estimation which is implemented by Alexandra Roshchina. A Sustainable amount of work has already been accomplished in the orbit of psychology to obtain the exact features from the text to construct a personality map in betwixt the personality and the writing of the user. The whole system is based on those findings only. To Compose the personality, the text from the users is used which is further used to analysis nature by the style of writing. It is based on the hybrid methodology of constructing a recommender system which follows the hybridizing of the content-based and collaborative filtering-based approaches. So, in simple words, this system makes predictions on "sameness" betwixt people and this "sameness" is constructed by analyzing the lexicon of the words used by the users.
RPA in ERP Systems helps businesses make these time-consuming projects less costly and less labor concentrated. Click to explore about our, Implementing RPA in ERP for Systems Transformation
Third Generation of Recommender Systems
It was all started in 1958 when a psychologist named as Frank Rosenblatt tried to build something artificial but can reciprocate like the Human brain which was designated as perceptron, an artificial machine which can memorize, think and counter like the Human brain. In 2016, one of the best players in a game named as GO was defeated by a computer program. Yes, it is true, Lee Sedol (one of the strongest player in GO) was defeated by AlphaGo (a computer program developed by "Google DeepMind"). This tells us the power of Deep learning in the area of Artificial Intelligence. That's why the Third Generation of Recommender System is related to the emergence of Deep learning in the field of it.What is Deep Learning?
Deep Learning is a subfield of Machine Learning (which is again a subfield of Artificial Intelligence) which is galvanized by the functioning of the human brain, has composite engineering and used for the imitation of the data. Neural Network acts as the elementary bricks of Deep Learning. A Neural Network is an artificial model of the Human Brain network which is modeled using hardware and/or Software. There are many types of Neural Network which are used in Deep Learning. Some of them are Multilayer Perceptron (Simplest ones), Convolutional Neural Network (mainly used in the field of digital image processing), Recurrent neural network (used primarily for continuous data).
Multilayer Perceptron (the oldest one in the family of Neuron Network) is a network build by some clandestine layers of neurons where a layer uses the output of its previous layer as input. Convolution Neural Networks (made known by Lecun), which reformed digital image processing and provided a solution to the problems of physical abstraction of the features. They are successfully used for classification and segmentation of Image and used for the other operations also such as Face recognition and Object recognition. The simplest Recurrent Neural Networks came into existence in the 1980s. Recurrent Neural Networks which is used primarily for continuous data such as time series. Why deep learning should be used Recommender Systems? Firstly, it gives an edge to the feature abstraction process as we can do the process of abstraction directly from the content (Images, Music, Videos). Secondly, it can handle mixed data comfortably, Thirdly, Deep Learning can provide real time behavior to the model.
Restricted Boltzmann Machines and Collaborative Filtering
Restricted Boltzmann Machines were invented by Paul Smolensky in 1986 under the name of Harmonium. This model is consisting of two layers. The working starts with estimating some conditions; We have ratings in a range of 1 to x from U users on I items. Now suppose every user rated every item, now users can be passed down as a training example for an RBM. Now here comes a problem if some of the ratings are absent as one user did not rate some items which will create missing values. But we can deal with this problem by using a different RBM for each user. Till here it is clear that one RBM has clear rating units for the items rated by the reciprocal user it further means if the user rated only a few things then their RBM has a minority of connections. It gives results to a conclusion, let us suppose we have two users Mr.Y and Mr.X and they already rated item likewise then their RBMs contribute to the weights associated to the reciprocal visible units.
So, this is how RBMs can be used with collaborative filtering methodology for building a Model. For learning process, the log-likelihood is maximized with the help of the employment of gradient ascent. Predictions can be made firstly by calculating the states of its hidden units and after that by calculating the expected value of predicting an item. The disadvantage of this model is that it does not use information related to the content for example texts related to the reviews and the profile of the users which results that it lacks while dealing with the cold start problem.
Collaborative Filtering using Deep Learning(CFDL)
Collaborative Filtering using Deep Learning(CFDL) is a robust approach to tackle the cold start problem as it can use content information (texts related to the reviews, the profile of the users, etc.). The latent factors of items are learned from the content information related to the reviews by accommodating the Collaborative Topic Regression (CTR) and Stack Denoise Auto-Encoder (SDAE). Let's briefly talk about this procedure. When we speak about CFDL, the learning procedure from the items' reviews is done by using bag-of-words strategy as it is used to impersonate its reviews in the form of a matrix. The K items are served by K*L matrix Mc. This matrix contains vectors in the form of bag-of-words which then used to learn latent factors related to the items by fueling these vectors into SDAE network.
Synchronously, on the other hand, the latent factors associated with a user (Ui) are used to form a Gaussian distribution which then applied with a different Gaussian distribution to predict the ratings. If we talk about training this model (CFDL), for this task we have to sharpen mainly two parameters these are latent factors and the parameters of the network. The outputs of the middle layers are obtained as latent factors, so it acts as a link between rating modeling and the whole network. Then the log likelihood of CFDL is derived by using some hyperparameters which can be maximized by using an EM style algorithm. The main disadvantage is that the ignorance of "ordering of words" in the applications of text modeling where it has high relevance.
Deep Content-based Recommendation Systems
This type of system mainly used to recommend music. If we have to build a recommender system for a music-oriented website or app then we have to face two problems: First and the most common one is the cold start problem and second is that a music-oriented web page or app provides reviews in the implicit form. There is a universal fact (if we talk about recommending items in case of music system) that a recommender system should recommend anonymous articles. But the problem is as we already mentioned that user hardly provides explicit feedback and mainly gives an implicit type of feedback which gives rise to a different framework as compare to traditional matrix factorization.
So here we use a mutated matrix factorization which is Weighted Matrix Factorization. It is a framework which is used for the datasets which contain the Implicit type of reviews. But what about the latent factors which we have to extract from the music so for this purpose a deep CNN model is used and CNN is a supervised learning type deep model, these latent factors (which are learned by using WMF) are used to train CNN. This trained CNN is used to minimize the square error betwixt the latent factors related to the items and the output vector. The main disadvantage of this system is that it cannot utilize Metadata.
Combine Modeling of Users and Items Using Reviews using CoNN
If we talk about using users and items (in the context of texts related to the review) combined for predicting ratings then for that purpose Cooperative Neural Network (CoNN) can be used. The primary purpose of this network is to learn complex latent factors related to items and the users combined which can be achieved by applying two neural networks to maximize the accuracy of predicting ratings. First network portrait nature of the user through the texts written in the reviews by the users. The work of the second model is to portrait properties of the items using the texts written in the context of the items.
The procedure of predicting comparable rating is accomplished by using learned latent features related to the users and items and these rating then imported on the layer, and this layer is placed on the above of both networks. After that optimization procedure takes place which is accomplished by using Stochastic gradient descent. This model cannot operate with those articles and users which do not have ratings associated with them which became a disadvantage for this model.
Product Based Recommender System
Considering the above content, we have described the theoretical approaches which can be used as the backbone while building a recommender system, but if we have to approach for making a recommender system which is moreover a production based (e.g. YouTube Recommender System) then we have to keep few things in our mind; first, it should be strictly dynamic and second, we have to emphasize three things -
- Scale - We should keep in our mind that now we have to deal with the data on a large scale. Many systems can deal with a specific amount of data, but here we are not talking about dealing with the mouse here we are talking about dealing with the elephant.
- Freshness - Nowadays the data we have to deal with is very dynamic as we are generating very speedily. So, while building a production-based recommender system we have to keep in mind that it should be dynamic (as much as possible) so that it could maintain the "Freshness".
- Noise - Lots of data means lots of metadata and lots of metadata means lots of noise because, as we know usually metadata contains poorly methodized data that is why it is essential that a production-based recommender system should be stringent against these types of noise. These all cannot be achieved by just developing a single model. The model should be divided into parts: Front end, Data transport model, Storage, Serving, Online training model, Offline training model.
Firstly, the user has to interact with some service whether it a webpage or apps where we can import the data from the user by which we can make recommendations. For this fulfilling, this purpose "Front End" comes into the play. Then we have to transport this data which we have imported from the users for this purpose we use "Data transport model". This data then stored with the help of "Storage" model which can be used further used for making predictions to recommend items.
Now comes the training part: Offline part and Online part. The elementary training mechanism where machine learning comes into the play considering recommendation algorithm is Offline training part. It includes training a model by the help generally used data science techniques. But here we can also use deep learning models of learning. Talking about the online part, this part has the responsibility to refresh the batch with an updated image of it as the flow of the data is dynamic. We can use an algorithm which should be dynamic and support the implementation of deep learning such as ALS (Alternating least Square) which is a based-on matrix factorization approach. Last but not the least, the serving part, deployment of the model which is providing the recommendations to the customer. This relies on the trained model's output. The recommender system is not only about recommending ace stuff moreover it is about making it adaptive, making it dynamic, making it tough. We should emphasize more maintaining the simplicity while choosing an algorithm.
The analysis and performing different types of aggregate functions over real-time data, and the continuous query is used for the same. Click to explore about our, Implementing Stream Analytics Systems with Cloud
Concluding Recommender Systems
Now let us give our attention to the vital statistics and recommender systems technologies of big giant companies of nowadays. LinkedIn is using appropriate collaborative filtering which is implemented with Apache Hadoop. Amazon patented its recommendation technique, known as the item to item collaborative filtering. Their technology recommends items to the user by a specific item purchased by other users, and this particular item is also purchased by the user recently. The percentage of sales come from this recommendation is 35%. The item-based collaborative approach with Hadoop is also used by Hulu (a video searching platform) which increased their CTR (Click through rate) by three times. The 2/3 of the movies watched by a user on the Netflix come as recommendations to the users by the Recommendation Systems. CTR (Click through rate) of news recommendation at Google is increased up to 38 % by the use of Recommender System. From above we can conclude that how vital recommender systems are for the world which is in the middle of the age of the Internet. As this world is evaluating day by day, a whole new evolution is also required in the area of recommender system which is already started by introducing deep learning in this field. However, this introduction process is in its early stage, but there is more to explore, more to try and more to implement.To understand more about recommendation we advise taking the following steps -- Learn more About Developing Product Recommendation System
- Get an Insight about Building Recommendation Systems with ML


